




祝全体读者新年快乐!希望你们都度过了一个愉快的假期。我们将继续我们的优化器转换系列来开始新的一年。这次轮到谓词推入了。我要感谢拉菲·艾哈迈德(Rafi Ahmed)为我提供了这个博客的内容。
正常情况下,一个视图不会用基于索引的嵌套循环来连接,因为一个视图与基表的不同,是其上没有索引。视图与其它表连接时,只能使用三种方法:哈希,嵌套循环和排序合并连接。
介绍
连接谓词推入(JPPD)转换允许一个视图用基于索引的嵌套循环连接方法来连接,这可能会提供一个更优的选择。在连接谓词推入转换中,视图仍做为一个独立的查询块,但是它所包含的连接谓词,被包含它的查询块推入到视图中。视图因此而成为相关视图,且对于外层查询块中的每一行都要访问一次。这些推入的谓词,一旦处于视图中,就会在视图的基表上打开新的索引访问方法;允许使用基于索引的嵌套循环连接方法去与视图连接,因而允许优化器来选择一个高效的执行计划。
连接谓词推入不总是最优的。推入连接谓词的视图成为一个相关视图,它必须为外层的每一行而访问;如果外层的行有很多,多次访问视图的成本可能使嵌套循环连接欠佳,从而使哈希或排序合并的连接方法可能会更有效。
是否推入连接谓词的决定是由Oracle的基于成本的查询转换架构下,外层查询使用或不使用连接谓词推入转换的成本来确定的。
连接谓词推入转换可用于不可合并视图和可合并视图,也可用于预定义和内联视图,以及在各种查询转换期间由优化器生成的内部视图。下面显示了当前支持连接谓词推入的视图类型。
- UNION ALL/UNION 视图
- 外连接视图
- 反连接视图
- 半连接视图
- DISTINCT视图
- GROUP-BY视图
示例
请看查询A,它有一个外连接视图V。该视图不能被合并,因为它包含两张表,并且这两张表的连接必须在视图与外层表T4连接前就被执行。
A:
SELECT T4.unique1, V.unique3 FROM T_4K T4, (SELECT T10.unique3, T10.hundred, T10.ten FROM T_5K T5, T_10K T10 WHERE T5.unique3 = T10.unique3) V WHERE T4.unique3 = V.hundred(+) AND T4.ten = V.ten(+) AND T4.thousand = 5;复制
下图显示了并闭了连接谓词推入时,为查询A生成的非默认的执行计划:
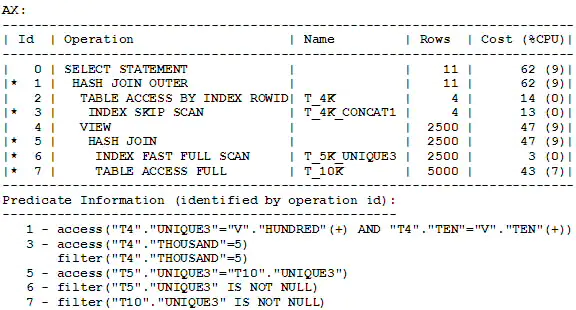
当查询A经历谓词推入时,它会生成查询B。请注意,查询B是用非标准的SQL来展示该查询的内部表现形式的。
B:
SELECT T4.unique1, V.unique3 FROM T_4K T4, (SELECT T10.unique3, T10.hundred, T10.ten FROM T_5K T5, T_10K T10 WHERE T5.unique3 = T10.unique3 AND T4.unique3 = V.hundred(+) AND T4.ten = V.ten(+)) V WHERE T4.thousand = 5;复制
查询B的执行计划如下所示:
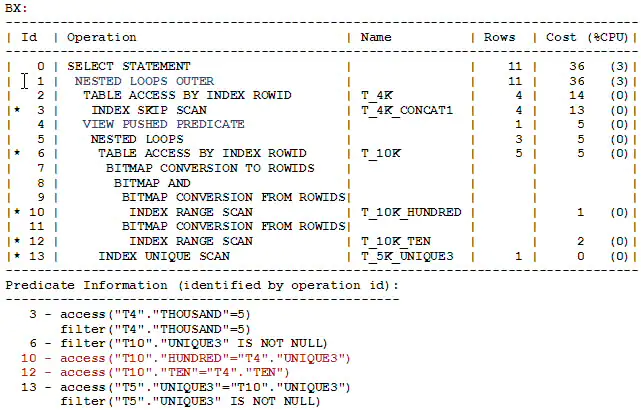
在执行计划BX中,请注意关键字 ‘VIEW PUSHED PREDICATE’,它提示视图经历了连接谓词推入转换。连接谓词(用红色显示)被移到了视图V中;这些连接谓词产生了索引访问方法,因而允许视图的基于索引的嵌套循环连接。使用连接谓词推入,查询A的的成本由62下降到了32(译者注:应为36,原文为32).
