





引言
在线查询,如针对历史轨迹的时空范围查询(过去24小时车辆在某个区域的行驶轨迹)、周边查询(附近2公里内的出租车)等,一般要求在毫秒或秒级。
实时计算,如实时的电子围栏判断(判断车辆是否驶出目标范围),时空统计(实时热力图,计算某个区域实时车辆数),一般要求在毫秒级。
离线计算,针对大规模历史轨迹数据做挖掘,比如根据轨迹挖掘出迁徙模式。
一直以来,各类NoSQL数据库对时空数据的高并发写入、在线查询等支持并不完善,每个NoSQL数据库基本上只能用于某种特定场景。比如:基于Hadoop平台的方案一般会在UDF层提供时空算子,但缺少时空索引,无法将时空算子下推到存储层,基本上只能用作离线查询;Apache Sedona(原GeoSpark)内置了时空索引,但一般用于时空数据挖掘等场景,不适合实时在线查询;MongoDB内置了2dsphere空间索引,但由于写入速度、扩展性的瓶颈,普遍只将其用作LBS等场景;GeoMesa作为一款中间件,可以借助HBase等存储具备较高的写入能力,而且支持空间填充曲线作为时空索引,但不支持二级索引,当客户从多维度查询时需要建立多张表,数据存在冗余,存储成本非常高。
在实时计算的场景里,目前也缺少一个完备的支持时空数据的流引擎,导致很多客户会引入一个通用的流引擎或者直接用数据库来近似代替。
此外,这些数据库均不支持SQL接口,各个数据库的数据类型、访问接口均不一致,业务系统在接入不同的数据库时要进行大量的适配改造。
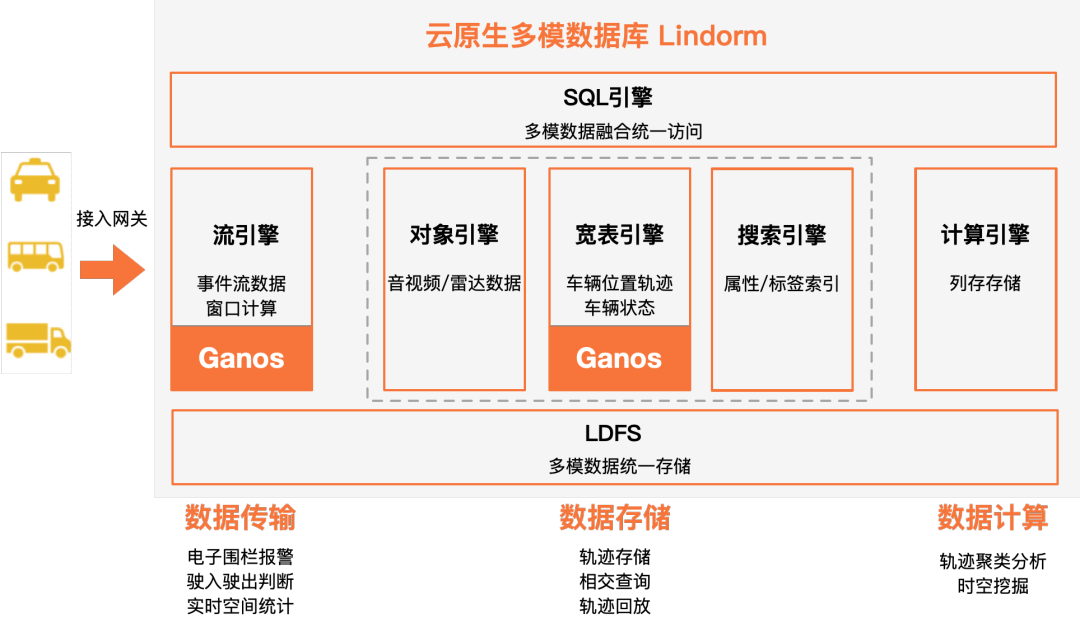
Lindorm作为一款阿里云推出的云原生超融合多模数据库,包含了流引擎、宽表引擎、对象引擎、搜索引擎等,那么自然少不了对时空数据的支持。最新发布的Lindorm已经深度融合了达摩院空天数据库引擎Ganos(下文统称为Lindorm Ganos),可以一站式的解决海量轨迹场景的存储和各类查询需求,弥补了各类NoSQL在时空方面的不足。
标准化:采用SQL接口和Geometry类型,用户可以像使用PostGIS一样来使用Lindorm Ganos。
高性能:一方面继承了Lindorm在写入、扩展性、成本等基础能力的优势;另一方面提供了时空主键索引、时空二级索引来应对多维度查询,在高效查询的同时无需为时空场景专门冗余一份数据。
全面性:支持Lindorm宽表引擎和流引擎,一套系统里既可以电子围栏这样的实时计算场景,也可以支持大规模历史数据的查询和统计,降低了解决方案的复杂性。
本文在Lindorm Ganos中对上述常用的时空场景进行测试,用过程和实际的数据展示Lindorm Ganos的具备的能力和特性。
1.时空范围查询
时空范围查询是时空领域的基础查询能力,这里所说的时空范围查询是一个统称,具体又可以分为:
根据空间范围查找
根据时间范围查找
根据空间范围 + 时间范围查找
Lindorm Ganos提供了原生的时空数据类型、时空算子、时空主键索引、时空二级索引,避免为每一种查询冗余存储一份数据。
轨迹数据
查询范围数据
