




文章信息
「来源」:Proceedings of the 39th International Conference on Machine Learning(ICML) 2022
「标题」:Generalization Guarantee of Training Graph Convolutional Networks with Graph Topology Sampling
「作者」:Hongkang Li, Meng Wang, Sijia Liu, Pin-Yu Chen, Jinjun Xiong
「链接」:https://proceedings.mlr.press/v162/li22u.html
内容简介
图卷积网络(GCN)最近在学习图结构数据方面取得了巨大的经验成功。「为了解决由于相邻特征的递归嵌入而导致的可扩展性问题,已经提出了图拓扑采样来降低训练 GCN 的内存和计算成本」,并且在许多实证研究中它已经实现了与没有拓扑采样的测试性能相当的测试性能。据作者所知,本文为半监督节点分类训练(最多)三层 GCN 中的图拓扑采样提供了第一个理论证明。本文正式描述了图拓扑采样的一些充分条件,使得 GCN 训练导致泛化误差减小。此外,本文的方法解决了权重跨层的非凸相互作用,这在现有的 GCN 理论分析中没有得到充分探索。本文明确描述了图结构和拓扑采样对泛化性能和样本复杂度的影响,并且通过数值实验也证明了理论发现是正确的。
与经验上的成功相比,用图采样训练 GCN 的理论基础研究非常少,只有Cong等人分析了图采样的收敛速度,但没有提供泛化分析。关于训练 GCN 的一个基本问题仍然悬而未决——用图拓扑采样学习的 GCN 在什么条件下可以实现令人满意的泛化?
「本文的主要贡献如下」
首先,本文提出了一个同时实现随机梯度下降(SGD)和图拓扑采样的训练框架,并且保证学习到的具有校正线性单元(ReLU)激活的GCN模型接近一大类目标函数的最佳泛化性能.此外,随着标记节点数量和神经元数量的增加,目标函数的类别扩大,表明泛化能力提高。 其次,本文通过对节点相关性进行建模的有向图的有效邻接矩阵 ,明确描述了图拓扑采样对泛化性能的影响。 取决于 GCN 中给定的归一化图邻接矩阵和图采样策略。本文提供了以下「insights」:(1)如果一个节点的采样频率较低,与 相比,它对其他节点的影响在 中会降低;(2) 在高度不平衡的 上进行图采样,其中一些节点在图中具有主导影响,从而产生更平衡的 。此外,这些发现适用于其他图采样方法,例如 FastGCN (Chen et al., 2018a)。本文表明,使用拓扑采样进行学习与使用 训练 GCN 具有相同的泛化性能。因此,即使采样节点的数量很少,仍然可以实现令人满意的泛化,只要得到的 仍然正确地表征数据相关性。这是图拓扑采样的经验成功的第一个理论解释。 第三,本文表明所需的标记节点数,称为样本复杂度,是 和最大节点度的多项式,其中 衡量最大绝对行和。此外,本文的样本复杂度仅与神经元 m 的数量成对数,并且与 GCN 的实际过参数化一致,这与 (Zhang et al., 2020) 在限制性设置中 poly(m) 的松散界限形成对比。没有图拓扑采样的两层(一个隐藏层)GCN。
使用拓扑采样训练 GCN:公式和主要组件
学习者网络
本文考虑训练三层 GCN 的设置 :
考虑一个损失函数 使得对于每个 ,函数 是非负的、凸的、1-Lipschitz 连续且 1-Lipschitz 平滑且 。这包括交叉熵损失和 -回归损失(对于有界 )。学习问题解决了以下经验风险最小化问题:
其中 是标记节点的经验风险,以 为单位。训练后的权重用于估计 上的未知标签。请注意,本文中的结果是无分布的,并且没有对 和 的分布做任何假设。
使用 SGD 进行训练
在实践中,上式通常通过梯度类型的方法求解,其中在迭代 t 中,当前估计值通过减去正步长和在当前估计值下评估的 梯度的乘积来更新。为了降低估计梯度的计算复杂度,通常采用 SGD 方法来计算随机选择的 Ω 子集的风险梯度,而不是使用整个集合 Ω。然而,由于 GCN 中相邻特征的递归嵌入,计算梯度的计算和内存成本可能很高。因此,已经提出了图拓扑采样方法来进一步降低计算成本。
图拓扑采样
节点采样方法在每次迭代中独立地从 G 中随机删除节点子集和事件边,嵌入聚合基于约简图。在数学上,在迭代 s 中,将上式中的 替换为 ,其中 是对角矩阵,如果在迭代 s 中移除节点 i,则第 i 个对角线条目为 0。 的非零对角线条目根据不同的采样方法选择不同的。因为 比 稀疏得多,嵌入相邻特征的计算和内存成本显着降低。
主要算法和理论结果
通过下图中的算法学习到的 GCN 可以使用一大类目标函数接近标签预测的最佳性能。此外,当标记节点的数量和神经元 和 的数量增加时,预测性能会提高。这是使用图拓扑采样训练 GCN 的第一个泛化性能保证。 上述算法总结了具有下表中参数选择的算法:
上述算法总结了具有下表中参数选择的算法:
实验分析
为了揭示本文的理论结果如何与 GCN 在实验中的泛化性能保持一致,本文专注于对合成数据的数值评估,可以控制目标函数并明确地与 进行比较。本文还评估了我们的图采样方法和 FastGCN (Chen et al., 2018a),以验证我们的图采样方法的见解也适用于 FastGCN。
下图显示了测试误差随着标记节点的数量|Ω|增加而减小,当每层 m 的神经元数量固定为 500 时。此外,随着 的增加,所需的标记节点数增加以达到相同水平的测试误差。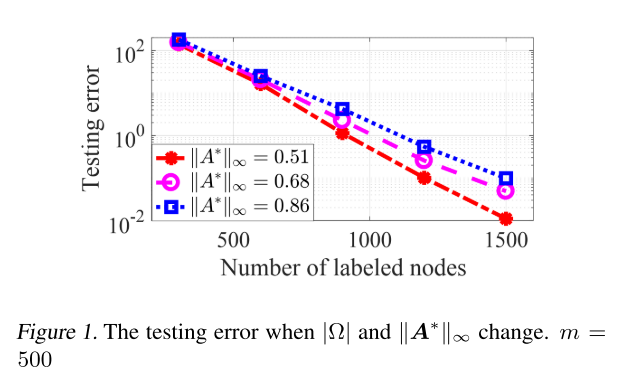
下图显示当 |Ω|固定为 1500 时,测试误差随着 m 的增加而减小。此外,随着 的增加,需要更大的 m 才能达到相同水平的测试误差。
结论
本文提供了一个新的理论框架来解释图采样在训练 GCN 中的经验成功。它通过有效的邻接矩阵明确量化图采样的影响,并提供泛化和样本复杂性分析。未来的一个方向是基于所提出的见解开发主动图采样策略并分析其泛化性能。其他潜在的扩展包括构建基于统计模型的 表征和对现实世界数据的适应度,以及深度 GCN、图形自动编码器和跳跃知识网络的泛化分析。
