




一、CDC 是什么?

二、CDC 的实现原理
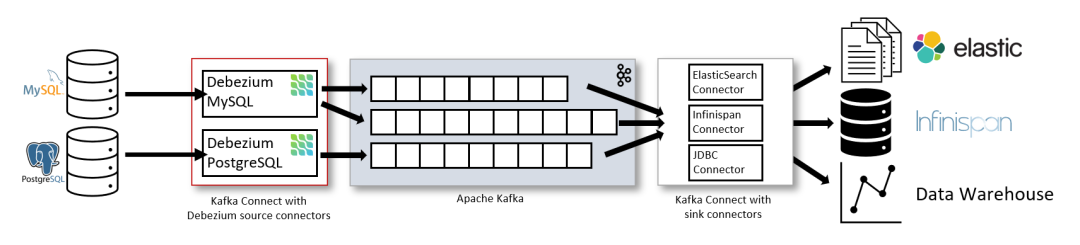
三、为什么选 Flink?
Flink 的算子和 SQL 模块更为成熟和易用
Flink 作业可以通过调整算子并行度的方式,轻松扩展处理能力
Flink 支持高级的状态后端(State Backends),允许存取海量的状态数据
Flink 提供更多的 Source 和 Sink 等生态支持
Flink 有更大的用户基数和活跃的支持社群,问题更容易解决
Flink 的开源协议允许云厂商进行全托管的深度定制,而 Kafka Streams 只能自行部署和运维
+I表示新增、
-U表示记录更新前的值、
+U表示记录更新后的值,
-D表示删除)可以与 Debezium 等生成的变动记录一一对应。
四、Flink CDC 的使用方法
(一)输入 Debezium 等数据流进行同步
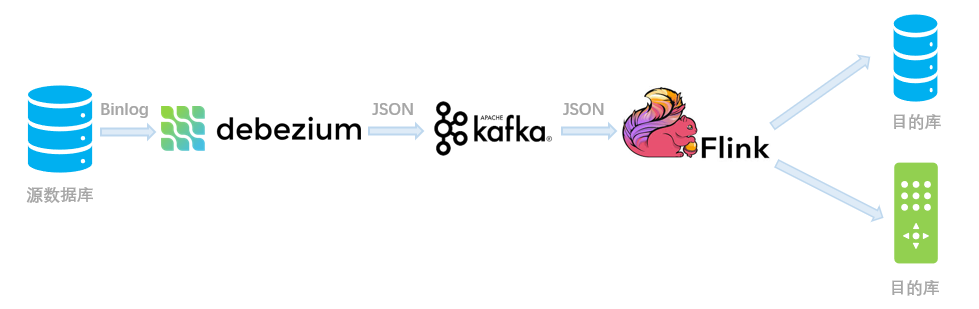
用法示例
YourDebeziumTopic的 Kafka 主题中。
CREATE TABLE `Data_Input` (id BIGINT,actor VARCHAR,alias VARCHAR,PRIMARY KEY (`id`) NOT ENFORCED) WITH ('connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector'topic' = 'YourDebeziumTopic', -- 替换为您要消费的 Topic'scan.startup.mode' = 'earliest-offset' -- 可以是 latest-offset earliest-offset specific-offsets group-offsets 的任何一种'properties.bootstrap.servers' = '10.0.1.2:9092', -- 替换为您的 Kafka 连接地址'properties.group.id' = 'YourGroup', -- 必选参数, 一定要指定 Group ID-- 定义数据格式 (Debezium JSON 格式)'format' = 'debezium-json','debezium-json.schema-include' = 'false',);CREATE TABLE `Data_Output` (id BIGINT,actor VARCHAR,alias VARCHAR,PRIMARY KEY (`id`) NOT ENFORCED) WITH ('connector' = 'jdbc','url' = 'jdbc:postgresql://postgresql.example:50060/myDatabase?currentSchema=mySchema&reWriteBatchedInserts=true', -- 请替换为您的实际 PostgreSQL 连接参数'table-name' = 'MyTable', -- 需要写入的数据表'username' = 'user', -- 数据库访问的用户名(需要提供 INSERT 权限)'password' = 'helloworld' -- 数据库访问的密码);INSERT INTO `Data_Output` SELECT * FROM `Data_Input`;复制
kafka和
jdbc两个内置的 Connector:
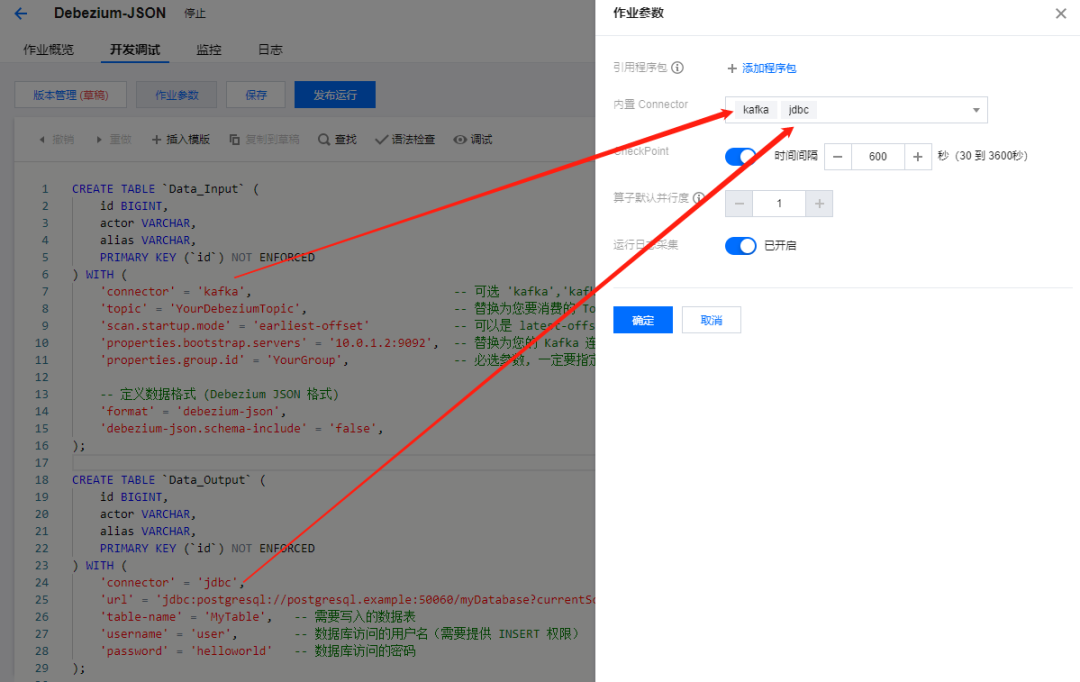
YourDebeziumTopic这个 Kafka 主题中 Debezium 写入的记录,然后输出到下游的 MySQL 数据库中,实现了数据同步。
(二)直接对接上游数据库进行同步
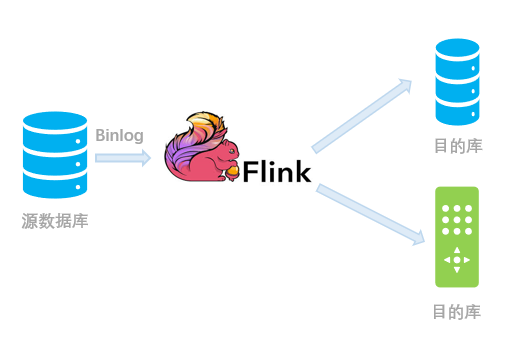
用法示例
CREATE TABLE `Data_Input` (id BIGINT,actor VARCHAR,alias VARCHAR,PRIMARY KEY (`id`) NOT ENFORCED) WITH ('connector' = 'mysql-cdc', -- 可选 'mysql-cdc' 和 'postgres-cdc''hostname' = '192.168.10.22', -- 数据库的 IP'port' = '3306', -- 数据库的访问端口'username' = 'debezium', -- 数据库访问的用户名(需要提供 SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT, SELECT, RELOAD 权限)'password' = 'hello@world!', -- 数据库访问的密码'database-name' = 'YourData', -- 需要同步的数据库'table-name' = 