




前言
今天我们要探讨的技术是 custom执行计划和通用执行计划。这一技术在 Oracle中被称为绑定变量窥视。但 PostgreSQL中并没有这样的定义,更严格地说,PostgreSQL叫custom执行计划和通用执行计划。
Custom执行计划和通用执行计划
为说明其原理,我们先来看一个例子,我创建了一个1000011行的表,其中有两列分别为 id、 name。在name列就2种类型的值,一种值为“aaa”,有整整1000000行,而值为bbb数据的仅有11行。因此在name字段上出现严重的倾斜。
create table a(id numeric,name varchar(40));
insert into a select i, 'aaa' from generate_series (1,1000000) i;
insert into a select i, 'bbb' from generate_series (1000001,1000011) i;
create index idx_a1 on a(name);
analyze a;复制
下一步是使用 PostgreSQL附带的 prepare语句。利用该方法可以避免对语句反复解析。。
postgres=# prepare test_stmt as select * from a where name = $1;
PREPARE复制
我们执行语句检查name字段,连续6次都查询name为'aaa'的数据。
postgres=# explain (analyze) execute test_stmt ('aaa');
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Seq Scan on a (cost=0.00..17906.14 rows=1000011 width=10) (actual time=0.014..168.739 rows=1000000 loops=1)
Filter: ((name)::text = 'aaa'::text)
Rows Removed by Filter: 11
Planning Time: 0.446 ms
Execution Time: 227.976 ms
(5 rows)
postgres=# explain (analyze) execute test_stmt ('aaa');
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Seq Scan on a (cost=0.00..17906.14 rows=1000011 width=10) (actual time=0.008..167.778 rows=1000000 loops=1)
Filter: ((name)::text = 'aaa'::text)
Rows Removed by Filter: 11
Planning Time: 0.084 ms
Execution Time: 226.949 ms
(5 rows)
postgres=# explain (analyze) execute test_stmt ('aaa');
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Seq Scan on a (cost=0.00..17906.14 rows=1000011 width=10) (actual time=0.011..167.848 rows=1000000 loops=1)
Filter: ((name)::text = 'aaa'::text)
Rows Removed by Filter: 11
Planning Time: 0.111 ms
Execution Time: 227.192 ms
(5 rows)
postgres=# explain (analyze) execute test_stmt ('aaa');
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Seq Scan on a (cost=0.00..17906.14 rows=1000011 width=10) (actual time=0.011..168.297 rows=1000000 loops=1)
Filter: ((name)::text = 'aaa'::text)
Rows Removed by Filter: 11
Planning Time: 0.169 ms
Execution Time: 227.554 ms
(5 rows)
postgres=# explain (analyze) execute test_stmt ('aaa');
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Seq Scan on a (cost=0.00..17906.14 rows=1000011 width=10) (actual time=0.011..168.193 rows=1000000 loops=1)
Filter: ((name)::text = 'aaa'::text)
Rows Removed by Filter: 11
Planning Time: 0.186 ms
Execution Time: 227.425 ms
(5 rows)
postgres=# explain (analyze) execute test_stmt ('aaa');
