





前言
wal文件名字看不懂,有什么规律吗?
WAL文件命名规则
与其他数据库系统相比,PostgreSQL的WAL文件命名实在是让人摸不着头脑,比如我系统中的显示, wal文件名字很长。
[postgres@freebsd-test /app/pgdata/pg_wal]$ ls -lrt
total 91
-rw------- 1 postgres postgres 16777216 Mar 3 06:15 000000010000000000000009
-rw------- 1 postgres postgres 16777216 Mar 3 06:19 00000001000000000000000A
-rw------- 1 postgres postgres 16777216 Mar 4 06:16 000000010000000000000006
-rw------- 1 postgres postgres 16777216 Mar 4 06:18 000000010000000000000007
drwx------ 2 postgres postgres 4 Mar 4 06:18 archive_status
-rw------- 1 postgres postgres 16777216 Mar 4 06:24 000000010000000000000008
有没有关于WAL文件命名的规则?确实它有规则。下面的图来自
https://www.slideshare.net/loxodata/dig-thewal-pgconfeu2018
WAL的名称由三部分组成,每个部分代表8个数字。首先是TimeLine ID,从1开始。第二部分是逻辑文件ID,从0开始。第3部分是物理文件ID,从00开始,直到 FF,周而复始的循环。
TimeLine ID
首先是:TimeLine ID。也叫时间轴,当initdb创建数据库集群后,这个数字是1,而且不会改变。但每次恢复时, TimeLine ID都会+1。你可以从 Hironobu SUZUKI
大神的 PostgreSQL内部原理中的网站中查看下图。
(https://www.interdb.jp/pg/pgsql10.html#_10.3.1.)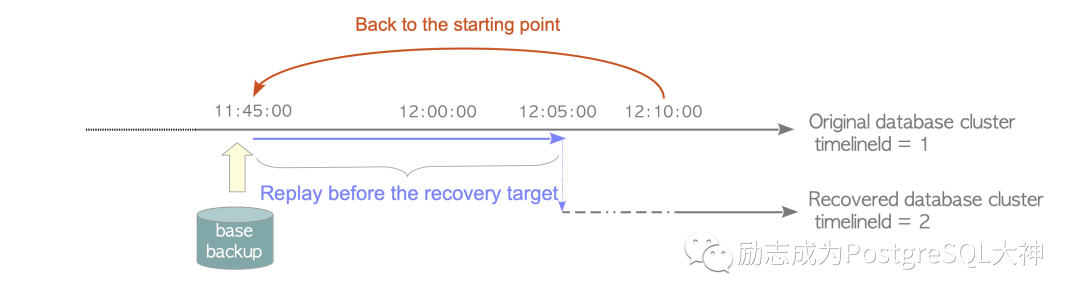 在这个图中,我们可以看到这样的事情:首先看一下红色的路径,当数据库需要恢复时,它首先删除当前的数据库,然后将备份恢复到11:45,然后开始追WAL文件以进行恢复,直到12:05为止。在根据时间点恢复到目标点位后,它会将TimeLine ID修改,提供给新的数据库使用,使恢复的数据库在时间轴2上运行。此时TimeLine ID将变为00000002。
在这个图中,我们可以看到这样的事情:首先看一下红色的路径,当数据库需要恢复时,它首先删除当前的数据库,然后将备份恢复到11:45,然后开始追WAL文件以进行恢复,直到12:05为止。在根据时间点恢复到目标点位后,它会将TimeLine ID修改,提供给新的数据库使用,使恢复的数据库在时间轴2上运行。此时TimeLine ID将变为00000002。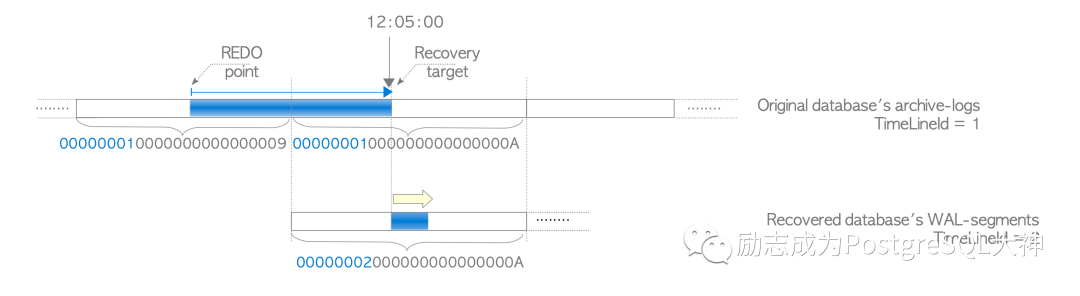 下图进一步说明了此过程,例如现在恢复点是12点05分,它正好位于00000001000000000000000A文件位置的中间,它将首先恢复0000000100000000000000000009文件,当它恢复到目标位置,新恢复的数据库集簇就会被分配TimeLine ID为2,然后将新建一个 WAL文件"000000020000000000000000000A"。从此,集簇正式进入时间轴2。
下图进一步说明了此过程,例如现在恢复点是12点05分,它正好位于00000001000000000000000A文件位置的中间,它将首先恢复0000000100000000000000000009文件,当它恢复到目标位置,新恢复的数据库集簇就会被分配TimeLine ID为2,然后将新建一个 WAL文件"000000020000000000000000000A"。从此,集簇正式进入时间轴2。
