




作为学院派的数据库,postgresql在底层的架构设计上就考虑了很多算法层面的优化。其中在postgresql9.6版本中推出bloom索引也是十足的黑科技。
Bloom索引来源于1970年由布隆提出的布隆过滤器算法,布隆过滤器用于检索一个元素是否在一个集合中,它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。了解bloom索引前先来看看布隆过滤器的实现。
简单来说,布隆过滤器包含两部分:k个随机哈希函数和长度为m的二进制位图。
我们一般就把这个二进制位图叫做布隆过滤器,位图长度为m位,每位的值为0或1,它的实现是通过对输入进行哈希,得到的哈希值对位图长度m进行取余,落在位图的哪个地址就将该位置对应的bit位置为1,然后对给定输入按同样hash算法找到位图中的对应位置,如果位置是1代表匹配成功,为0匹配失败。因为位图长度有限,会存在hash碰撞的问题,所以匹配位置为1代表该元素很可能存在,为0代表该元素一定不存在。
那么怎么降低哈希碰撞的概率呢,一方面可以增加位图的长度m,另一方面可以通过多个(k个)哈希函数哈希到位图上的k个位置,如果在匹配时k个位置所有值都是1则代表很可能匹配到,如果k个位置上存在一个为0,那么代表该元素一定不在集合中。如下图所示:
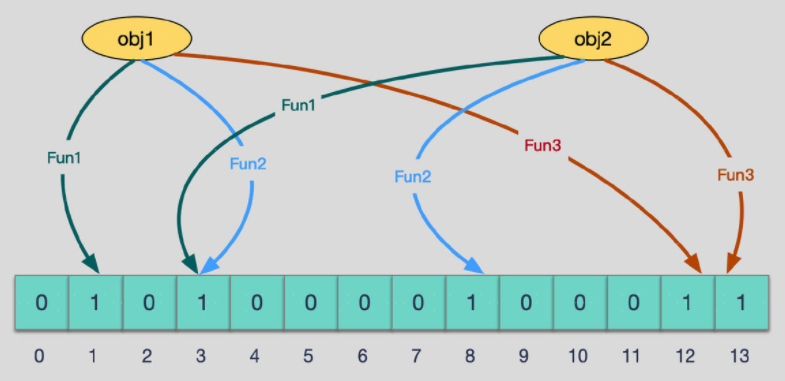
布隆过滤器相比其他数据结构,在空间和时间复杂度上都有巨大优势,在插入和查询的时候都只需要进行k次哈希匹配,因此时间复杂度是常数O(K),但是算法这东西有利有弊,鱼和熊掌不可兼得,劣势就是无法做到精确。
从上面的原理可以看到布隆过滤器一般比较适用于快速剔除未匹配到的数据,这样的话其实很适合用在数据库索引的场景上。pg在9.6版本支持了bloom索引,通过bloom索引可以快速排除不匹配的元组。
Bloom索引一般用于大宽表多字段的等值查询。对于pg来说,由于bloom索引的非精确性,索引未匹配到的行一定不存在,可以直接排除,匹配到的行可能不存在,所有对于bloom索引匹配到的行,需要再次回表确认,细想会发现这个代价相比多个btree索引在空间和时间上都有很大的提升。
在pg中,对每个索引行建立了单独的过滤器,也可以叫做签名,索引中的每个字段构成了每行的元素集。较长的签名长度对应了较低的误判率和较大的空间占用,选择合适的签名长度来在误判率和空间占用之间进行平衡。我们甚至可以认为bloom索引其实还是一种顺序扫描,只是它加速了顺序扫描的过程,能够快速的排除不匹配的行。
下面做个试验
test=# create table test(c1 int,c2 int,c3 int,c4 int,c5 int);CREATE TABLEtest=# insert into test select random()*10000 as c1,random()*10000 as c2,random()*10000 as c3,random()*10000 as c4,random()*10000 as c5 from generate_series(1,10000000);INSERT 0 10000000
顺序扫描:
test=# explain analyze select * from test where c1=3 and c2=3;QUERY PLAN-----------------------------------------------------------------------------------------------------------------------Gather (cost=1000.00..152931.41 rows=1 width=20) (actual time=696.915..946.627 rows=1 loops=1)Workers Planned: 1Workers Launched: 1-> Parallel Seq Scan on test (cost=0.00..151931.31 rows=1 width=20) (actual time=808.900..925.861 rows=0 loops=2)Filter: ((c1 = 3) AND (c2 = 3))Rows Removed by Filter: 5000000Planning Time: 0.111 msExecution Time: 946.671 ms(8 rows)
Btree索引:
test=# create index on test(c1,c2,c3,c4,c5);CREATE INDEXtest=# \di+List of relationsSchema | Name | Type | Owner | Table | Persistence | Size | Description--------+-------------------------+-------+----------+-------+-------------+--------+-------------public | test_c1_c2_c3_c4_c5_idx | index | postgres | test | permanent | 386 MB |(1 row)
条件含c1列很快
test=# explain analyze select * from test where c1=3 and c2=3;QUERY PLAN------------------------------------------------------------------------------------------------------------------------------------Index Only Scan using test_c1_c2_c3_c4_c5_idx on test (cost=0.43..4.45 rows=1 width=20) (actual time=0.173..0.176 rows=1 loops=1)Index Cond: ((c1 = 3) AND (c2 = 3))Heap Fetches: 0Planning Time: 0.380 msExecution Time: 0.205 ms(5 rows)
