




什么是分布式数据库?
分布式数据库不限于单个系统,而是分散在许多地方,例如两台或多台计算机或计算机网络。分布式数据库或数据管理系统分布在多个站点上,没有物理部件。如果全球许多个人需要访问特定数据库,则可能需要这样做,因此,必须对其进行管理,以便在消费者看来它是一个单一的数据库。
分布式数据库可用于水平扩展性和满足负载需求,而无需更改数据库模式或垂直扩展单个系统。
分布式数据库解决了使用单个系统和单个数据库时可能出现的几个问题,包括可用性、容错性、吞吐量、延迟、可伸缩性等。
为什么要使用分布式数据库?
分布式数据库在保持本地控制的同时提供了数据位置的清晰性。这意味着,即使应用程序不知道数据是什么,每个站点也可以在本地管理数据、管理安全、记录事务,并在本地的网站出现问题时进行恢复。
即使与其他站点的连接中断,自治仍然可用。在特定位置保存的专用数据可能需要比其他数据更多的安全性和法规遵从性限制的情况下,这提供了更大的灵活性。
例如,为欧盟地区的零售客户维护的客户数据必须符合GDPR规则。
数据如何存储在分布式数据库中?
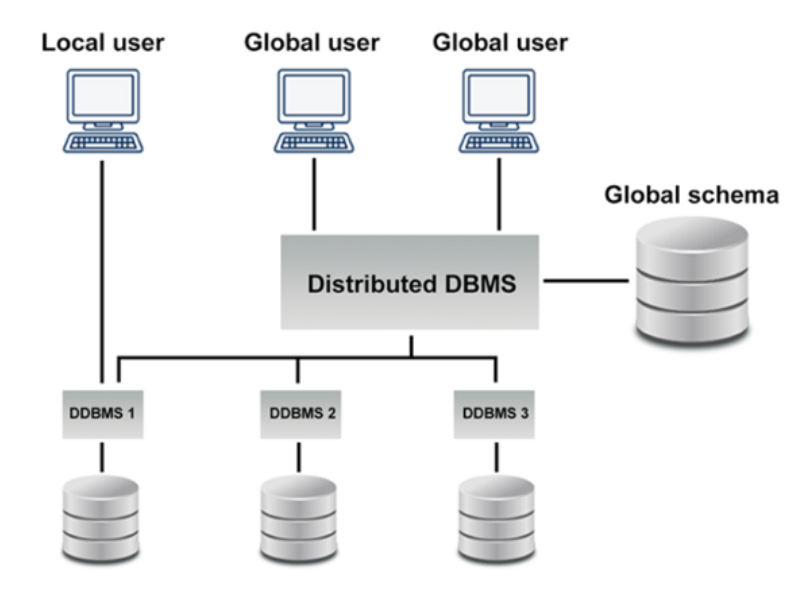
有两种不同的方式可以将数据存储在不同的站点上,从而形成分布式数据库。
这两种方式是复制和碎片化。
复制品
数据库复制方法跨多个位置复制数据。然而,一个完全冗余的数据库存储在许多地方。数据库复制的好处在于,它提高了多个站点的数据可用性,并支持并行查询处理。
但是,数据库复制需要频繁更新并与其他站点同步,以维护精确的数据库副本。因此,一方所做的任何修改必须复制到其他站点,以避免差异。
此外,频繁的更新要求在所有可访问站点上验证许多并发查询,从而增加了服务器成本并使并发管理复杂化。
碎片
每当涉及到存储碎片的分布式数据库时,关系都是碎片化的,这表明它们被分解为更小的部分。因此,当需要时,每件物品都存储在不同的位置。
碎片化要求在不丢失数据的情况下,甚至可以将片段重建为原始关系。碎片化的好处是不会创建信息重复,从而防止数据不一致。
碎片可以分为两种类型:水平碎片需要将关系模式划分为行组,每个组(元组)被赋予不同的碎片。垂直分割需要将相关模型分割成更小的模式,每个元素包括一个共享的候选密钥,以确保无损连接。
分布式数据库的类型
分布式数据库主要分为两类,即异构和异构分布式数据库。
均匀分布数据库
所有位置在同一分布式数据库中使用相同的DBMS和操作系统。这些站点使用非常相似的软件,以及相同的DBMS或来自同一供应商的DBMS。此外,每个站点都知道许多其他站点的存在,并与它们协作执行用户的请求。此外,可以通过单个平台访问数据库,就像访问单个数据库一样。
同构数据库进一步分为自治和非自治类型。独立意味着每个数据库都是独立的,并独立运行。管理程序集成了它们,并使用消息传递来传递数据更改。
同时,在非自治的情况下,数据分散在同质节点中,并且通过集中式或主DBMS跨位置协调变化。
异构数据库
