




DSE精选文章
Set-Based Adaptive Distributed Diferential Evolution for Anonymity-Driven Database Fragmentation
文章介绍
数据库碎片可以通过打破属性之间的敏感关联来保护外包数据存储的隐私。数据库碎片算法需要先验知识处理数据库中的敏感关联,因此这些算法的有效性受到先验知识的限制。受匿名技术中匿名度度量的启发,该文提出了一种基于集合的自适应分布式差分进化(S-ADDE)算法,用于解决匿名驱动的数据库碎片问题。S-ADDE中的个体代表数据库分片的解,每个解的匿名度设置为个体的ftness值。S-ADDE中个体的更新反映了数据库碎片化匿名度的增加。此外,该文的主要贡献如下:
1.为了保证种群的多样性,该文采用包含四个亚种群的岛屿模型;
2.该文提出了两种基于集合的算子,即基于集合的变异算子和基于集合的交叉算子,将传统差分进化中的连续域转移到数据库碎片问题中的离散域;
3.在基于集合的变异算子中,每个个体的变异策略根据进化性能自适应选择;
4.实验结果表明,该文提出的S-ADDE明显优于文中比较的方法,验证了提出的算子的有效性。
实验效果
如图1所示,描述了一个样本数据库,包含九个属性和六个记录。其中数据库分为三个片段,这三个片段构成图底部所示的片段解决方案。所提出的S-ADDE算法中的每个个体代表一个数据库碎片解决方案。因此,个体中的每个位表示数据库中的一个属性,其值表示选择相应属性进行分配的片段。