Logical File ID和Physical File ID
如何计算Logical File ID和 Physical File ID呢?先看一下Physical File ID,默认是从00开始写,一直写到 FF,然后再循环再次从00开始。在完成00到FF一个循环再到00的转换后, Logical File ID就会增加1。
尽管如此,但他们仍然有一个复杂的公式。
Logical File ID的算法如下:
Logical File ID的算法如下:
先计算一下当前的 LSN。
postgres=# select pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/8000270
(1 row)
把当前的LSN号转换成数字。
postgres=# select x'8000270'::bigint;
int8
-----------
134218352
(1 row)
然后用这数字去计算Logical File ID
postgres=# select ((134218352 - 1) / (16*1024*1024*256));
ERROR: integer out of range
这里计算报integer out of range
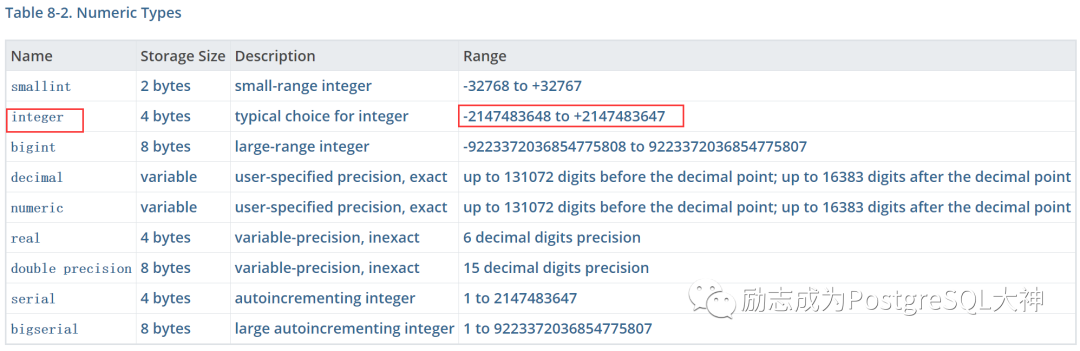
,超出了范围值。那是因为这里是 integer类型,它的最大值是2的31次方-1,仔细看后面的这一串数字正好是2的32次方。所以我们要把这串数字转换成bigint来计算。
postgres=# select pg_typeof(16*1024*1024*256);
ERROR: integer out of range
postgres=# select 16*1024*1024*256::bigint;
?column?
------------
4294967296
(1 row)
postgres=# select ((134218352 - 1) / (16*1024*1024*256::bigint));
?column?
----------
0
(1 row)
这里求出来的是Logical File ID为0,再来看看Pyhsical File ID,通过计算得出来的是8。
postgres=# select mod(((134218352 - 1) / (16*1024*1024)),256);
mod
-----
8
(1 row)
postgres=# select to_hex(8);
to_hex
--------
8
(1 row)
想一想这个算法也很精妙,用256进行取模,不管怎么样都是0-255。换算成16进制转换为00- FF。一个文件的大小正好是16M,当生成256 (00- FF)个文件时,这些文件按照字节数算,就是2的32次方。因此达到这一值将在高位进1。即 Logical File ID增加了1。
尾声
今天的WAL的这串数字是有点学院派技术风格的,并不像其他数据库那样只是简单的数字增长。而是给咱们来了一个高低位算法。还有Hironobu UZUKI
大神,他的个人站点(https://www.interdb.jp/)是一个不错的研究数据库内核技术的参考网站。而且这些资料已经被翻译成中文,叫做 PostgreSQL指南内部探索
。我本人之前已经购买,但我还是喜欢在它的网站上浏览英文版资料。
参考链接
1.https://www.interdb.jp/pg/pgsql09.html
2.https://www.interdb.jp/pg/pgsql10.html#_10.3.1.
3.https://www.slideshare.net/loxodata/dig-thewal-pgconfeu2018


励志成为PostgreSQL大神
长按关注吧