Lindorm Ganos测试集群:Lindorm三节点16核32GB,性能型云存储 开源GeoMesa 3.0.0版本,底层存储为HBase测试集群:3节点独享 16核32GB,SSD云盘 MongoDB测试集群:3个Mongos为16核32GB(通用型);3个shard为16核64G(通用型)
针对海量轨迹的写入用时 建立时空索引后的空间占用 时空范围查询用时
创建表和索引
CREATE TABLE foil_2010 (medallion VARCHAR,pickup_datetime TIMESTAMP,geom GEOMETRY(POINT),primary key(z-order(geom), medallion)) WITH (COMPRESSION='ZSTD');复制
String schemaDescription = "medallion:String,pickup_datetime:Date,*geom:Point:srid=4326";SimpleFeatureType simpleFeatureType = SimpleFeatureTypes.createType("foil_2010", schemaDescription);simpleFeatureType.getUserData().put("geomesa.table.compression.enabled", true);simpleFeatureType.getUserData().put("geomesa.table.compression.type", "zstd");simpleFeatureType.getUserData().put("geomesa.indices.enabled", "z2");复制
db.createCollection( "foil_2010", {storageEngine:{wiredTiger:{configString:'block_compressor=zstd'}}} );//创建空间索引db.foil_2010.createIndex({geom:"2dsphere"});sh.enableSharding("test");sh.shardCollection("test.foil_2010",{"_id":"hashed"});......collection.bulkWrite(rows);复制
空间范围查询
Lindorm Ganos:使用SQL语法。
SELECT medallionFROM foil_2010WHERE ST_Contains(ST_GeomFromText('POLYGON ((...))'), geom);复制
ecqlPredicate = "CONTAINS(POLYGON ((...)) , geom)";query = new Query("foil_2010", ECQL.toFilter(ecqlPredicate));result = datastore.getFeatureSource("foil_2010").getFeatures(query);iterator = result.features();while (iterator.hasNext()) {iterator.next();}复制
