




KDD 2022 | Condensing Graphs via One-Step Gradient Matching
“文章信息
来源:Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2022)
”
标题:Condensing Graphs via One-Step Gradient Matching
作者:Wei Jin, Xianfeng Tang, Haoming Jiang, Zheng Li, Danqing Zhang, Jiliang Tang, Bing Yin
链接:https://dl.acm.org/doi/10.1145/3534678.3539429
摘要
由于在大型数据集上训练深度学习模型需要大量时间和资源,因此需要构建一个小的合成数据集,本文可以用它来充分训练深度学习模型。最近的一些工作探索了通过复杂的双层优化来压缩图像数据集的解决方案。例如,数据集浓缩(DC)与网络梯度相匹配,其中网络权重在每次外部迭代中针对多个步骤进行优化。但是,现有方法有其固有的局限性:(1)它们不能直接适用于数据离散的图;(2) 由于涉及嵌套优化,压缩过程的计算成本很高。
为了弥合差距,本文研究了为图数据集量身定制的有效压缩,作者将离散图结构建模为概率模型。本文进一步提出了一种一步梯度匹配方案,该方案仅对一步进行梯度匹配,无需训练网络权重。本文的理论分析表明,这种策略可以生成合成图,从而降低真实图上的分类损失。对各种图形数据集的广泛实验证明了所提出方法的有效性和效率。特别是,本文能够将数据集大小减少 90%,同时接近原始性能的 98%,并且本文的方法明显快于多步梯度匹配(例如,在 CIFAR10 中 15 倍用于合成 500 个图)。
简介
图结构数据在各种实际应用中发挥着关键作用。例如,通过利用图结构信息,可以预测给定分子图的化学性质,检测金融交易图中的欺诈活动,或向社交网络中的用户推荐新朋友。由于其普遍性,图神经网络 (GNN)已被开发以有效地从图数据中提取有意义的模式,从而极大地促进了图上的计算任务。尽管 GNN 很有效,但众所周知,它们像传统的深度神经网络一样需要大量数据:它们通常需要大量数据集来学习强大的表示。因此,训练 GNN 的计算成本通常很高。当需要重复训练 GNN 时,例如在神经架构搜索和持续学习中,这样的成本甚至变得令人望而却步。
缓解上述问题的一种潜在解决方案是数据集压缩或数据集蒸馏。它的目标是构建一个小型综合训练集,可以提供足够的信息来训练神经网络。特别是,其中一种代表性方法 DC 将浓缩目标制定为匹配小型合成和大型真实训练数据之间的网络参数梯度。已经证明,这种解决方案可以大大减少图像数据集的训练集大小,而不会显着牺牲模型性能。例如,使用 DC 生成的 100 张图像可以在 MNIST 上实现 97.4% 的测试准确率,而在原始数据集(60, 000 张图像)上的测试准确率为 99.6%。这些压缩样本可以显着节省存储数据集的空间,并加速在许多关键应用中重新训练神经网络,例如持续学习和神经架构搜索。尽管最近在图像数据集蒸馏/压缩方面取得了进展,但对涉及图结构的领域的关注有限。