'YourTable' -- 需要同步的数据表名);CREATE TABLE `Data_Output` (id BIGINT,actor VARCHAR,alias VARCHAR,PRIMARY KEY (`id`) NOT ENFORCED) WITH ('connector' = 'jdbc','url' = 'jdbc:postgresql://postgresql.example:50060/myDatabase?currentSchema=mySchema&reWriteBatchedInserts=true', -- 请替换为您的实际 PostgreSQL 连接参数'table-name' = 'MyTable', -- 需要写入的数据表'username' = 'user', -- 数据库访问的用户名(需要提供 INSERT 权限)'password' = 'helloworld' -- 数据库访问的密码);INSERT INTO `Data_Output` SELECT * FROM `Data_Input`;复制
mysql-cdc和
jdbcConnector:

注意 需要使用 Flink CDC Connectors(https://github.com/ververica/flink-cdc-connectors)附加组件。腾讯云 Oceanus 已经自带了 MySQL-CDC Connector,如果自行部署的话,需要下载 jar 包并将其放入 Flink 的 lib 目录下。 访问数据库时,请确保连接的用户足够权限(PostgreSQL 用户看这里[https://debezium.io/documentation/reference/connectors/postgresql.html#postgresql-permissions],MySQL 用户看这里[https://debezium.io/documentation/reference/connectors/mysql.html#setting-up-mysql])。
五、Flink CDC 模块的实现
(一)Debezium JSON 格式解析类探秘
flink-json模块中的
org.apache.flink.formats.json.debezium.DebeziumJsonFormatFactory是负责构造解析 Debezium JSON 格式的工厂类;同样地,
org.apache.flink.formats.json.canal.CanalJsonFormatFactory负责 Canal JSON 格式。这些类已经内置在 Flink 1.11 的发行版中,直接可以使用,无需附加任何程序包。
org.apache.flink.formats.json.debezium.DebeziumJsonDeserializationSchema#DebeziumJsonDeserializationSchema类中。
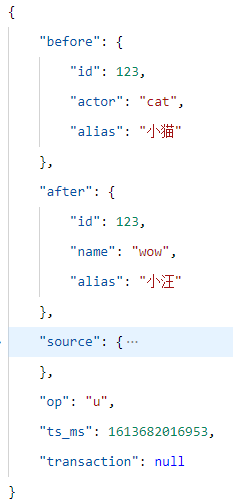
id=123的数据更新,且字段内包含了更新前的旧值,以及更新后的新值。
deserialize方法:
GenericRowData before = (GenericRowData) payload.getField(0); // 更新前的数据GenericRowData after = (GenericRowData) payload.getField(1); 更新后的数据String op = payload.getField(2).toString(); 获取 "op" 字段的类型if (OP_CREATE.equals(op) || OP_READ.equals(op)) { 如果是创建 (c) 或快照读取 (r) 消息 after.setRowKind(RowKind.INSERT); // 设置消息类型为新建 (+I) out.collect(after); // 发送给下游} else if (OP_UPDATE.equals(op)) { // 如果是更新 (u) 消息 before.setRowKind(RowKind.UPDATE_BEFORE); // 把更新前的数据类型设置为撤回 (-U) after.setRowKind(RowKind.UPDATE_AFTER); // 把更新后的数据类型设置为更新 (+U) out.collect(before); // 发送两条数据给下游 out.collect(after);} else if (OP_DELETE.equals(op)) { // 如果是删除 (d) 消息 before.setRowKind(RowKind.DELETE); // 将消息类型设置为删除 (-D) out.collect(before); // 发送给下游} else { ... // 异常处理逻辑}复制
op字段的类型),都可以用 Flink 的 RowKind 类型来表示。对于插入
