




KDD 2022 | Model Degradation Hinders Deep Graph Neural Networks
文章信息
「来源」:Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2022)
「标题」:Model Degradation Hinders Deep Graph Neural Networks
「作者」:Wentao Zhang, Zeang Sheng, Ziqi Yin, Yuezihan Jiang, Jun Gao, Bin Cui
「链接」:https://dl.acm.org/doi/10.1145/3534678.3539374
摘要
图神经网络 (GNN) 在各种图挖掘任务中取得了巨大成功。然而,当 GNN 堆叠多层时,总是会观察到性能急剧下降。因此,大多数 GNN 只有浅层架构,这限制了它们的表达能力和对深层邻域的利用。最近的研究将深度 GNN 的性能下降归因于过度平滑问题。在本文中,作者将传统的图卷积操作分解为两个独立的操作:传播(P)和变换(T)。在此之后,GNN 的深度可以分为传播深度 Propagation Depth() 和变换深度 Transformation Depth()。本文对深度 GNN 中的过度平滑问题进行了全面分析,并试图找出深度 GNN 性能下降的主要原因。「本文发现过度平滑问题确实发生在数十次 P 操作之后,但深度 GNN 的性能下降远早于过度平滑问题的出现」。因此,过度平滑问题并不是深度 GNN 性能下降的主要原因。
通过大量实验,本文发现「深度 GNN 性能下降的主要原因是larger 引起的模型退化问题」,而不是主要由larger 引起的过度平滑问题。「此外,本文提出了自适应初始残差 (AIR),这是一个与各种 GNN 架构兼容的即插即用模块,以同时缓解模型退化问题和过度平滑问题。」 六个真实世界数据集的实验结果表明,由于larger 和 的优势,配备 AIR 的 GNN 优于大多数具有浅层架构的 GNN,而与 AIR 相关的时间成本可以忽略不计。
过度平滑问题的实证分析
平滑度测量
平滑度衡量图中节点对之间的相似性。「具体来说,较高的平滑度表明从给定节点集中随机选取的两个节点相似的概率较高」。本文定义“Node Smoothness Level (NSL)”和“Graph Smoothness Level (GSL)”如下:
「节点平滑度测量(Node Smoothness Level)」节点 的节点平滑级别 定义为:
「图平滑度测量(Graph Smoothing Level)」整个图的 Graph Smoothing Level 定义为:
回顾过度平滑问题