如前所述,连接谓词推入转换是基于成本的,只有当它可以降低整体成本时,才会选择连接谓词推入的执行计划。
再来看另一个示例查询C,它包含一个带有UNION ALL集合操作符的视图。
C:
SELECT R.unique1, V.unique3 FROM T_5K R, (SELECT T1.unique3, T2.unique1+T1.unique1 FROM T_5K T1, T_10K T2 WHERE T1.unique1 = T2.unique1 UNION ALL SELECT T1.unique3, T2.unique2 FROM G_4K T1, T_10K T2 WHERE T1.unique1 = T2.unique1) V WHERE R.unique3 = V.unique3 and R.thousand < 1;复制
查询C的执行计划如下所示:
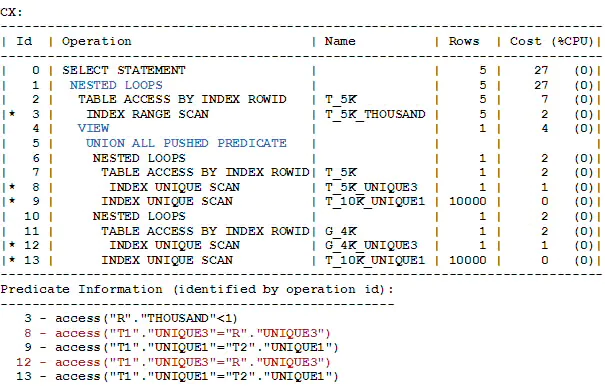
上图中,'VIEW UNION ALL PUSHED PREDICATE’提示UNION ALL视图经历了连接谓词推入转换。如图所示,连接谓词被复制并推入到UNION ALL视图中的每一个分支中。连接谓词(用红色显示)打开了索引访问方法,因而允许视图的基于索引的嵌套循环连接。
来看连接谓推入DISTINCT视图的示例查询D。查询D中涉及的表的基数如下:
Sales (1,016,271), Customers (50,000), and Costs (787,766).
D:
SELECT C.cust_last_name, C.cust_city FROM customers C, (SELECT DISTINCT S.cust_id FROM sales S, costs CT WHERE S.prod_id = CT.prod_id and CT.unit_price > 70) V WHERE C.cust_state_province = 'CA' and C.cust_id = V.cust_id;复制
查询D的执行计划如下所示:
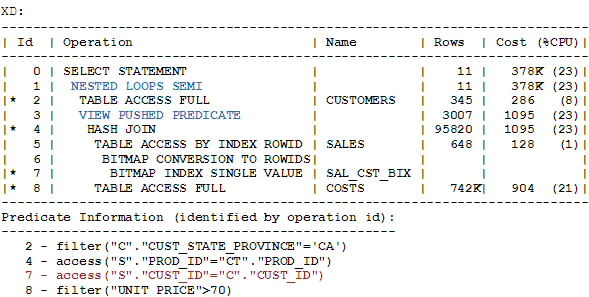
如XD中所示,当查询D经历连接谓词推入转换时,昂贵的DISTINCT操作符被移除,且连接被转换为一个半连接。由于视图SELECT中的所有列都参与了与外层表的等值连接,所以这是可能的。在类似条件下,当一个GROUP-BY视图经历连接谓词推入转换时,昂贵的GROUP-BY操作符也是可以被移除的。
使用连接谓词推入转换,查询D的经历时间从63秒下降到5秒。
由于DISTINCT和GROUP-BY视图是可合并视图,在选择最优执行计划时,基于成本的转换架构也会比较合并视图与连接谓词推入的成本。
总结
通过展示十分简单的示例查询,我们试图演示连接谓词推入在不同类型视图中的基本理论。Oracle可以处理更为复杂的查询以及未在这里示例的其它类型的视图。再次感谢拉菲·艾哈迈德(Rafi Ahmed)为这个博客提供了内容。
原文链接:https://blogs.oracle.com/optimizer/post/optimizer-transformation-join-predicate-pushdown
Optimizer Transformation: Join Predicate Pushdown
January 1, 2020 | 5 minute read
Maria Colgan
Distinguished Product Manager
Happy New Year to all of our readers! We hope you all had a great holiday season. We start the new year by continuing our series on Optimizer transformations. This time it is the turn of Predicate Pushdown. I would like to thank Rafi Ahmed for the content of this blog.
Normally, a view cannot be joined with an index-based nested loop (i.e., index access) join, since a view, in contrast with a base table, does not have an index defined on it. A view can only be joined with other tables using three methods: hash, nested loop, and sort-merge joins.
Introduction
The join predicate pushdown (JPPD) transformation allows a view to be joined with index-based nested-loop join method, which may provide a more optimal alternative. In the join predicate pushdown transformation, the view remains a separate query block, but it contains the join predicate, which is pushed down from its containing query block into the view. The view thus becomes correlated and must be evaluated for each row of the outer query block. These pushed-down join predicates, once inside the view, open up new index access paths on the base tables inside the view; this allows the view to be joined with index-based nested-loop join method, thereby enabling the optimizer to select an efficient execution plan.