+I和删除
D,都只需要一条消息即可;而对于更新,则涉及删除旧数据和写入新数据,因此需要
-U和
+U两条消息来对应。
-U消息可以省略,只把后一个
+U消息用作实际的更新操作即可,这个优化在 Flink 中也有实现。
1.Flink CDC Connectors 的实现
(1)flink-connector-debezium 模块
flink-connector-mysql-cdc的源码时,可以看到它内部依赖了
flink-connector-debezium模块,而这个模块将 Debezium Embedded(https://github.com/debezium/debezium/tree/master/debezium-embedded)嵌入到了 Connector 中。
flink-connector-debezium的数据源实现类为
com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction,它集成了 Flink 中的
RichSourceFunction并实现了
CheckpointedFunction以支持快照保存状态。
run方法入手分析。它的核心代码如下:
this.engine = DebeziumEngine.create(Connect.class) .using(properties) // 初始化 Debezium 所需的参数 .notifying(debeziumConsumer) // 收到批量的变更消息, 则 Debezium 会回调 DebeziumChangeConsumer 来反序列化并向下游输出数据 .using(OffsetCommitPolicy.always()) .using( (success, message, error) -> { if (!success && error != null) { this.reportError(error); } }) .build();... executor.execute(engine); // 向 Executor 提交 Debezium 线程以启动运行复制
Runnable),然后提交给线程池(executor)去执行。这个 Debezium 线程会批量接收 binlog 信息并回调传入的 debeziumConsumer 以反序列化消息并交给 Flink 来处理。本类的其他方法主要负责初始化状态和保存快照,这里略过。
DebeziumChangeConsumer的实现,它的最核心的方法是
handleBatch。当 Debezium 收到一批新的事件时,会调用这个方法来通知我们的 Connector 进行处理。这里有个 for 循环轮询的逻辑:
for (ChangeEvent<SourceRecord, SourceRecord> event : changeEvents) { // 轮询各个事件SourceRecord record = event.value();if (isHeartbeatEvent(record)) { // 如果时心跳包// 只更新当前 offset 信息, 然后继续(不进行实际处理)synchronized (checkpointLock) {debeziumOffset.setSourcePartition(record.sourcePartition());debeziumOffset.setSourceOffset(record.sourceOffset());}continue;}deserialization.deserialize(record, debeziumCollector); // 反序列化这条消息if (isInDbSnapshotPhase) { // 如果处于数据库快照期, 需要阻止 Flink 检查点(Checkpoint)生成if (!lockHold) {MemoryUtils.UNSAFE.monitorEnter(checkpointLock);lockHold = true;...}if (!isSnapshotRecord(record)) { // 如果已经不在数据库快照期了, 就释放锁, 允许 Flink 正常生成检查点(Checkpoint)MemoryUtils.UNSAFE.monitorExit(checkpointLock);isInDbSnapshotPhase = false;...}}// 更新当前 offset 信息, 并向下游 Flink 算子发送数据emitRecordsUnderCheckpointLock(debeziumCollector.records, record.sourcePartition(), record.sourceOffset());}复制
checkpointLock这个对象:只有持有这个对象的锁时,才允许 Flink 进行检查点的生成。