过度平滑问题描述了应用 GNN 模型后节点的输出表示变得无法区分的现象。当 GNN 模型堆叠多层时,总是会出现过度平滑的问题。在 GCN 采用的传统 PTPT 架构中, 和 被限制为具有相同的值。然而,在本文解开图卷积运算之后,分析仅放大或所带来的各自影响是可行的。在下面的分析中,本文将证明一个巨大的是出现过度平滑问题的真正原因。
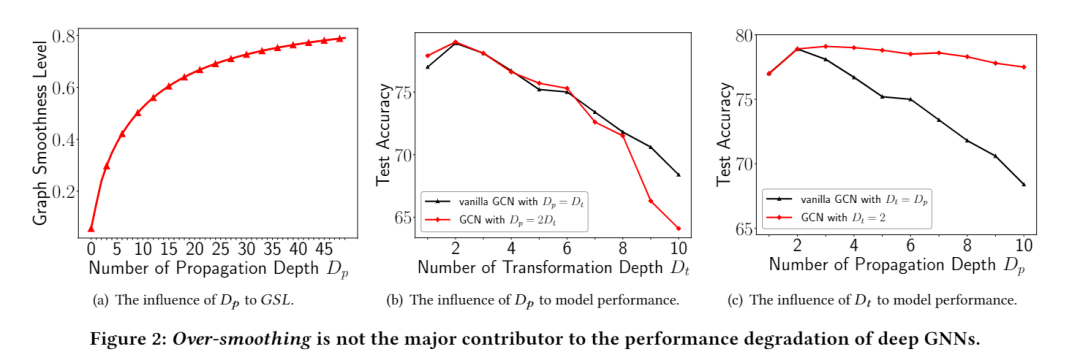
「放大」如果无限次地应用 P 操作,同一连接组件内的节点表示将达到静止状态,从而导致无法区分的输出。具体来说,当采用 时, 如下:
这表明当接近时,节点对节点的影响仅取决于它们的节点度数。相应地,每个节点的唯一信息被完全平滑,导致无法区分的表示,即过度平滑问题。
「放大」扩大非线性变换的数量 对过度平滑问题的出现没有直接影响。为了支持这一说法,本文在流行的 Cora 数据集上评估了完全解开的 PPTT GNN 模型 SGC 和相应的 𝐺𝑆𝐿 的分类准确度。本文放大了 SGC 的 ,同时修复了它的 𝐷𝑝 = 3,以排除 姿势对输出的影响。下图实验结果表明,𝐺𝑆𝐿 仅在很小的区间内波动。没有迹象表明仅当 增加时会发生过度平滑问题。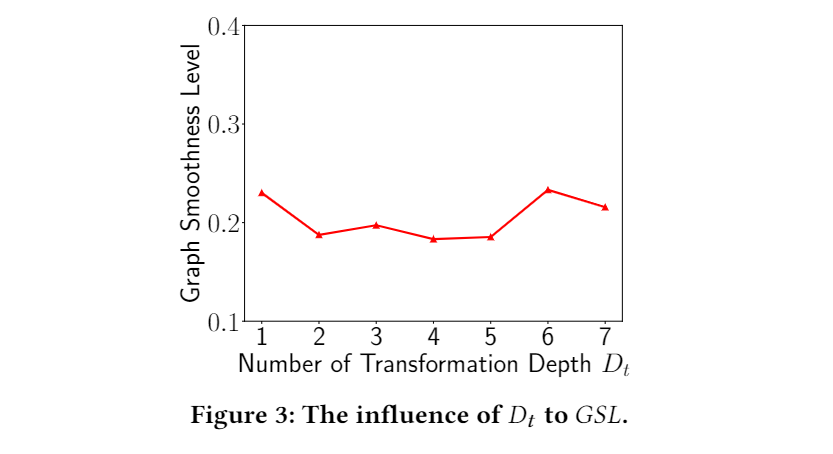
过度平滑是主要原因吗?
大多数先前的研究声称过度平滑问题是深度 GNN 失败的主要原因。已经有一系列旨在设计深度 GNN 的工作。例如,DropEdge 在训练期间随机删除边缘,而 Grand 在传播之前随机删除节点的原始特征。尽管它们能够深入研究,同时保持甚至达到更好的预测精度,但对其有效性的解释在某种程度上是误导性的。
「larger 𝐷𝑡 导致性能下降」如下图的实验结果,“GCN with 𝐷𝑡 = 2”的准确率确实随着𝐷𝑝的增长而下降,但下降幅度相对较小,而普通 GCN(固定 = )的准确率则面临急剧下降。因此,可以推断,尽管如之前的分析所示,单独放大会增加出现过度平滑问题的风险,但性能仅受到轻微影响。但是,如果同时增加,性能将急剧下降。
自适应初始残差(AIR)
在解开图卷积操作之后,几乎所有的 GNN 都可以分割成连续的部分,其中每个部分都是连续的P操作或T操作的序列。
「P 操作之间」对于一系列连续的 P 操作,本文在每个 P 操作中提取节点 的输入特征 的自适应部分。将节点 在第 次操作中的表示表示为 。然后,在第 次操作中节点 的自适应分数 计算如下:
「T 操作之间」与 P 操作之间的自适应初始残差连接不同,T 操作之间的连接不包括输入特征的可学习系数,而是采用固定的连接,因为这两种方式在这种情况下几乎是等价的。与上面介绍的 P 运算类似,对于每个 ,配备 AIR 的第 T 运算可以表述如下:
AIR 评估
