




了解sqlite zstd,这是一个Rust库,它可以将数据库压缩很多倍,从而大大节省了数据库的大小,同时保留了其完整的搜索功能。
正如“赞扬SQLite”中指出的,SQLite不是一个玩具数据库:
尽管SQLite的规模很小,而且没有客户机-服务器模型,但它是一个RDBMS,具有使某些东西成为关系的所有特性,即表、索引、约束、触发器、事务等。然而,与PostgreSQL或Oracle相比,内置函数很少。
SQLite没有任何压缩功能。基于Rust的库sqlite zstd改变了这一点,它承诺:
提供透明的基于字典的行级压缩,允许压缩sqlite数据库的条目,就像压缩整个DB文件一样,同时保留随机访问。
只要说我们都知道压缩数据的好处就足够了,无论是PDF文档、简单的ZIP文件,还是本例中的数据库。作为该工具的概念验证和演练,我将使用Joplin笔记应用程序使用的示例数据库。我们可以使用Windows,因为它提供了更直观的体验。
示例数据库。sqlite的大小为2.6GB。有人会说,“你有什么样的笔记占据了这么多的空间?”确实,这个数字听起来有些夸张。这是因为Joplin允许您抓取遇到的任何网页,并将其作为markdown存储在数据库中。因为我是一个兴趣广泛的人,当我发现一些有趣的东西时,我会保存一份。因此,我转储到Joplin的页面数量不断增加,数据库的大小也随之增加。因此,sqlite zstd是天赐良机。当然,您的用例可能不同;该库的主要用例示例在线展示了以JSON格式压缩包含700万个图书条目的数据库,并将其大小从2.2GB减少到550KB!
但为了实现这一点,第一个障碍是找到sqlite的CLI的64位版本sqlite3,因为官方构建仅提供32位版本,而且由于zstd是一个64位库,因此需要相应的版本。虽然您可以手动构建它,但当有人已经为您完成了时,为什么还要麻烦呢?跳到SQLite shell builder Github repo并下载最新的64位Windows版本(Ubuntu、MacOS)。
掌握了CLI之后,就可以执行它来加载库和示例数据库了。之后,我们将启用“body”列的透明行级压缩,该列保留“notes”表的大部分文本。也就是说,您可以在同一个表中多次调用透明行级压缩函数,并使用不同的列进行压缩。
SELECT zstd_enable_transparent('{"table": "objects", "column": "data1", "compression_level": 19, "dict_chooser": "''a''"}'),复制
调用的结果是,表将重命名为“table_name_zstd”,而“table name”将成为一个可以正常查询的视图,包括SELECT、INSERT、UPDATE和DELETE查询。请记住,该函数本身不会压缩任何数据,您需要在之后调用zstd_incremental_maintenance。
当压缩处于活动状态时,以下差异适用:
-
压缩列可能仅包含blob或文本数据,这取决于声明的数据类型的关联性(例如,VARCHAR(10)可以,但int不可以)。
-
任何行的主键都不能为空,否则更新可能无法按预期工作,sqlite3_changes()将返回0以修改查询(请参见此处)。
-
SQLite流式blob读取API将有些无用,因为blob已完全复制到内存中。
-
使用ATTACH’foo附加包含压缩表的数据库。不支持db。
-
DDL语句(如ALTER TABLE和CREATE INDEX)仅部分受支持
此外,“dict_chooser”是一个SQL表达式,用于决定如何划分数据。分区键示例:

