




前言
上期文章介绍了pg_dumpfile使用方法。有一个问题是这样的:「如果出现异常宕机,并且不能知道表的relfilenode和列的名字,列的类型,那么如何获得数据?」
数据字典
要解决这一问题,首先要从数据字典中挖掘出信息。主要有三张数据字典表,pg_class,pg_attribute,pg_type。在pg_class中可以找到对象的relfilenode,在pg_attribute中可以得到字段名,在pg_type中可以得到字段的类型。

首先,我们来正向查一下。这里创建一个t3表。
create table t3 (id int,name varchar,birth timestamp,description text);
insert into t3 values(1,'aaa',now(),'我爱中国');
insert into t3 values(2,'bbb',now(),'postgresql recover');
postgres=# \d t3
Table "public.t3"
Column | Type | Collation | Nullable | Default
-------------+-----------------------------+-----------+----------+---------
id | integer | | |
name | character varying | | |
birth | timestamp without time zone | | |
description | text
我们在pg_class中查到其relfilenode。
postgres=# select relfilenode from pg_class where relname='t3';
relfilenode
-------------
164127
我们在pg_attribute中查找其字段。在此请注意pg_attribute需要知道表的oid。
postgres=# select attnum,attname from pg_attribute where attrelid in (select oid from pg_class where relname='t3') and attnum >0;
attnum | attname
--------+-------------
1 | id
2 | name
3 | birth
4 | description
(4 rows)
下一步,我们将从pg_type中检查字段的类型。
postgres=# SELECT pg_attribute.attname, pg_type.typname , pg_attribute.attnum
postgres-# FROM pg_class, pg_attribute, pg_type
postgres-# WHERE pg_class.oid = pg_attribute.attrelid
postgres-# AND pg_attribute.atttypid = pg_type.oid AND pg_class.relname ='t3' AND pg_attribute.attnum > 0
