




在此前的贴子中,我们介绍了扩展统计信息,它可以帮助优化器改善SQL语句基数评估的准确性。这些SQL包括谓词中涉及函数封装列(比如 UPPER(LastName)),或者过滤谓词,连接条件,或者group-by中包含同一张表中的多个列的情况。因此,扩展统计信息是特别有用的。但是,您怎么知道应该创建哪种扩展统计信息呢?
在Oracle Database 11.2.0.2中,引入了自动列组(译者注:即在多个列的组合上,创建扩展统计信息)创建。对于给定的负载 ,它可以自动确定在表上需要哪些列组。但是,请注意,这个功能不能为函数封装列创建扩展统计信息,它只能针对列组创建。自动列组创建只需三个简单步骤:
1. 种子列的使用情况
Oracle必须观察典型的工作负载,以便确定适合的列组。使用新的存储过程DBMS_STATS.SEED_COL_USAGE,告诉Oracle应该观察工作负载多久。以下示例打开监控5分钟或300秒。该监控过程记录的信息,与你从sys.col_usage中看到的传统的列使用情况信息不同,并将其记录到sys.col_group_usage中。
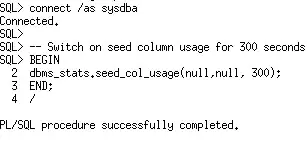
在该监控窗口期,你并不需要执行所有业务中用到的查询。你可以简单的对运行时间较长的查询执行explain plan for,以便为这些查询记录下列组信息。以下示例中使用了两个在customers_test表(来自于SH schema中的customers表)上运行的查询。

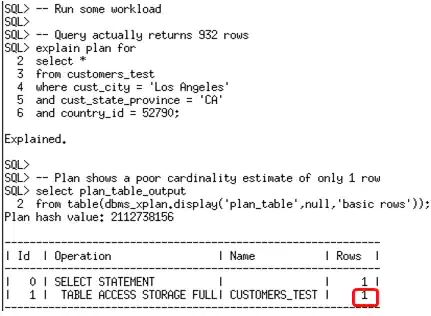
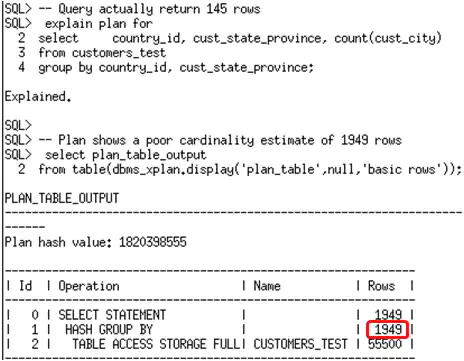
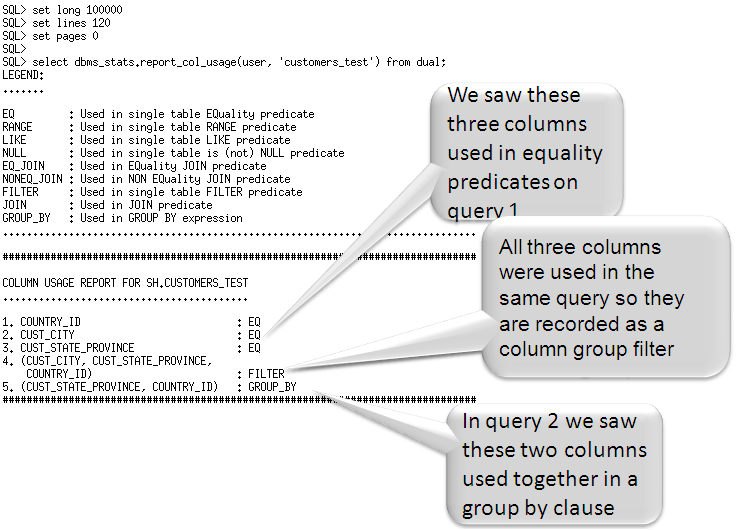
一旦监控窗口期结束,就可以使用新的函数DBMS_STATS.REPORT_COL_USAGE,查看为特定表记录的列组使用信息。该函数生成一个报告,它会列出出现在负载中的过滤谓词,连接谓接和GROUP BY子句中的列。
通过执行DBMS_STATS.REPORT_COL_USAGE,且只提供Schema名而对表名参数使用NULL,也可以查看指定SCHEMA下,针对所有表的报告。
2.创建列组
此时,基于监控窗口期间捕获到的使用信息,你可以得到Oracle为每一张表自动创建的列组。您只需为每一张表调用DBMS_STATS.CREATE_EXTENDED_STATS函数即可。该函数只需要两个参数,SCHEMA名和表名。此后,每当表上的统计信息被收集时,都会对每一个列组进行维护。在本例中,您将看到基于从本负载中的两个查询所获取的信息,而创建 的两个列组。

还可以运行DBMS_STATS.CREATE_EXTENDED_STATS函数一次,给表名传入NULL值,而为特定SCHEMA下,创建所有建议的列组。
3. 重新收集统计信息
最后一步是在受影响的表上重新收集统计信息,以便新创建的列组拥有统计信息。

一旦统计信息已被收集,您应该检查USER_TAB_COL_STATISTICS视图,来看看哪些额外的统计信息被创建了。在本例中,您将看到customers_test表上列出了两个新的列,均拥有系统生成的名称,其名称与DBMS_STATS.CREATE_EXTENDED_STATS函数中返回的名称是相同的。