为了弥合这一差距,本文研究了图压缩的问题,以便在压缩图上训练的 GNN 可以达到与在原始数据集上训练的 GNN 相当的性能。然而,直接将现有解决方案用于数据集压缩到图域面临一些挑战。首先,现有的解决方案是为数据连续的图像设计的,它们不能输出二进制值来形成离散的图结构。因此,本文需要制定一种策略来处理图的离散性。其次,它们通常涉及一个复杂的双层问题,优化计算成本很高:它们需要多次迭代(内部迭代)来更新神经网络参数,然后再更新合成数据以进行多次迭代(外部迭代)。学习节点的成对关系可能是灾难性的效率低下,其复杂性与节点的数量成二次方。
为了解决上述挑战,本文提出了一种有效的图压缩方法,本文遵循 DC 来匹配 GNN 在合成图和真实图之间的梯度。为了产生离散值,本文将图结构建模为概率图模型,并以可微分的方式优化离散结构。基于这个公式,本文进一步提出了一种一步梯度匹配策略,该策略只执行一步梯度匹配。因此,所提出的策略的优点是双重的。首先,它显着加快了凝聚过程,同时为凝聚图的合成提供了合理的指导。其次,它消除了调整超参数的负担,例如 DC 要求的双层优化的外部/内部迭代次数。此外,本文在理论上和经验上证明了所提出的一步梯度匹配策略的有效性。本文的贡献可以总结如下:
本文研究了一个新问题,即学习离散合成图以压缩图数据集,其中离散结构是通过可以以可微分方式学习的图概率模型捕获的。 本文提出了一种一步梯度匹配方案,显着加速了普通梯度匹配过程。 提供理论分析来理解所提出的一步梯度匹配的合理性。本文表明,一步匹配的学习产生合成图,导致在真实图上的分类损失更小。 大量实验证明了所提方法的有效性和效率。特别是,本文能够将数据集大小减少 90%,同时接近原始性能的 98%,并且本文的方法明显快于多步梯度匹配(例如,在 CIFAR10 中 15 倍用于合成 500 个图)。
所提框架
以梯度匹配为目标
由于本文的目标是学习信息量很大的合成图,因此一种解决方案是允许在合成图上训练的 GNN 模仿原始大型数据集上的训练轨迹。数据集浓缩引入了梯度匹配方案来实现这一目标。具体来说,它试图减少模型梯度的差异。每个训练时期的模型参数的大型真实数据和小型合成数据。因此,在每个训练时期,在合成数据上训练的模型参数将接近在真实数据上训练的模型参数。令 表示第 个时期的网络参数,而 表示由 参数化的神经网络。冷凝目标表示为:
其中是距离函数,是整个训练轨迹的步数,是更新参数的优化算子。请注意,上式是一个双层问题,需要在外部优化时学习合成图 ,在内部优化时更新模型参数 。为了学习泛化到模型参数 分布的合成图,本文对 进行采样并重写上式为:
学习离散图结构
对于图分类,数据集中的每个图由邻接矩阵和特征矩阵组成。注意 可以被实例化为任何图神经网络,它同时将图结构和节点特征作为输入。然后方程如下:
目标是学习图结构 和节点特征 。然而,上式难以优化,因为它需要一个输出二进制值的函数。为了解决这个问题,建议将图结构建模为具有伯努利分布的概率图模型:
One-Step梯度匹配
为了解决上文中提出的双层优化问题,需要在外循环更新合成图,然后在内循环优化网络参数。嵌套循环严重阻碍了冷凝方法的可扩展性,这促使本文设计一种新的高效冷凝策略。本文提出了一种One-Step梯度匹配方案,只匹配模型初始化的网络梯度,同时丢弃的训练轨迹。本质上,这个策略用第一个 epoch 的初始匹配损失来近似 的整体梯度匹配损失,称之为一步匹配损失。直觉是:一步匹配损失告诉本文更新合成数据的方向,其中,凭经验观察到从合成数据训练的模型中获得的交叉熵损失(在真实样本上)的大幅下降.因此,可以在等式中删除求和符号并简化等式如下:
实验分析
分类性能比较
为了验证所提出框架的有效性,本文测量了在压缩图上训练的 GCN 的分类性能。具体来说,本文在 {1, 10, 50} 范围内(对于 MUTAG 和电子商务为 {1, 10, 20})改变每个类别的学习合成图的数量,并在这些图上训练 GCN。然后本文在原始测试图上评估训练好的 GCN 的分类性能。按照 OGB 中的约定,本文报告了 ogbg-molbace、ogbg-molbbbp 和 ogbg-molhiv 的 ROC-AUC 度量;对于其他数据集,本文报告分类准确度 (%)。结果总结在表1中。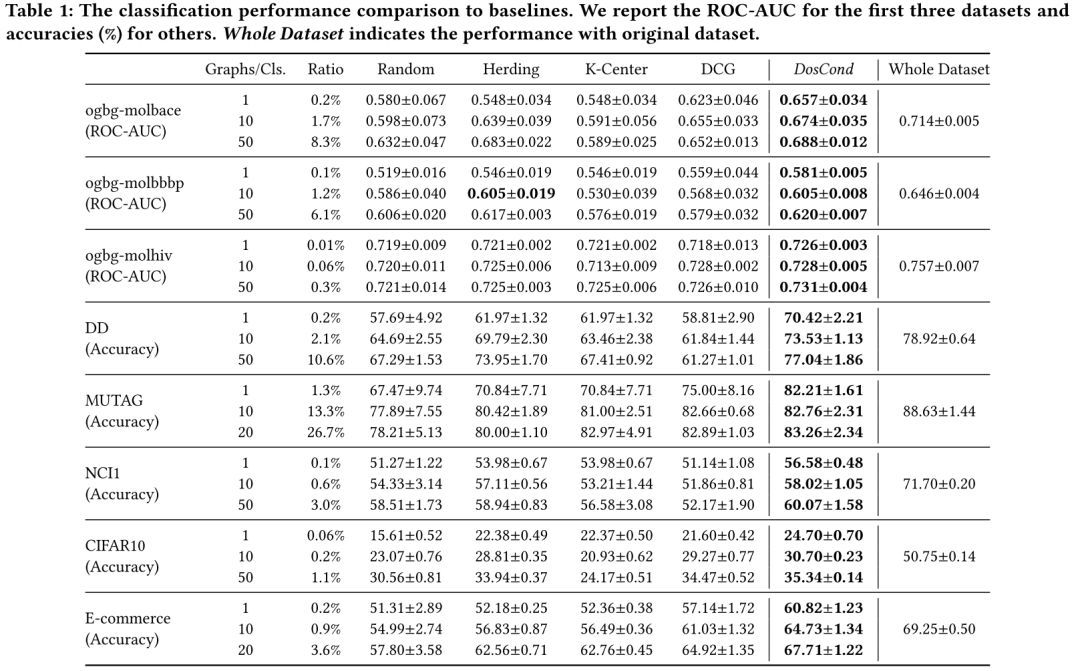 注意比率列表示合成图与原始图的比率,本文将其命名为冷凝率;Whole Dataset 列显示了通过对原始数据集进行训练所获得的 GCN 性能。从表中,本文得出以下观察结果:
注意比率列表示合成图与原始图的比率,本文将其命名为冷凝率;Whole Dataset 列显示了通过对原始数据集进行训练所获得的 GCN 性能。从表中,本文得出以下观察结果:
(a) 在不同的冷凝率和不同的数据集下,所提出的 DosCond 始终比基线方法取得更好的性能。值得注意的是,当在 ogbg-molbace 数据集(0.2%)上仅生成 2 个图时,本文实现了 0.657 的 ROCAUC,而在完整训练集上的性能为 0.714,这意味着本文仅用 0.2% 的数据就接近了原始性能的 92%。同样,本文能够用 0.3% 的数据在 ogbg-molhiv 上近似 96.5% 的原始性能。相比之下,基线大大低于本文的方法。可以在其他数据集上进行类似的观察,这证明了学习合成图在保留原始数据集信息方面的有效性。 (b) 增加合成图的数量可以提高分类性能。例如,本文可以用 0.2%/2.1%/10.6% 的数据将原始性能逼近 89%/93%/98%。更多的合成样本表明更多可学习的参数可以保留原始数据集中的信息,并呈现更多样化的模式,可以帮助更好地训练 GNN。这一观察结果与本文在第 3.3.1 节中的实验结果一致。 (c) 由于合成图的数量有限,CIFAR10 的性能不太乐观。本文假设数据集具有更复杂的拓扑和特征信息,因此需要更多参数来保存足够的信息。然而,本文注意到本文的方法仍然优于基线方法,尤其是在每个类仅生成 1 个样本时,这表明本文的方法更具有数据效率。此外,本文可以通过学习更大的合成集来提升 CIFAR10 的性能,如 3.3.1 节所示。 (d) 学习合成图结构和节点特征对于保留原始图数据集中的信息是必要的。通过检查仅基于随机选择的图结构学习节点特征的性能 DCG,本文发现 DCG 在大多数情况下都大大低于 DosCond。这表明仅学习节点特征对于压缩图是次优的。
