





1.数据库的模式和DDL不会复制
这里可能会有个疑问,当我们在主库上创建订阅的时候指定for all tables,然后建新表是否会自动同步?
我们来测试一下。
--发布实例CREATE PUBLICATION testpub FOR ALL TABLES;hr=# CREATE PUBLICATION testpub FOR all tables;CREATE PUBLICATIONhr-# \dRp List of publications Name | Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root ---------+----------+------------+---------+---------+---------+-----------+---------- testpub | postgres | t | t | t | t | t | f(1 row)hr=# select * from pg_publication_tables; pubname | schemaname | tablename ---------+------------+----------- testpub | public | jobs(1 row)复制
当前我的发布实例,hr数据库中有一张jobs表在发布组里面。此时我在订阅实例创建订阅,jobs表之前已存在。此时会发生关于jobs表上数据的同步。
--订阅实例hr=# create subscription testsub connection 'host=192.168.56.119 port=5432 dbname=hr user=replication' publication testpub;hr=# \d List of relations Schema | Name | Type | Owner --------+------+-------+------- public | jobs | table | hr(1 row)复制
我执行ddl进行测试。
--发布实例hr=# alter table jobs add a1 integer;ALTER TABLE--订阅实例hr=# \d+ jobs Table "public.jobs" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description ------------+-----------------------+-----------+----------+---------+----------+--------------+------------- job_id | character varying(10) | | not null | | extended | | job_title | character varying(35) | | not null | | extended | | min_salary | integer | | | | plain | | max_salary | integer | | | | plain | | Access method: heap复制
可见发布实例上执行完ddl,并不会同步到订阅实例。
此时若执行create table,我们看看会发生什么?
--发布实例CREATE TABLE departments ( department_id smallint NOT NULL, department_name varchar(30) NOT NULL, manager_id integer, location_id smallint) ;hr=# select * from pg_publication_tables; pubname | schemaname | tablename ---------+------------+------------- testpub | public | departments testpub | public | jobs(2 rows)--订阅实例hr=# \dRs List of subscriptions Name | Owner | Enabled | Publication ---------+----------+---------+------------- testsub | postgres | t | {testpub}(1 row)复制
可以看到如果创建新表,它会自动加到发布列表中,如果你在订阅实例有同样的表就可以复制,如果没有,它是不会自动创建的。
虽然不能复制DDL,但是我们可以绕行一下,我们可以使用触发器来实现DDL的复制。简单来讲就是把DDL的语句记录下来存到表里面,然后发送给订阅侧,订阅侧写入DDL记录,与此同时这张表上的触发器也会触发,然后执行DDL操作。
2.Truncate命令的部分限制
Truncate命令在PostgreSQL属于DML语言,这个在我之前些的文章《PostgreSQL 查LAST DDL TIME的三种方法》讨论过。那么它应该可以复制,确实如此它是可以复制的。虽然它可以复制但是它有一个需要注意的地方:“表上存在主外键关系。”
--发布侧和订阅侧都创建CREATE TABLE departments ( department_id smallint NOT NULL, department_name varchar(30) NOT NULL, manager_id integer, location_id smallint) ;CREATE TABLE employees ( employee_id integer NOT NULL, first_name varchar(20), last_name varchar(25) NOT NULL, email varchar(25) NOT NULL, phone_number varchar(20), hire_date timestamp NOT NULL, job_id varchar(10) NOT NULL, salary double precision, commission_pct real, manager_id integer, department_id smallint) ;hr=# ALTER TABLE employees ADD PRIMARY KEY (employee_id);ALTER TABLEhr=# ALTER TABLE departments ADD CONSTRAINT dept_mgr_fk FOREIGN KEY (manager_id) REFERENCES employees(employee_id) ON DELETE NO ACTION NOT DEFERRABLE INITIALLY IMMEDIATE;ALTER TABLEhr=# select * from pg_publication_tables; pubname | schemaname | tablename ---------+------------+------------- testpub | public | employees testpub | public | departments testpub | public | jobs(3 rows)复制
此时在发布侧执行truncate主键表。
hr=# truncate table employees;ERROR: cannot truncate a table referenced in a foreign key constraintDETAIL: Table "departments" references "employees".HINT: Truncate table "departments" at the same time, or use TRUNCATE ... CASCADE.hr=# truncate table employees CASCADE;NOTICE: truncate cascades to table "departments"TRUNCATE TABLE复制
