




自动化运维,你玩转了吗?
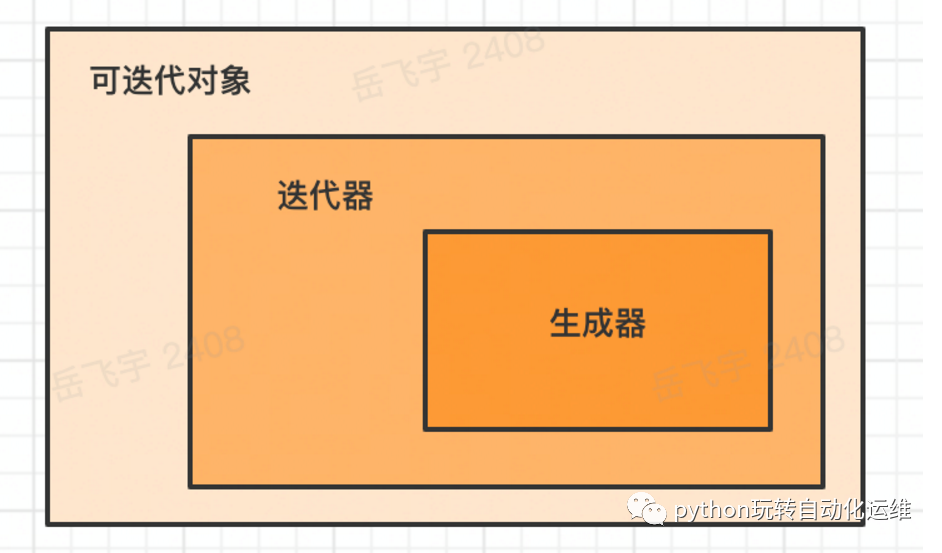
__iter__()`方法的对象就是可迭代对象,判断一个对象是不是可迭代,有两种方法:
dir函数获取某个对象的所有属性和方法,只要这个对象实现了
__iter()__方法,那么它就是可迭代对象, 如下:
dir([1, 2, 3])
# 输出 [..., '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__',...]
isinstance()函数,判断一个对象是否是
Iterable类型
from collections import Iterable
print(isinstance([1, 2, 3], Iterable))
# 输出 True
from collections import Iterable
class MyIter:
def __iter__(self):
pass
my_iter = MyIter()
print(isinstance(my_iter, Iterable))
# 输出 True
for i in my_iter:
pass
# 输出 TypeError: iter() returned non-iterator of type 'NoneType'
__iter__()方法,让可迭代对象返回一个迭代器。
__iter__()方法让其返回一个迭代器,最终才可以被for循环遍历。
官方定义如下: 1.迭代器是一个对象,该对象代表了一个数据流。 2.重复调用迭代器的 __next__
方法(或将迭代器对象当作参数传入內置函数next()中)将依次返回数据流中的元素。3.当数据流中无可返回元素时,则抛出StopIteration异常。 4.迭代器必须拥有 __iter__
方法,该方法返回迭代器对象自身
__iter__()方法和
__next()__方法。
__iter__()方法获取到其对应的迭代器对象;
__next__()方法获取下一个元素;
# for循环遍历list的代码如下:
my_list = [1, 2, 3]
for i in my_list:
print(i)
# 输出 1, 2, 3
my_list = [1, 2, 3]
next(my_list)
# 输出 TypeError: 'list' object is not an iterator
dir(my_list)
# 输出 ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__',
# '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__',
# '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
__next__()方法,所以它不是一个迭代器。
iter()方法,帮我们获取到了list对应的迭代器,如下:
print(iter(my_list))
# 输出 <list_iterator object at 0x7fccb81ca7c0>
print(my_list.__iter__())
# 输出 <list_iterator object at 0x7fccb81ca7c0>
dir(iter(my_list))
# 输出 ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__length_hint__',
# '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__']
__next__()方法,所以可以验证一下:
>>> my_iter = my_list.__iter__()
>>> my_iter.__next__()
1
>>> my_iter.__next__()
2
>>> my_iter.__next__()
3
>>> my_iter.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
我们可以对 my_list
通过__iter__()
返回的迭代器对象执行__next__()
方法并且每次对 my_iter
执行__next__()
方法后,my_iter
都会发生变化,但my_list
却是不变的
my_iter = iter(my_list)
while True:
try:
print(next(my_iter))
except StopIteration:
break
# 输出 1, 2, 3
# iter(my_iter) 等价于 my_list.__iter__()
# next(my_iter) 等价于 my_iter.__next__()
iter()方法生成该可迭代对象的新的迭代器对象
>>> f = open("test.txt")
>>> dir(f)
['_CHUNK_SIZE', '__class__', '__del__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__', '__exit__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '_checkClosed', '_checkReadable', '_checkSeekable', '_checkWritable', '_finalizing', 'buffer', 'close', 'closed', 'detach', 'encoding', 'errors', 'fileno', 'flush', 'isatty', 'line_buffering', 'mode', 'name', 'newlines', 'read', 'readable', 'readline', 'readlines', 'reconfigure', 'seek', 'seekable', 'tell', 'truncate', 'writable', 'write', 'write_through', 'writelines']
>>> type(f)
<class '_io.TextIOWrapper'>
>>> from collections import Iterator
>>> isinstance(f, Iterator)
True
with open("test.txt") as f:
data = f.readlines()
for line in data:
pass
data,那么可想而知当文件内容很多时,data就会占用很大的内存。
with open("test.txt") as f:
for line in f:
pass
f是一个迭代器,所以理所当然可以对其使用for循环遍历。
iter()函数获取到
f到迭代器对象(此处f到迭代器对象就是自身),接下来就是每次循环的时候调用
__next__()函数来获取下一行。
next()方法时才会去获取下一个元素,这样可以避免一次性的加载很大的对象导致占用内存过多,而是在需要时才进行惰性计算
__next__()方法一次,生成一个元素,顾名思义叫做生成器。
def fibonacci_fun(num):
numlist = [0,1]
for i in range(num-1):
numlist.append(numlist[-2]+numlist[-1])
return numlist[1:]
res = fibonacci_fun(100000)
for i in res:
print(i)
class Fibonacci_Iterator:
def __init__(self,counts):
self.start = 0
self.end = 1
self.counts = counts
self.time = 0
def __iter__(self):
return self
def __next__(self):
if self.time >= self.counts:
raise StopIteration
else:
self.time += 1
self.start,self.end = self.end,self.start + self.end
return self.start
f_iter = Fibonacci_Iterator(100000)
for i in f_iter:
print(i)
def fibonacci_generator(counts):
start = 0
end = 1
for _ in range(counts):
start,end = end,end+start
yield start
f_gene = fibonacci_generator(100000)
for i in f_gene:
print(i)
__next__()方法时才求解;
__next__()启动生成器的时候会在暂停的位置继续往下执行

yuefeiyu1024
添加作者微信加入专属学习交流群,获取更多干货秘籍
文章转载自python玩转自动化运维,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