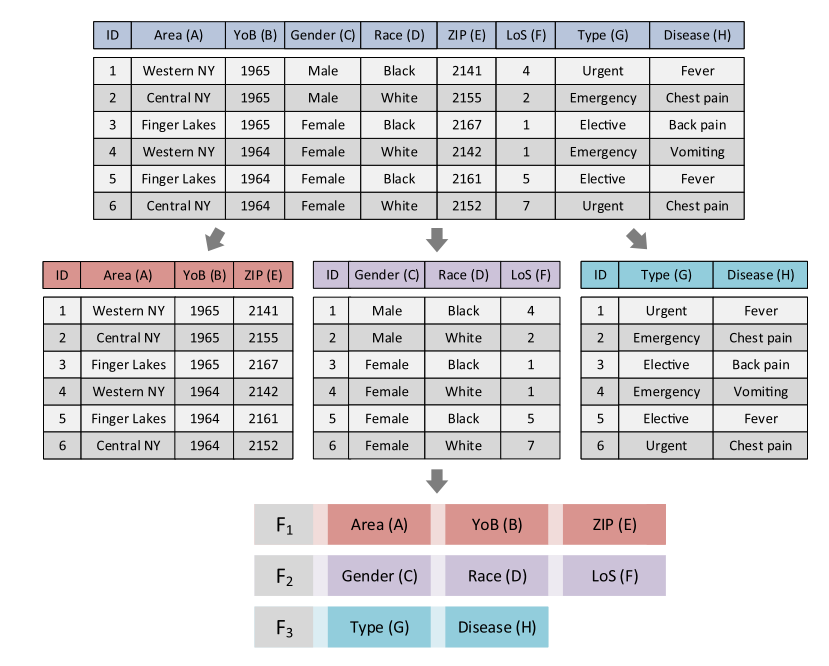
图1. S-ADDE算法中的个体表示的示例
如图2所示,描述了岛屿模型的一个示例,其中每个大圆表示一个子种群。在大圆中,小三角形和圆代表最好的个体和个体其他亚群体个体。子种群中的最佳个体以预定义的迁移间隔被发送到通信拓扑上的邻域子种群。然后,随机选择每个子群体中的一个个体,并由接收到的精英个体代替。
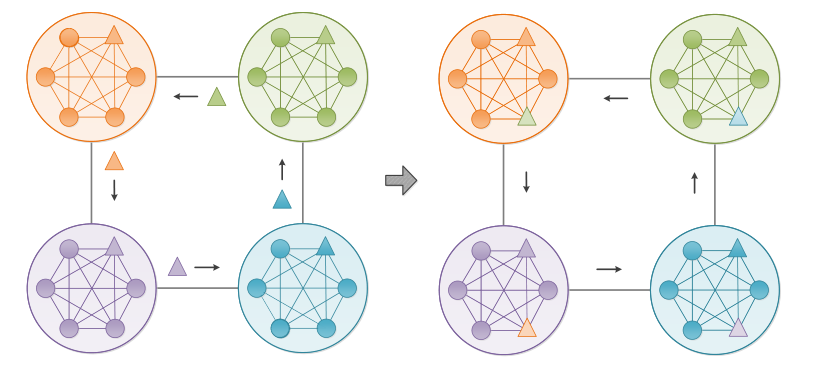
图2. S-ADDE算法中的孤岛模型的示例
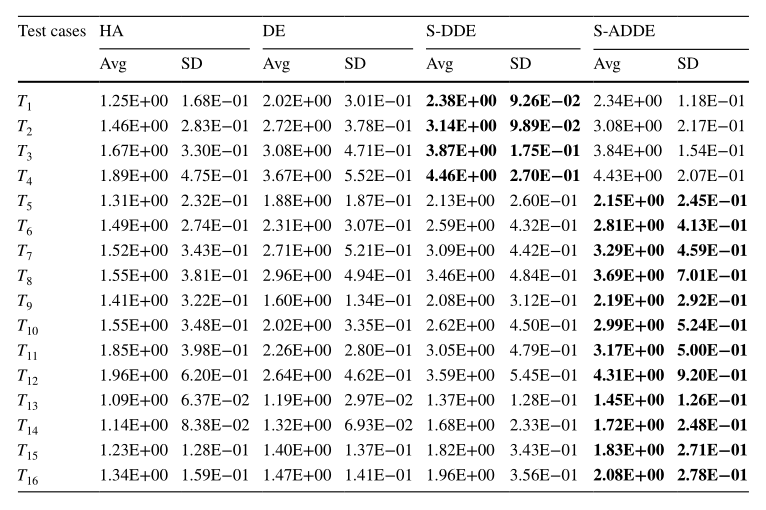
如表1所示,描述了其他方法在实验中获得的平均值和标准偏差值,最佳结果用黑体标出。可以看到,S-ADDE算法在所有测试用例上都优于其他方法,可以在探索性搜索和开发性搜索之间实现更好的平衡。但是在复杂的测试用例(如和)中,S-ADDE更容易陷入局部最优。
表1. S-ADDE算法与其他方法的比较
如图3所示,描述了四个典型测试用例的收敛曲线。其中,HA是一种针对数据库碎片问题的最先进的启发式算法,DE用作基线算法,S-DDE算法中数据库碎片问题通过基于集合的变异和交叉算子进行优化。
一开始,这三种算法都收敛得很快。HA很快陷入局部最优并停滞。由于DE和S-ADDE的探索能力,它们可以在搜索过程中不断提高匿名度。S-ADDE的绿线和DE的红线之间的差异验证了孤岛模型和所提出的基于集合的算子在S-ADDE中的有效性。