我使用了最简单的“a”,这意味着所有行都用同一个字典压缩。
现在在代码中:
$ sqlite3 sqlite> #opening database .open database.sqlite #loading extension .load sqlite_zstd #enabling enabling transparent row-level compression select zstd_enable_transparent('{"table": "notes", "column": "body", "compression_level": 19, "dict_chooser": "''a''"}'); Unfortunately I got an error back : Runtime error: Could not create insert trigger Caused by: 0: near "order": syntax error 1: Error code复制
启用库的调试日志可以揭示隐藏的内容(为简洁起见,删除了许多列):
[2022-08-22T16:57:46Z INFO sqlite_zstd::create_extension] [sqlite-zstd] initialized sqlite> select zstd_enable_transparent('{"table": "notes", "column": "body", "compression_level": 19, "dict_chooser": "''a''"}'); [2022-08-22T16:57:59Z DEBUG sqlite_zstd::transparent] cols=[ColumnInfo { name: "id", coltype: "TEXT", is_primary_key: true, to_compress: false, is_dict_id: false }, ColumnInfo { name: "parent_id", coltype: "TEXT", is_primary_key: false, to_compress: false, is_dict_id: false }, ColumnInfo { name: "title", coltype: "TEXT", is_primary_key: false, to_compress: false, is_dict_id: false }, ColumnInfo { name: "*body", coltype: "TEXT", is_primary_key: false, to_compress: true, is_dict_id: false }, ColumnInfo { name: "order", }] [2022-08-22T16:57:59Z DEBUG sqlite_zstd::transparent] [run] alter table `notes` rename to `_notes_zstd` [2022-08-22T16:57:59Z DEBUG sqlite_zstd::transparent] [run] create view `notes` as select `id`, `parent_id`, `title`, zstd_decompress_col(`body`, 1, `_body_dict`, true) as `body`, `created_time`, `updated_time`, `is_conflict`, `latitude`, `longitude`, `order`, `master_key_id` from `_notes_zstd` [2022-08-22T16:57:59Z DEBUG sqlite_zstd::transparent] [run] create trigger `notes_insert_trigger` instead of insert on `notes` for each row begin insert into `_notes_zstd`(id, parent_id, title, body, _body_dict, created_time, order, user_created_time, user_updated_time) select new.`id`, new.`parent_id`, new.`title`, new.`body` as `body`, null as `_body_dict`, new.`created_time`,`, new.`application_data`, new.`order`, new.`user_created_time`, end;复制
经过一些挖掘,我了解到无引号的订单条目被认为是保留的SQL字,因此是错误。将order更改为“order”使SQL Create Trigger语句通过。当然,这是一个边缘情况,因为Joplin应用程序正在使用特殊的列名,如果它是另一个应用程序,我甚至可能没有注意到。但是在任何情况下,引用机制应该是固定的库端,因此我在GitHub repo上打开了一个问题。
在修复并发布新版本之前,您可以做什么?我重命名了该列以使其通过:
alter table notes rename 'order' to 'test'复制
然后再次运行sqlite_zstd::transparent,它现在运行到完成。
如前所述,sqlite_zstd::transparent只启用压缩。实际工作由以下人员完成:
select zstd_incremental_maintenance(null, 1);复制
然后:
vacuum;复制
以便回收自由空间。
在完成操作所需的几分钟后,让我们观察一下增益。从2663996 KB的原始大小增加到1912900 KB。也就是说,不需要调整设置和使用默认字典选择器。不错!
让我们看看搜索是否也有效:
select * from notes where body like 'python%' limit 1 ;复制
压缩使您能够通过减少数据库的大小来节省存储空间,但它会影响性能,因为在访问数据时必须对数据进行压缩和解压缩。因此,无论何时访问数据库,都必须加载库。例如,让我们看看Joplin在尝试加载压缩数据库时的行为(假设对order列进行重命名,并且“notes”已成为视图而不是表),它不会影响其功能。

是的,没有这样的功能。我仍然可以通过CLI对它运行SQL查询。
额外材料
通过使用Db browser for SQLite,您可以轻松地完成同样的工作,并且基于GUI,而不是摆弄sqlite3 CLI。只需通过GUI加载数据库和扩展。然后在它上运行SQL。
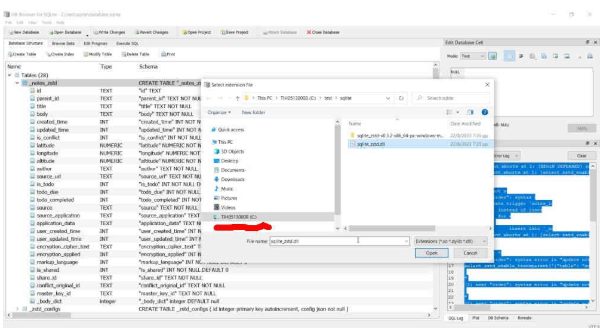
这里的主要结论是,任何可以侧面加载该库的应用程序都可以将其数据库的大小减少50%到95%,同时不影响其基本功能。当然,性能影响是存在的,但考虑到大多数操作仍然以每秒50k以上的速度运行,您可能会遇到其他瓶颈。
还有其他优化要做,但同样的方法也适用于其他数据库,比如说PostgreSQL几乎不需要任何修改。
这是对数据库技术状态产生更大影响的开端吗?
原文标题:Use Rust To Reduce The Size Of Your SQLite Database
原文作者:Nikos Vaggalis
原文链接:https://www.i-programmer.info/programming/database/15686-use-rust-to-reduce-the-size-of-your-sqlite-database-.html
