




前言

现在,我们将讨论由数据类型转换引起的问题。在 PostgreSQL中,我们将创建两个表,其中一个表具有 number类型的字段,另一个表具有 double precision类型的字段。让我们把两个表关联查询,看看会发生什么。
数据类型转换问题
首先来创建两张表,同时插入数据。
create table t1 (id numeric,name text);
create table t2 (id double precision,name text);
insert into t1 select generate_series(1,10000000),md5(random()::text);
insert into t2 select generate_series(9999900,20000000),md5(random()::text);
create index idx_t1 on t1(id);
create index idx_t2 on t2(id);
vacuum t1;
vacuum t2;
analyze t1;
analyze t2;
下一步,我们将两个表进行关联。

显然,t1和t2表都进行了全表扫描,最后再执行的hash join操作。而如果我们把t2的字段改成numeric的话。

idx_t1和idx_t2索引现在可以使用了,最后才是Merge join关联,这将大大提高效率。
我们在来观察一下Oracle数据库,因为我的 Oracle环境容量有限,这里造的数据少一些,但不会影响我们的测试。
create table t3 (id numeric,name varchar2(255));
create table t4 (id double precision,name varchar2(255));
insert into t3 select rownum as id, dbms_random.string('x', 10) random_string from dual connect by level <= 100000;
insert into t4 select * from (select rownum as id, dbms_random.string('x', 10) random_string from dual connect by level <= 200000 ) where id > 97000
create index idx_t3 on t3(id);
create index idx_t4 on t4(id);
exec DBMS_STATS.GATHER_TABLE_STATS
(ownname=>'SYS',tabname=>'T3',estimate_percent=>100,no_invalidate=>false,cascade=>true,degree => 10);
exec DBMS_STATS.GATHER_TABLE_STATS
(ownname=>'SYS',tabname=>'T4',estimate_percent=>100,no_invalidate=>false,cascade=>true,degree => 10);
再一次执行查询,会发现 Oracle默认走 index fast full scan。
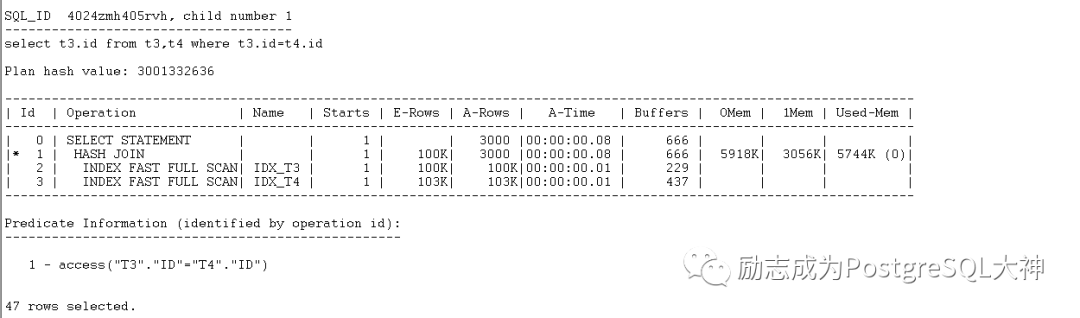
Oracle自动处理同类数据类型转换的问题, PostgreSQL不处理这种问题,PostgreSQL是强一致类型,不匹配就无法使用到索引。
后记
这类问题,需要我们再迁移过程中小心谨慎的进行测试才能防止不出问题啊。
文章转载自励志成为PostgreSQL大神,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