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Seq Scan on a (cost=0.00..17906.14 rows=1000011 width=10) (actual time=0.009..174.390 rows=1000000 loops=1)
Filter: ((name)::text = $1)
Rows Removed by Filter: 11
Planning Time: 0.111 ms
Execution Time: 233.410 ms
(5 rows)复制
由于 aaa占用了该表的大部分数据,因此优化器选择使用全表扫描。在第六次的时候,请注意 Filter部分,(name)::text = 'aaa'::text变为 text=$1。此时优化器将生成通用执行计划,并使用绑定变量。之前的5次则被称为 custom执行计划。为什么是5次?我们可以在 PostgreSQL的 plancache. c源码中找到说明。
❝The logic for choosing generic or custom plans is in choose_custom_plan
❞
在代码的前面有一个注释,选择通用计划或者custom计划的逻辑是在choose_custom_plan函数中。
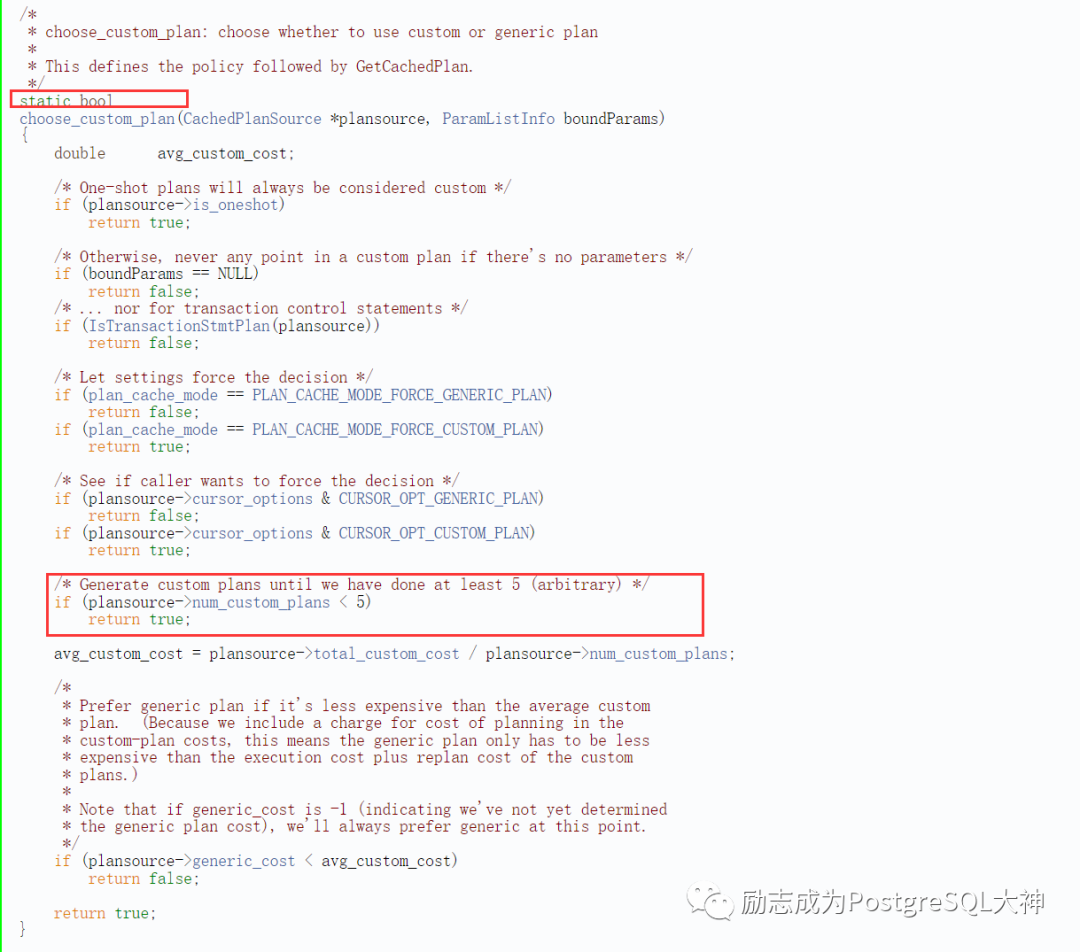
请注意,这里的限定值小于5次,返回 true,选择 custom执行计划,而大于5次之后,则选择通用执行计划。因此,5次之后执行计划就会固定。现在即使您传递的是倾斜值,它也只能走全表扫描。
postgres=# select count(1) from a where name='bbb';
count
-------
11
(1 row)
postgres=# explain (analyze) execute test_stmt ('bbb');
QUERY PLAN
-----------------------------------------------------------------------------------------------------------
Seq Scan on a (cost=0.00..17906.14 rows=1000011 width=10) (actual time=114.950..114.953 rows=11 loops=1)
Filter: ((name)::text = $1)
Rows Removed by Filter: 1000000
Planning Time: 0.019 ms
Execution Time: 114.974 ms
(5 rows)复制
本质上,这一效果与 Oracle打开绑定变量窥视的效果相同。那我们有什么办法来控制吗?再看看源代码,在源代码中可以返回 true有几个条件。其中之一是plan_cache_mode参数,该参数是PostgreSQL 12才有的,我们将它设为force_custom_plan。告知优化器我们将永远使用硬解析。
postgres=# set plan_cache_mode=force_custom_plan;
SET
postgres=# explain (analyze) execute test_stmt ('bbb');
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Index Scan using idx_a1 on a (cost=0.42..4.44 rows=1 width=10) (actual time=0.047..0.052 rows=11 loops=1)
Index Cond: ((name)::text = 'bbb'::text)
Planning Time: 0.131 ms
Execution Time: 0.071 ms
(4 rows)
postgres=# explain (analyze) execute test_stmt ('aaa');
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Seq Scan on a (cost=0.00..17906.14 rows=1000011 width=10) (actual time=0.009..175.913 rows=1000000 loops=1)
Filter: ((name)::text = 'aaa'::text)
Rows Removed by Filter: 11
Planning Time: 0.086 ms
Execution Time: 234.867 ms
(5 rows)复制
在设置参数之后,此时查询 bbb会使用索引,对 aaa则进行全表扫描。另一种方法与服务器编程相关,它要求在SPI_prepare_cursor中设置 cursorOptions选项为CURSOR_OPT_CUSTOM_PLAN。这个使用的人很少,几乎找不到相关资料。
后记
那么,今天的主题就到此结束,我们来总结一下。基于源代码的定义,我们可以得出以下结论:
在执行SQL时,在小于5次的情况下,默认使用硬解析产生custom计划,而这5次计划非常关键,如果列分布均匀而无倾斜,则将生成稳定的执行计划。而在5次之后,就会把执行计划固化起来,使用绑定变量的形式,减少硬解析,此时就不会有问题了。而在列分布不均的情况下,当第六次生成通用计划时,当绑定变量输入倾斜值的时候就会出现使用错误执行计划的情况。。
所以想一想,5次是不是少了一点,少了可以把值变大一点然后重新编译软件,当然也可以考虑把这个值做成变量来控制。不知道为啥官方不这么做呢?