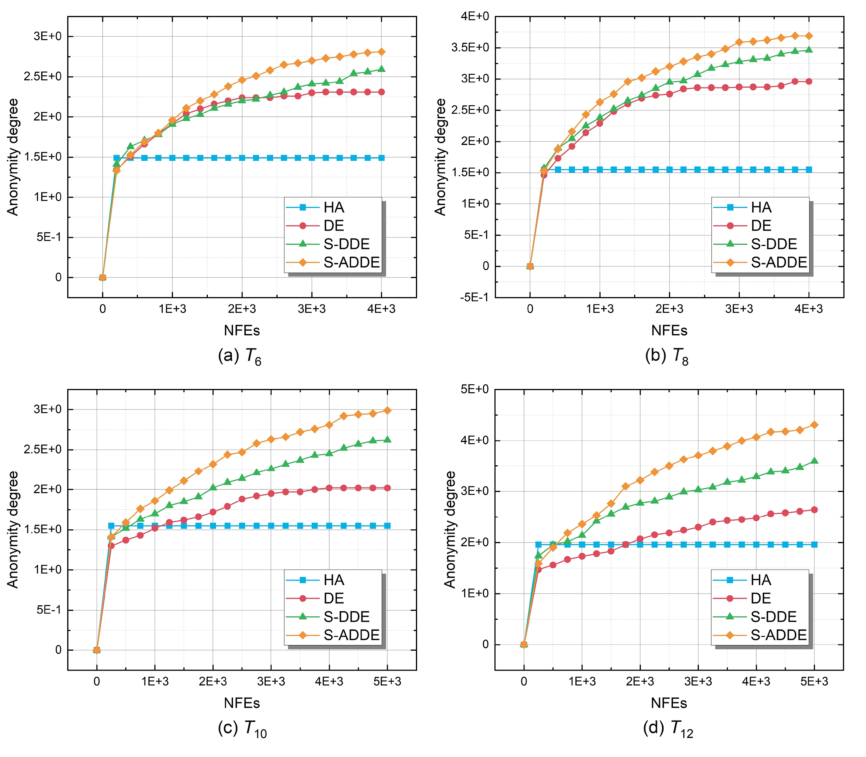
图3. 四个典型测试用例上竞争方法的收敛曲线
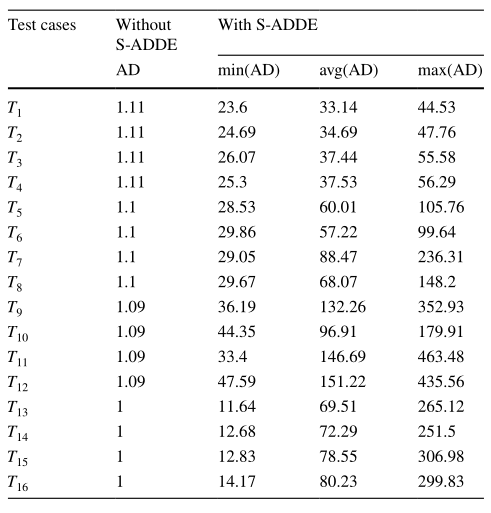
如表2所示,描述了S-ADDE算法结果对原始数据集的影响。其中,AD表示每个数据集的匿名程度,min(AD)、avg(AD)和max(AD)表示由S-ADDE中的片段获得的匿名度的最小值、平均值和最大值。
表2. S-ADDE结果对原始数据集的影响
如图4所示,描述了16个测试用例的S-ADDE加速比。随着S-ADDE的并行粒度不断增加,加速比也显著增加。不同测试用例中的加速比曲线各不相同,这是因为不同的测试用例具有不同的复杂性,需要不同的评估时间。
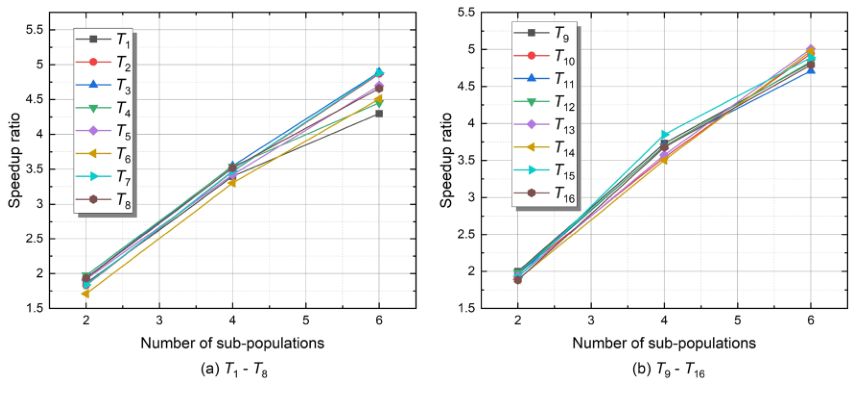
图4. 所有测试用例的S-ADDE加速比
结语
该文定义了一个匿名驱动的数据库碎片问题。为了解决这个问题,该文提出了S-ADDE 算法。S-ADDE算法利用孤岛模型来提高种群多样性,这在复杂性高的搜索问题中至关重要。该文提出了两种基于集合的算子,即具有自适应变异策略选择的基于集合的变异算子和基于集合的交叉算子。S-ADDE的计算效率验证了所提出算子的有效性。此外,该文对数据库分片的隐私问题(即匿名度)进行了优化。在未来工作中,作者计划进一步研究和优化数据库碎片的效用问题。
作者简介





期刊简介