条件不含c1列走了顺序扫描
test=# explain analyze select * from test where c2=20 and c3=20;QUERY PLAN-----------------------------------------------------------------------------------------------------------------------Gather (cost=1000.00..152930.39 rows=1 width=20) (actual time=675.131..750.229 rows=1 loops=1)Workers Planned: 1Workers Launched: 1-> Parallel Seq Scan on test (cost=0.00..151930.29 rows=1 width=20) (actual time=701.320..730.440 rows=0 loops=2)Filter: ((c2 = 20) AND (c3 = 20))Rows Removed by Filter: 5000000Planning Time: 0.291 msExecution Time: 750.268 ms(8 rows)
Bloom索引:(需要先安装bloom插件,禁用seqscan)
test=# create index on test using bloom(c1,c2,c3,c4,c5);CREATE INDEXtest=# set enable_indexscan =off;SETtest=# set enable_seqscan =off;SET
条件含c1很快
test=# explain analyze select * from test where c1=3 and c2=3;QUERY PLAN--------------------------------------------------------------------------------------------------------------------------------Bitmap Heap Scan on test (cost=4.45..8.46 rows=1 width=20) (actual time=0.045..0.047 rows=1 loops=1)Recheck Cond: ((c1 = 3) AND (c2 = 3))Heap Blocks: exact=1-> Bitmap Index Scan on test_c1_c2_c3_c4_c5_idx (cost=0.00..4.44 rows=1 width=0) (actual time=0.029..0.030 rows=1 loops=1)Index Cond: ((c1 = 3) AND (c2 = 3))Planning Time: 0.155 msExecution Time: 0.098 ms(7 rows)
条件不含c1也很快
test=# explain analyze select * from test where c2=3 and c3=3;QUERY PLAN------------------------------------------------------------------------------------------------------------------------------------------Bitmap Heap Scan on test (cost=178436.00..178440.02 rows=1 width=20) (actual time=74.680..74.681 rows=0 loops=1)Recheck Cond: ((c2 = 3) AND (c3 = 3))Rows Removed by Index Recheck: 1042Heap Blocks: exact=1033-> Bitmap Index Scan on test_c1_c2_c3_c4_c5_idx (cost=0.00..178436.00 rows=1 width=0) (actual time=72.545..72.546 rows=1042 loops=1)Index Cond: ((c2 = 3) AND (c3 = 3))Planning Time: 0.189 msExecution Time: 74.725 ms(8 rows)
而bloom索引大小还不到btree大小的一半
test=# \di+List of relationsSchema | Name | Type | Owner | Table | Persistence | Size | Description--------+--------------------------+-------+----------+-------+-------------+--------+-------------public | test_c1_c2_c3_c4_c5_idx | index | postgres | test | permanent | 153 MB |public | test_c1_c2_c3_c4_c5_idx1 | index | postgres | test | permanent | 386 MB |(2 rows)
我们在bloom索引的执行计划上看到了Rows Removed by Index Recheck: 1042字样,代表了条件在位图上命中了,无法排除,需要回表进行二次确认,所以recheck的数量越少,bloom索引需要回表的次数越少,性能越高。
虽然布隆过滤器不支持删除,但是在数据库索引上不存在删除布隆过滤器上元素的场景,当某个数据行被删除时仅需要删除对应行上的整个布隆过滤器(索引行)而已。