postgres-# ORDER BY pg_attribute.attnum ;
attname | typname | attnum
-------------+-----------+--------
id | int4 | 1
name | varchar | 2
birth | timestamp | 3
description | text | 4
挖掘数据字典
1.从pg_class中挖掘relfilenode。
下一步我们要做的是挖掘数据字典。首先我们需要知道pg_class位于哪个文件,通过pg_class. h源代码可以找到是1259文件。
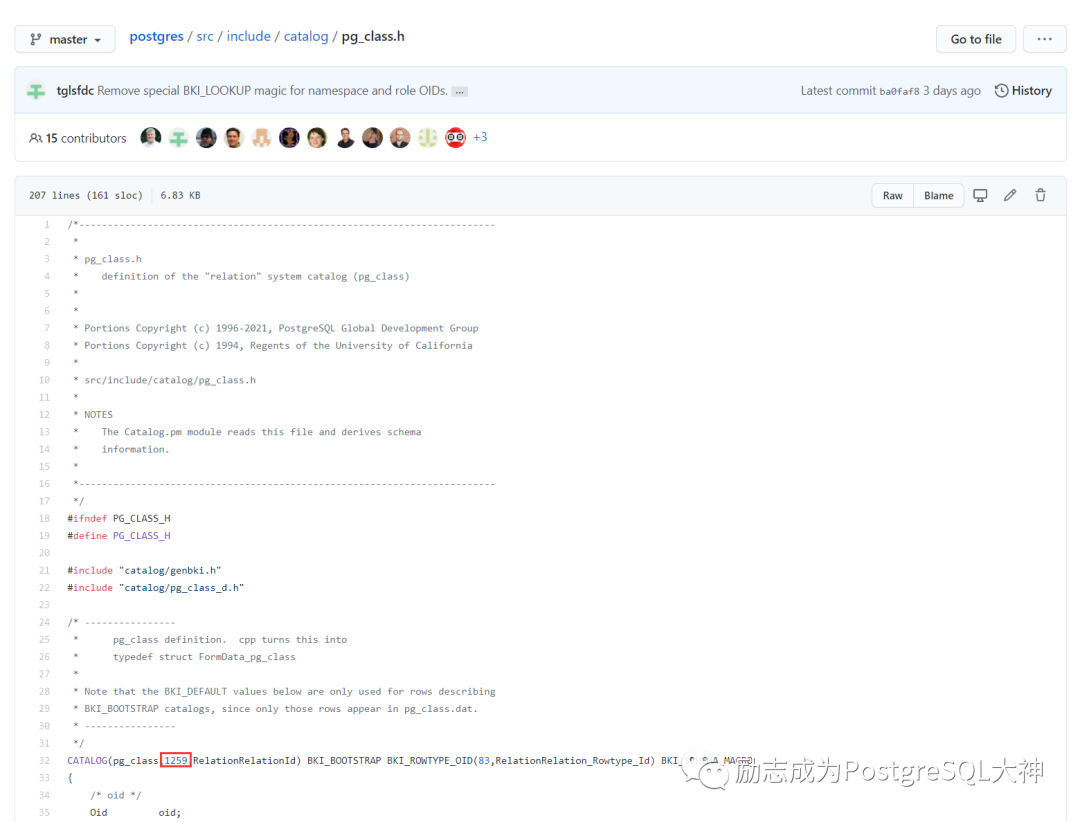
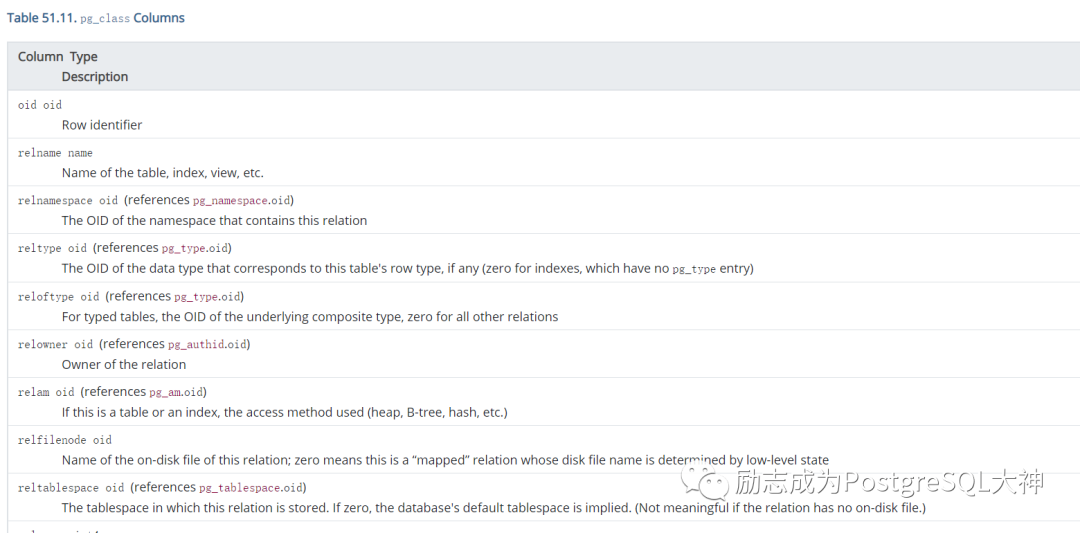
接着我们要挖掘的相关字段信息,因为pg_class表中的字段比较多,所以我们根据官方文档挖掘前几个字段。
[postgres@centos8 pgdata]$ pg_filedump -D oid,name,oid,oid,oid,oid,oid,oid,~ ./base/12711/1259 | grep t3
COPY: 164127 t3 2200 164129 0 10 2 164127
COPY: 164127 t3 2200 164129 0 10 2 164127
请注意,第八列是relfilenode,这里得到的结果是164127。其 oid也是164127。
2.从pg_attribute中挖掘字段名称。
如上所示,我们知道了表的 oid,实际上可以轻松地从pg_attribute挖掘出字段信息。在挖掘之前还需要先知道pg_attribute是哪个文件。

通过pg_attribute.h源代码可以发现是1249文件。
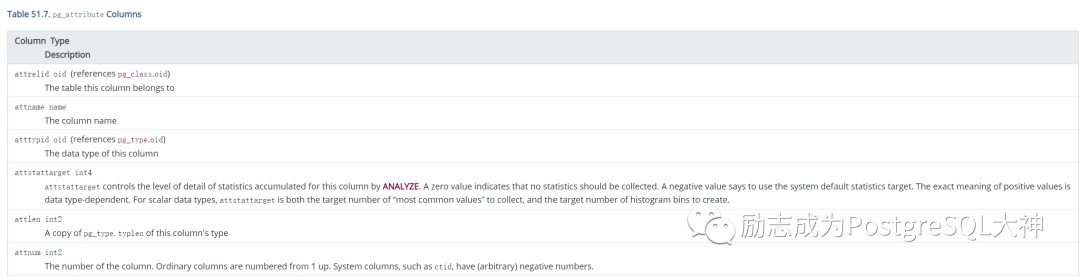
我们只用挖掘前面6个字段的信息。
[postgres@centos8 pgdata]$ pg_filedump -D oid,name,oid,int,smallint,smallint,~ ./base/12711/1249 | grep 164127
COPY: 164127 id 23 -1 4 1
COPY: 164127 name 1043 -1 -1 2
COPY: 164127 birth 1114 -1 8 3
COPY: 164127 description 25 -1 -1 4
COPY: 164127 ctid 27 0 6 -1
COPY: 164127 xmin 28 0 4 -2
COPY: 164127 cmin 29 0 4 -3
COPY: 164127 xmax 28 0 4 -4
COPY: 164127 cmax 29 0 4 -5
COPY: 164127 tableoid 26 0 4 -6
在这里,我们挖掘了T3表所有字段的名称和atttytpid (代表pg_type的oid,后面的挖掘pg_type的时候需要使用),最后一列attnum是字段的次序,注意这里有一些隐藏字段,只要attnum列显示是负数,它就是隐藏字段,这里不用管隐藏字段的值。
3.从pg_type中挖掘出字段类型
先看一下pg_type是哪个文件?