您还会注意到,其中一个列组上创建了高度平衡直方图。该列组是在CUST_CITY, CUST_STATE_PROVINCE, 和COUNTRY_ID列上创建的。在监控列组时,我们也会监控到直方图可能对列组是有用的这一事实,并在随后的统计信息收集时为列组创建直方图。现在,列组已经就位,让我们看看它对在监控窗口中使用的两个查询的基数评估是否有改善?
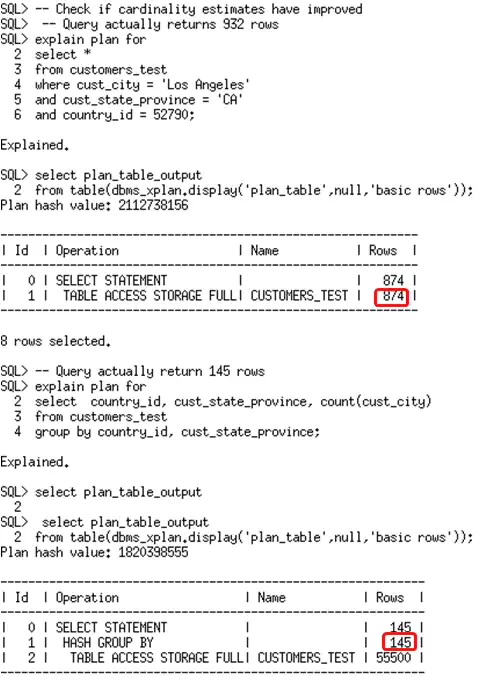
在这两个例子中,基数的评估均比没有扩展统计信息时更精确了。
原文链接:https://blogs.oracle.com/optimizer/post/how-do-i-know-what-extended-statistics-are-needed-for-a-given-workload
How do I know what extended statistics are needed for a given workload?
January 1, 2020 | 4 minute read
Maria Colgan
Distinguished Product Manager
In our previous post we introduced extended statistics, which help the Optimizer improve the accuracy of cardinality estimates for SQL statements that contain predicates involving a function wrapped column (e.g. UPPER(LastName)) or multiple columns from the same table used in filter predicates, join conditions, or group-by keys. So extended statistics are extremely useful but how do you know which extended statistics should be created?
In Oracle Database 11.2.0.2 we introduced Auto Column Group Creation, which automatically determines which column groups are required for a table based on a given workload. Please note this functionality does not create extended statistics for function wrapped columns it is only for column groups. Auto Column Group Creation is a simple three step process:
1. Seed column usage
Oracle must observe a representative workload, in order to determine the appropriate column groups. Using the new procedure DBMS_STATS.SEED_COL_USAGE, you tell Oracle how long it should observe the workload. The following example turns on monitoring for 5 minutes or 300 seconds. This monitoring procedure records different information from the traditional column usage information you see in sys.col_usage$ and it is stored in sys.col_group_usage$.
auto1.png
You don’t need to execute all of the queries in your work during this window. You can simply run explain plan for some of your longer running queries to ensure column group information is recorded for these queries. The example below uses two queries that run against the customers_test table (which is a copy of the customers table in the SH schema).
Snap2-1.png
Snap2-2.png
Snap2-4.png
Once the monitoring window has finished, it is possible to review the column usage information recorded for a specific table using the new function DBMS_STATS.REPORT_COL_USAGE. This function generates a report, which lists what columns from the table were seen in filter predicates, join predicates and group by clauses in the workload.
auto3-1.PNG
It is also possible to view a report for all the tables in a specific schema by running DBMS_STATS.REPORT_COL_USAGE and providing just the schema name and NULL for the table name.
2. Create the column groups
At this point you can get Oracle to automatically create the column groups for each of the tables based on the usage information captured during the monitoring window. You simply have to call the DBMS_STATS.CREATE_EXTENDED_STATS function for each table.This function requires just two arguments, the schema name and the table name. From then on, statistics will be maintained for each column group whenever statistics are gathered on the table. In this example you will see two column groups were created based on the information captured from the two queries in this workload.
Auto4.png
It is also possible to create all of the proposed column groups for a particular schema in one shot by running the DBMS_STATS.CREATE_EXTENDED_STATS function and passing NULL for the table name.
3. Regather statistics
The final step is to regather statistics on the affected tables so that the newly created column groups will have statistics created for them.
Auto5.png
Once the statistics have been gathered you should check out the USER_TAB_COL_STATISTICS view to see what additional statistics were created. In this example you will see two new columns listed for the customers_test table. Both columns have system generated names, the same names that were returned from the DBMS_STATS.CREATE_EXTENDED_STATS function.
auto6.png
You will also notice that one of the column groups has a height-based histogram created on it. This column group was created on CUST_CITY, CUST_STATE_PROVINCE, and COUNTRY_ID. While monitoring column groups we also monitor the fact that histogram may be potentially useful for the column groups and subsequent statistics collection create a histogram for the group. So now that the column groups are in place, let’s see if they improved the cardinality estimates for the two queries we used in the monitoring window.
Snap7.png
In both cases the cardinality estimate is far more accurate than without extended statistics.