SnapshotRecord),则不允许 Flink 进行 Checkpoint 即检查点的生成,以避免作业崩溃恢复后状态不一致;同样地,如果正在向下游算子发送数据并更新 offset 信息时,也不允许快照的进行。这些操作都是为了保证 Exacly-Once(精确一致)语义。
(2)flink-connector-mysql-cdc 模块
flink-connector-mysql-cdc模块而言,它主要涉及到 MySQLTableSource 的声明和实现。
src/main/resources/META-INF/services/org.apache.flink.table.factories.Factory文件,里面内容指向
com.alibaba.ververica.cdc.connectors.mysql.table.MySQLTableSourceFactory。
MySQLTableSource实例的具体创建,而
MySQLTableSource类对这些参数做转换,最终会生成一个上文提到的
DebeziumSourceFunction对象。
flink-connector-debezium完成的。
六、MySQL CDC 常见问题&优化
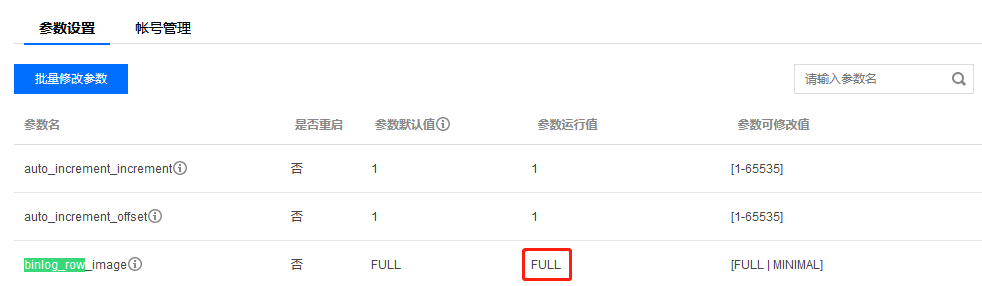
Debezium 报错:binlog probably contains events generated with statement or mixed based replication format
STATEMENT或者
MIXED, 这两种都不被 Debezium 支持。为了使用 Flink CDC 功能,需要把 MySQL 的
binlog-format设置为
ROW:
SET GLOBAL binlog_format = 'ROW';SET GLOBAL binlog_row_image = 'FULL';复制
Debezium 报错:User does not have the 'LOCK TABLES' privilege required to obtain a consistent snapshot 或 Access denied; you need (at least one of) the SUPER, REPLICATION CLIENT privilege(s)
SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT,例如:
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO '用户名' IDENTIFIED BY '密码';FLUSH PRIVILEGES;复制
RELOAD进行全局锁,则还需要授予
LOCK TABLES权限以令 Debezium 尝试进行表级锁。注意,表级锁会导致更长的数据库锁定时间!
'debezium.snapshot.locking.mode' = 'none'参数来跳过锁操作。但请注意,同步过程中千万不要随意变更库表的结构。
作业刚启动期间,Flink Checkpoint 一直失败/重启
execution.checkpointing.tolerable-failed-checkpoint参数以容忍更多的 Checkpoint 失败事件,同时可以调大 Checkpoint 周期,避免作业因 Checkpoint 失败而一直重启。
JDBC Sink 批量写入时,数据会缺失几条
connector.type是旧语法[https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/connect.html#jdbc-connector],
connector是新语法[https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/connectors/jdbc.html#how-to-create-a-jdbc-table])。
异常数据造成作业持续重启
WITH参数中加入
'debezium-json.ignore-parse-errors' = 'true'来应对这个问题。
上游 Debezium 崩溃导致写入重复数据,结果不准
table.exec.source.cdc-events-duplicate配置项(可以编辑
flink-conf.yaml文件来配置),建议将其设置为
true以对这些重复数据进行去重。
七、未来展望
table.exec.source.cdc-events-duplicate等选项以更好地支持 CDC 去重;还支持 Avro 格式的 Debezium 数据流,而不仅仅限于 JSON 了。另外,这个版本增加了对 Maxwell(https://maxwells-daemon.io/)格式的 CDC 数据流支持,
文章转载自腾讯云数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