The join predicate pushdown transformation is not always optimal. The join predicate pushed-down view becomes correlated and it must be evaluated for each outer row; if there is a large number of outer rows, the cost of evaluating the view multiple times may make the nested-loop join suboptimal, and therefore joining the view with hash or sort-merge join method may be more efficient.
The decision whether to push down join predicates into a view is determined by evaluating the costs of the outer query with and without the join predicate pushdown transformation under Oracle’s cost-based query transformation framework.
The join predicate pushdown transformation applies to both non-mergeable views and mergeable views and to pre-defined and inline views as well as to views generated internally by the optimizer during various transformations. The following shows the types of views on which join predicate pushdown is currently supported.
- UNION ALL/UNION view
- Outer-joined view
- Anti-joined view
- Semi-joined view
- DISTINCT view
- GROUP-BY view
Examples
Consider query A, which has an outer-joined view V. The view cannot be merged, as it contains two tables, and the join between these two tables must be performed before the join between the view and the outer table T4.
A:
SELECT T4.unique1, V.unique3 FROM T_4K T4, (SELECT T10.unique3, T10.hundred, T10.ten FROM T_5K T5, T_10K T10 WHERE T5.unique3 = T10.unique3) V WHERE T4.unique3 = V.hundred(+) AND T4.ten = V.ten(+) AND T4.thousand = 5;复制
The following shows the non-default plan for query A generated by disabling join predicate pushdown.
pred_push_plan1.png
When query A undergoes join predicate pushdown, it yields query B. Note that query B is expressed in a non-standard SQL and shows an internal representation of the query.
B:
SELECT T4.unique1, V.unique3 FROM T_4K T4, (SELECT T10.unique3, T10.hundred, T10.ten FROM T_5K T5, T_10K T10 WHERE T5.unique3 = T10.unique3 ANDT4.unique3 = V.hundred(+) AND T4.ten = V.ten(+)) V WHERE T4.thousand = 5;复制
The execution plan for query B is shown below.
pred_push_plan2.png
In the execution plan BX, note the keyword ‘VIEW PUSHED PREDICATE’ indicates that the view has undergone the join predicate pushdown transformation. The join predicates (shown here in red) have been moved into the view V; these join predicates open up index access paths thereby enabling index-based nested-loop join of the view. With join predicate pushdown, the cost of query A has come down from 62 to 32.
As mentioned earlier, the join predicate pushdown transformation is cost-based, and a join predicate pushed-down plan is selected only when it reduces the overall cost.
Consider another example of a query C, which contains a view with the UNION ALL set operator.
C:
SELECT R.unique1, V.unique3 FROM T_5K R, (SELECT T1.unique3, T2.unique1+T1.unique1 FROM T_5K T1, T_10K T2 WHERE T1.unique1 = T2.unique1 UNION ALL SELECT T1.unique3, T2.unique2 FROM G_4K T1, T_10K T2 WHERE T1.unique1 = T2.unique1) V WHERE R.unique3 = V.unique3 and R.thousand < 1;复制
The execution plan of query C is shown below.
pred_push_plan3.png
In the above, ‘VIEW UNION ALL PUSHED PREDICATE’ indicates that the UNION ALL view has undergone the join predicate pushdown transformation. As can be seen, here the join predicate has been replicated and pushed inside every branch of the UNION ALL view. The join predicates (shown here in red) open up index access paths thereby enabling index-based nested loop join of the view.
Consider query D as an example of join predicate pushdown into a distinct view. We have the following cardinalities of the tables involved in query D: Sales (1,016,271), Customers (50,000), and Costs (787,766).
D:
SELECT C.cust_last_name, C.cust_city FROM customers C, (SELECT DISTINCT S.cust_id FROM sales S, costs CT WHERE S.prod_id = CT.prod_id and CT.unit_price > 70) V WHERE C.cust_state_province = 'CA' and C.cust_id = V.cust_id;复制
The execution plan of query D is shown below.
pred_push_plan4.png
As shown in XD, when query D undergoes join predicate pushdown transformation, the expensive DISTINCT operator is removed and the join is converted into a semi-join; this is possible, since all the SELECT list items of the view participate in an equi-join with the outer tables. Under similar conditions, when a group-by view undergoes join predicate pushdown transformation, the expensive group-by operator can also be removed.
With the join predicate pushdown transformation, the elapsed time of query D came down from 63 seconds to 5 seconds.
Since distinct and group-by views are mergeable views, the cost-based transformation framework also compares the cost of merging the view with that of join predicate pushdown in selecting the most optimal execution plan.
Summary
We have tried to illustrate the basic ideas behind join predicate pushdown on different types of views by showing example queries that are quite simple. Oracle can handle far more complex queries and other types of views not shown here in the examples. Again many thanks to Rafi Ahmed for the content of this blog post.