异构分布式数据库中的不同位置包括不同的操作系统、DBMS产品和数据模型。it中的多个网站采用各种模式和技术。例如,系统可能有许多关系、网络、分层或面向对象的DBMS。另一个特点是,由于模式的差异,查询执行比较复杂。由于软件的差异,事务处理非常复杂。例如,由于一个站点可能不知道许多其他站点,因此在处理用户请求时协调有限。
联合和非联合异构分布式系统是另外两类。在联邦数据库中,异构数据库系统是自治和连接的,因为它们作为单一数据库工作。相反,这些数据库可通过联合国联合数据库中的中央协调单位访问。
分布式数据库的好处
分布式数据库是任何组织信息架构的基础,因为数据在我们日常生活中变得越来越重要。
例如,在大多数情况下,使用web服务器或移动电话应用程序的终端用户可能看不到分布式数据库正在运行-正是分布式数据库在后台非常努力地工作,支持了许多此类用例。
扩展数据库给游戏带来的基本优势是提高性能、大规模可扩展性和全天候可靠性。
不同数据库的可用性
企业每天都在创建PB级的数据。然而,并非所有数据库都提供了满足数据存储和访问需求所需的灵活性、可用性和可扩展性。
分布式数据库在同一网络或其他网络上的多个物理位置保存文档和数据。可伸缩性允许分布式数据库系统让您适应和满足不断扩大的数据需求。例如,分布式数据库在不同位置使用多台机器,而不是将存储空间和事务处理限制在单个系统中。这提高了客户的速度、数据恢复和体验。
可用于分布式数据存储的顶级数据库之一是HarperDB。
什么是HarperDB?
HarperDB是一个分布式数据和应用程序开发平台,支持SQL和NoSQL。它完全索引,不复制数据,可以在任何系统上使用,从边缘到云。
HarperDB具有自定义功能和微服务架构,易于使用和集成。数据平台正在帮助企业降低全球基础设施的成本,同时提供低于10毫秒的延迟。
HarperDB旨在通过将SQL和NoSQL的最佳特性结合到一个平台中来支持SQL和NoSQL用例。
此外,它具有独特的集群技术,用于在HarperDB节点之间复制数据。它允许表级的发布-订阅配置,因此不需要将所有数据迁移到所有节点。例如,数据、子集或表的某些部分可以驻留在边缘服务器上,云可能包含所有内容。则另一边缘节点可以具有不同的数据子集。因此,它非常高效,几乎可以与您能想到的任何数据结构一起工作。
结论
最后,您可能已经从本文中了解到,数据库是一个有组织的信息集合。
数据库广泛分为两类:分布式数据库和集中式数据库。分布式数据库解决了在使用单个系统和单个数据库时可能出现的几个问题,如可用性、容错性、吞吐量、延迟、可伸缩性等。
例如,分布式数据库是一种包括两个或多个文件的类型,这些文件放置在同一网络或完全不同的网络上的多个计算机或位置上。这些位置不共享物理组件。
使用分布式数据库有几个好处。可用性、可靠性和更快的反应时间是几个例子。分布式数据库还通过减少所需的服务器和系统的数量以及消除昂贵的维护保养需求来降低成本。
原文标题:What Is a Distributed Database?
原文作者:Ankur Tyagi
原文链接:https://dzone.com/articles/what-is-a-distributed-database