MongoDB:添加Filter,并通过MongoDB接口迭代获取数据。
Bson filter = Filters.geoWithin("geom", new Polygon(new PolygonCoordinates(polygonCoords)));MongoCursor<Document> cursor = collection.find(filter).iterator();while (cursor.hasNext()) {cursor.next();}复制
时空范围查询
Lindorm Ganos:使用SQL语法。
SELECT medallionFROM foil_2010WHERE ST_Contains(ST_GeomFromText('POLYGON ((...))'), geom)AND pickup_datetime >= 'xxxx-xx-xx xx:xx:xx'AND pickup_datetime <= 'xxxx-xx-xx xx:xx:xx';复制
GeoMesa(HBase):使用GeoTools的ECQL语法,并通过GeoTools的接口迭代获取数据。
ecqlPredicate = "CONTAINS(POLYGON ((...)) , geom) AND pickup_datetime >= xxx AND pickup_datetime <= xxx";query = new Query("foil_2010", ECQL.toFilter(ecqlPredicate));result = datastore.getFeatureSource("foil_2010").getFeatures(query);iterator = result.features();while (iterator.hasNext()) {iterator.next();}复制
Bson filter = Filters.and(Filters.geoWithin("geom", new Polygon(new PolygonCoordinates(polygonCoords))), Filters.and(Filters.gte("pickup_datetime",startTime), Filters.lte("pickup_datetime", endTime));MongoCursor<Document> cursor = collection.find(filter).iterator();while (cursor.hasNext()) {cursor.next();}复制
可以看出,创建表以及查询时,Lindorm Ganos使用的SQL语法都是最简洁的,使用非常方便。
写入用时