效率比较
由于本文的目标之一是实现可扩展的数据集压缩,因此本文现在评估 DosCond 的效率。本文将 DosCond 与 coreset 方法 Herding 进行比较,因为它比 DCG 耗时更少,并且通常比其他基线实现更好的性能。本文采用与表 1 中相同的设置:DosCond 的 1000 次迭代,即 1 = 1000,以及 500 个 epoch(ogbg-molhiv 为 100 个 epoch)用于按照 Herding 的要求预训练图卷积网络。本文还注意到,预训练神经网络需要在每个 epoch 遍历整个数据集,而 DosCond 只处理一批图。在表 2 中,本文报告了 CIFAR10、ogbg-molhiv 和 DD 在 NVIDIA V100 GPU 上的运行时间。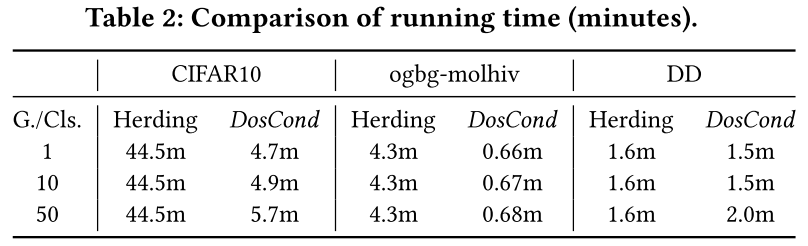 从表中,本文有两个观察结果:
从表中,本文有两个观察结果:
(a) DosCond 可以比 Herding 更快。事实上,DosCond 在所有情况下都需要更少的训练时间,除了在 DD 中每个类有 50 个图。Herding 需要在整个数据集上充分训练模型以获得高质量的嵌入,这可能非常耗时。相反,DosCond 只需要 1 次初始化的匹配梯度,不需要在大型真实数据集上完全训练模型。 (b) DosCond 的运行时间随着合成图#0 数量的增加而增加。这是因为 DosCond 在每次迭代时都会处理压缩图,对于!-layer GCN,时间复杂度为 $(#0!(=23+=32))。因此,额外的复杂度取决于#0。相比之下,#0 的增加对 Herding 影响不大,因为基于预定义启发式选择样本的过程非常快。 (c) 合成图中的平均节点=也影响 DosCond 的训练成本。例如,ogbg-molhiv(==26)的训练成本远低于 DD(==285),两种方法在 ogbg-molhiv 和 DD 上的成本差距非常大。如前所述,这是因为对于节点大小为=的#0压缩图,GCN中前向过程的复杂度为$(#0!(=23 + =32))。
总结
在大规模图数据集上训练图神经网络会消耗很高的计算成本。缓解此问题的一种解决方案是将大型图形数据集压缩为小型合成数据集。在这项工作中,本文提出了一种新颖的框架 DosCond,它采用一步梯度匹配策略,有效地将真实图浓缩成少量具有离散结构的信息图。本文从理论和经验的角度进一步证明了所提出的方法的合理性。值得注意的是,本文的实验表明,本文能够将数据集大小减少 90%,同时接近原始性能的 98%。未来,本文计划
研究可解释的压缩方法和压缩图的各种应用。