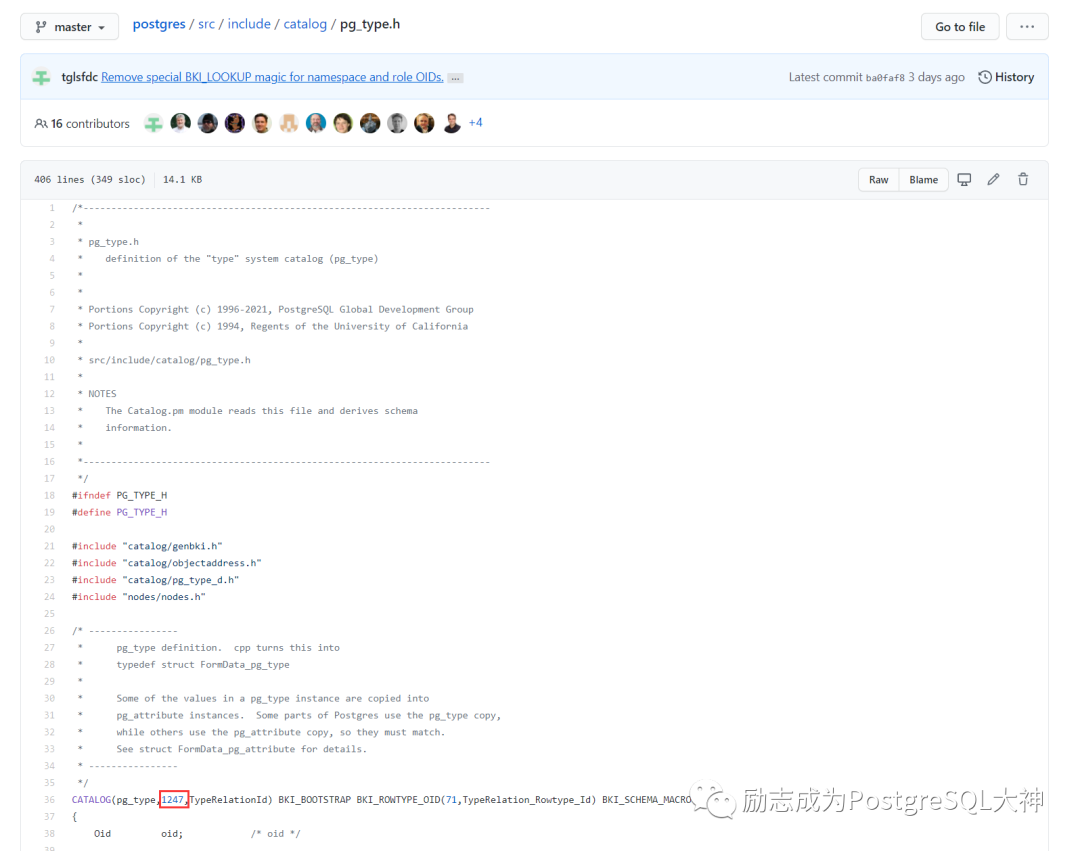
通过pg_type.h源代码可以发现是1247文件。

我们只用挖掘pg_type前面2个字段。
[postgres@centos8 pgdata]$ pg_filedump -D oid,name,~ ./base/12711/1247| egrep -i 'COPY: (23|1043|1114|25)'
COPY: 23 int4
COPY: 25 text
COPY: 1043 varchar
COPY: 1114 timestamp
此时,我们挖掘出了整个表的信息。其中包括表的relfilenode、表中字段名和字段类型。这就解决了我们之前提出的问题:「如果不知道表的relfilenode和字段名称、字段类型,如何获得表中的数据?」
后记
好了,本文到此结束,看到这里,你是不是也跃跃欲试?想自己亲手尝试一下呢?