这里提示报错需要指定CASCADE选项级联truncate。我们执行runcate .... CASCADE,可以正常同步到订阅端。这是因为我们的发布端中有这2个表。如果我们的发布端,这两张表属于两个发布,订阅端也使用两个独立开的订阅。这个truncate就会存在问题。我们来测试一下。
--发布端hr=# create publication testpub1 FOR table employees; hr=# create publication testpub2 FOR table departments;--订阅端hr=# create subscription testsub1 connection 'host=192.168.56.119 port=5432 dbname=hr user=replication' publication testpub1; hr=# create subscription testsub2 connection 'host=192.168.56.119 port=5432 dbname=hr user=replication' publication testpub2;复制
现在我们在发布端执行truncate主表
hr=# truncate table employees cascade;复制
然后在订阅端的日志马上就会出现下列报错。
2021-03-25 21:17:31.131 CST [1775] ERROR: cannot truncate a table referenced in a foreign key constraint2021-03-25 21:17:31.131 CST [1775] DETAIL: Table "departments" references "employees".2021-03-25 21:17:31.131 CST [1775] HINT: Truncate table "departments" at the same time, or use TRUNCATE ... CASCADE.2021-03-25 21:17:31.132 CST [1466] LOG: background worker "logical replication worker" (PID 1775) exited with exit code 12021-03-25 21:17:31.134 CST [1794] LOG: logical replication apply worker for subscription "testsub1" has started复制
直接导致logical replication worker
进程出现报错退出。所以说truncate这里还是需要我们注意一下的。
3.无法复制对象
逻辑复制只能复制普通表上的数据,无法复制物化视图、索引、序列、外部表、UNLOGGED TABLE、INHERIT TABLE 、分区根表,还有大对象。
4.使用了SERIAL列和序列的值需要注意
当我们使用SERIAL列或者插入序列的值的时候,需要注意的一点是,它是直接复制的SQL语句,并没有真正的在订阅侧再次调用序列。我们来实测一下。
--发布侧CREATE TABLE t(a SERIAL, b CHAR);create publication testpub1 FOR table t; --订阅侧CREATE TABLE t(a SERIAL, b CHAR);create subscription testsub1 connection 'host=192.168.56.119 port=5432 dbname=hr user=replication' publication testpub1;复制
搭建好之后,我们在发布侧执行插入语句。
--发布侧hr=# insert into t(b) values('A');INSERT 0 1hr=# insert into t(b) values('B');INSERT 0 1hr=# hr=# select * from t; a | b ---+--- 1 | A 2 | B(2 rows)复制
然后我们到订阅侧去插入一条语句看看。
hr=# select * from t; a | b ---+--- 1 | A 2 | B(2 rows)hr=# insert into t(b) values('B');INSERT 0 1hr=# select * from t; a | b ---+--- 1 | A 2 | B 1 | B(3 rows)复制
可以很明显的看到,我们插入一条数据,SERIAL列的值还是1。序列也是一样。所以这就有可能会导致你在备库上执行事务出现较低的序列值,或者是主键冲突错误。比较建议的一个做法是手动在订阅端把这个序列值设置的足够大。
5.触发器的限制
PostgreSQL触发器属性上可以分FOR EACH ROW
和FOR EACH STATEMENT
。两者的区别是,FOR EACH ROW
操作修改时每行调用一次,而FOR EACH STATEMENT
,不管修改了多少行,每个语句标记的触发器只执行一次。所以这就在订阅复制的时候,只有FOR EACH ROW
触发器能执行。而FOR EACH STATEMENT
则只会在初始化数据的时候执行。
要让触发器能正常工作,我们还需要设置ALTER TABLE ENABLE ALWAYS
或者REPLICA TRIGGER
语句。
6.双向复制
既然是逻辑复制,一定是可以支持双向复制的。但是很遗憾,它能够配置,但是WAL会出现循环。
我们来测试一下。
--正向 发布CREATE TABLE t(a SERIAL, b CHAR);create publication testpub1 FOR table t; --正向 订阅CREATE TABLE t(a SERIAL, b CHAR);create subscription testsub1 connection 'host=192.168.56.119 port=5432 dbname=hr user=replication' publication testpub1;--反向 发布create publication testpub2 FOR table t; --反正 订阅create subscription testsub2 connection 'host=192.168.56.170 port=5432 dbname=hr user=replication' publication testpub2;复制
至此我打造了一个双向循环复制,如图所示。
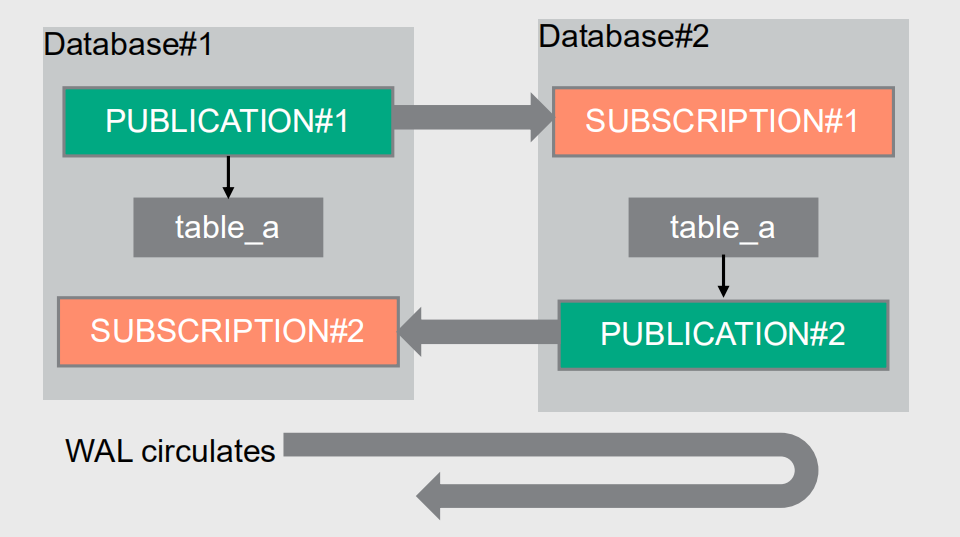
此时我在发布端插入一条数据就会出现环绕现像。此时就会出现死循环。不停的从A复制到B,再从B复制到A,直到把数据库搞死为止。
刚刚才配好不到1分钟,已经循环复制了2685条。
hr=# select count(1) from t; count ------- 2685(1 row)hr=# select count(1) from t; count ------- 3600(1 row)hr=# select count(1) from t; count ------- 3784(1 row)复制
双向复制需要使用不同的表来实现。使用同样的表会产生WAL循环
7.逻辑复制和流复制组合使用的限制
逻辑复制可以和流复制一起使用,但是也有限制。就是逻辑复制不能在standby实例上创建,因为standby是只读的,不能创建逻辑复制插槽。因此逻辑解码插件也无法在standby实例上执行。
后记
今天的限制及好玩的双向复制就到这里。未完待续....


励志成为PostgreSQL大神
长按关注吧