本文在三种不同的 GNN 架构下评估提出的 AIR。将 AIR 应用于三种 GNN 模型:SGC (PPTT)、APPNP (TTPP) 和 GCN (PTPT),它们分别是三种 GNN 架构的代表性 GNN 模型。首先,本文介绍了使用的数据集和基线设置。然后,本文将 SGC+AIR、APPNP+AIR 和 GCN+AIR 与基线方法在预测准确性、深入能力、对图稀疏性的鲁棒性和效率方面进行比较。
实验设置
「数据集」本文采用三个流行的引文网络数据集(Cora、Citeseer、PubMed)和三个大型 OGB 数据集(ogbnarxiv、ogbn-products、ogbn-papers100M)来评估每种方法对节点分类任务的预测准确性。
「基线」本文选择以下基线:GCN、GraphSAGE、JK-Net、ResGCN、APPNP、AP-GCN、DAGNN、SGC、 SIGN、S2GC 和 GBP。
模型深度分析
如下图所示,在图(a) 中,本文固定 = 3 并将 从 1 增加到 20。图 (a) 表明 SGC+AIR 在整个实验过程中优于 SGC,并且 APPNP+AIR 的性能开始超过 APPNP 当 𝐷𝑝 超过 10 时。实验结果清楚地表明 AIR 可以显着降低出现过度平滑问题的风险。在图 (b) 中,将 固定为 10,并将 从 1 增加到 10。虽然 SGC 和 APPNP 在 超过 4 时都遇到了显着的性能下降,但 SGC+AIR 和 APPNP+AIR 的预测精度保持甚至变得更高 当增长时。这种鲜明的对比说明 AIR 可以极大地缓解模型退化问题。因此,配备 AIR、SGC 和 APPNP 可以更好地挖掘深层信息并实现更高的预测精度。在 PTPT 架构下,本文增加了 和,因为 P 和 T 操作纠缠在这个架构中。实验结果如图 (c) 所示。与基线方法 GCN、JK-Net 和 ResGCN 相比,GCN+AIR 随着层数的增加,在预测准确度上呈现出稳步上升的趋势,这再次验证了 AIR 的有效性。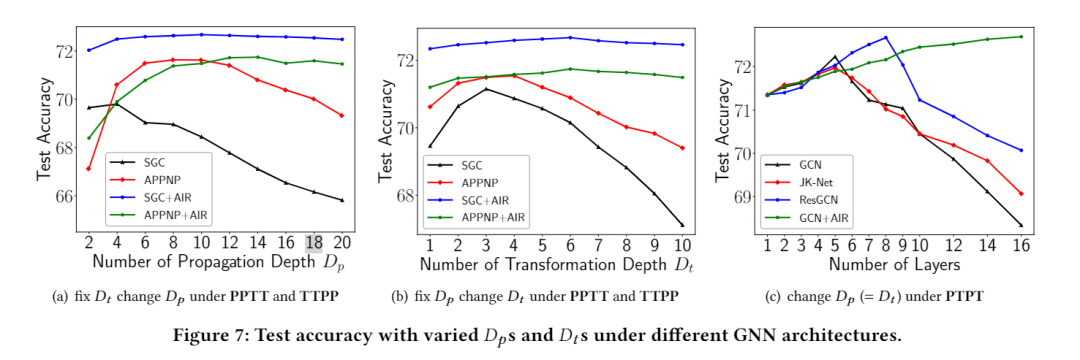
性能效率分析
如下图所示,AIR 引入的额外时间成本仅在 11% 到 26% 之间变化,具体取决于其各自原始版本的训练时间。下图表明,属于 PPTT 架构的 SGC 比属于 TTPP 的 APPNP 和 GCN 消耗的训练时间要少得多 和 PTPT 架构。
总结
本文对当前的 GNN 进行了实证分析,并找到了深度 GNN 性能下降的根本原因:large()引入的模型退化问题。larger传播深度()引入的过度平滑问题确实会损害预测准确性。然而,本文发现当和以相似的速度增加时,模型退化问题总是比过度平滑问题发生得早得多。基于上述分析,本文提出了自适应初始残差 (AIR),这是一个即插即用模块,可帮助 GNN 同时支持大传播和转换深度。对六个真实世界图形数据集的广泛实验表明,配备 AIR 的简单 GNN 方法优于最先进的 GNN 方法,并且与 AIR 相关的额外时间成本可以忽略不计。