| 数据库 | 用时 |
| Lindorm Ganos | 7 min |
| GeoMesa(HBase) | 13 min |
| MongoDB | 34 min |
存储空间占用
数据库 | 表大小 | 空间索引大小 |
Lindorm Ganos | 4.7 GB | 无额外空间,主键作索引 |
GeoMesa(HBase) | 5.9 GB | 无额外空间,主键作索引 |
MongoDB | 8.2 GB | 1.6 GB |
空间范围查询用时
空间范围查询场景下,随着返回结果的增加,几个系统的查询用时也在增加。Lindorm Ganos在大部分的查询中,查询性能都是大幅领先GeoMesa(HBase)和MongoDB,耗时分别为GeoMesa(HBase)的1/3,MongoDB的1/2。
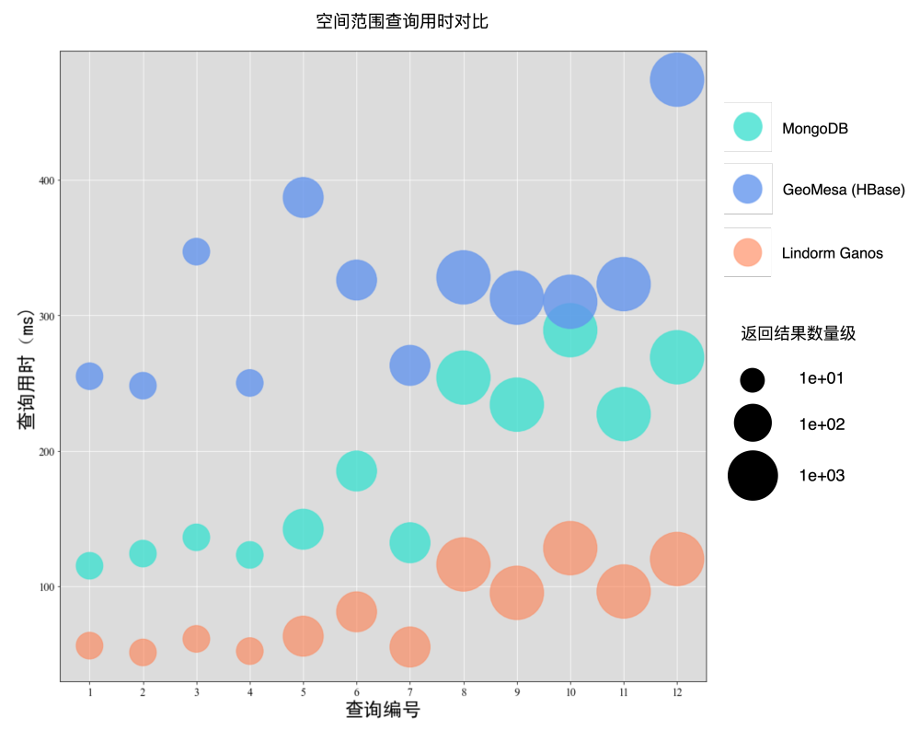
时空范围查询用时
时间+空间范围查询场景下,Lindorm Ganos在大部分的查询中,查询性能都是领先GeoMesa(HBase)和MongoDB,耗时分别是二者的1/3和1/2左右,个别查询耗时与二者持平。
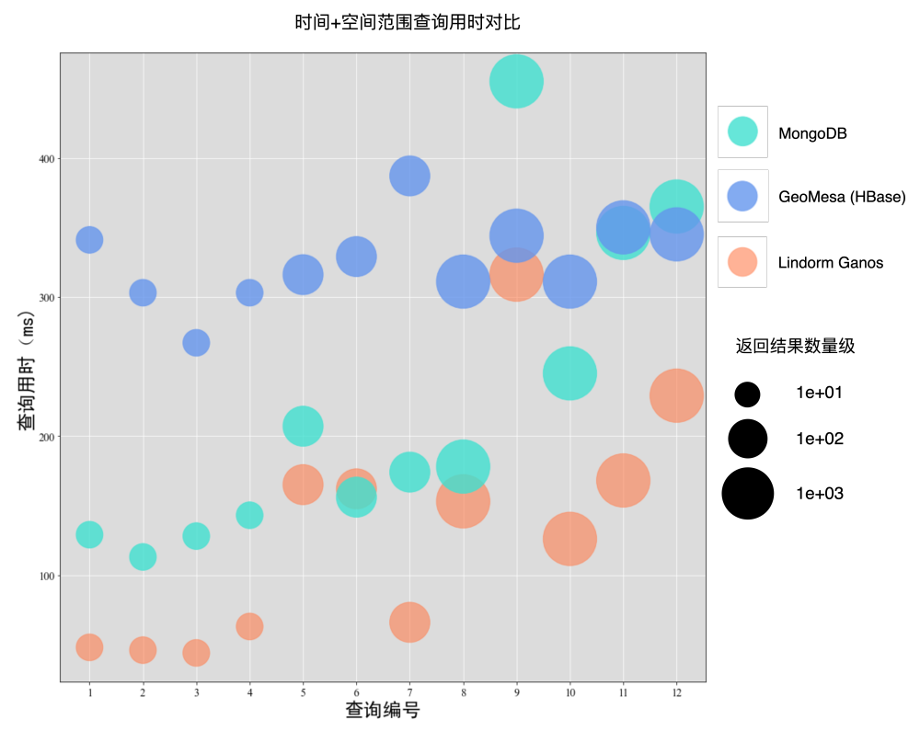
2.电子围栏
实时监控车辆的运行轨迹,判断车辆是否偏离设定的路线也是一个强需求,这类查询一般称为电子围栏或地理围栏判断。与时空范围查询相反,电子围栏是给定一个位置点,来判断该点是否在某个/些范围内。这类查询对实时性的要求比较高,且并发也较大,为了应对这种场景,Ganos结合Lindorm流引擎,可以以流计算的方式来处理。
本节以实时电子围栏为例,来展示Ganos在这个场景中的应用。除电子围栏外,Lindorm 流引擎也支持车辆出入围栏告警等用法。
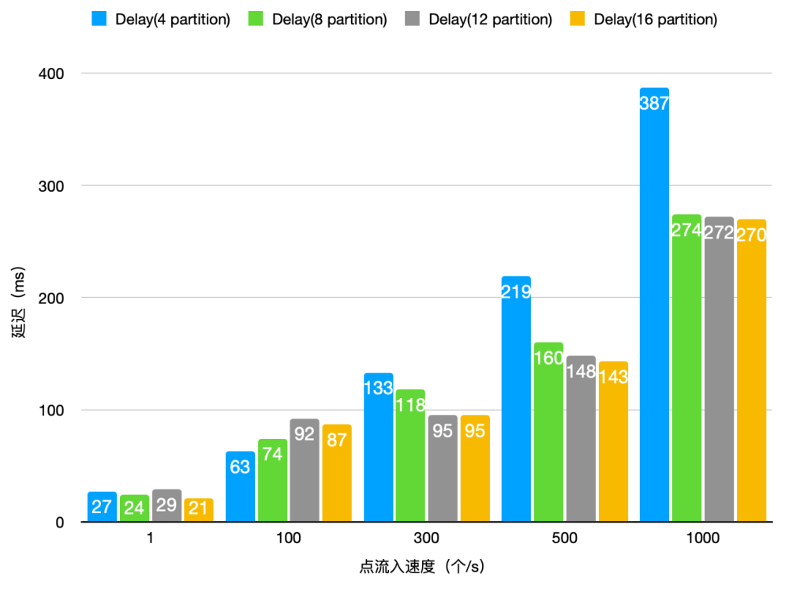
Lindorm Ganos 宽表:4核 16GB 2节点 Lindorm Streams 引擎:32核 64GB 2节点,Topic 分别为 4/8/12/16 partition,1 Producer 1 Consumer
写入数据
# lindorm-clicreate table bj_busline (route_id int,poly geometry(polygon),primary key(route_id));复制
创建流引擎映射表
CREATE External Table dimTableWITH (table_type = 'lindorm.table',table_name = 'bj_busline',endpoint = 'lindorm-1:30020',output_batchsize=500,cache_type = 'LRU',cache_ttl = 1800000,ganos_index_type='RTREE',ganos_index_polygon_col_name='poly');复制
创建写入流和输出流
CREATE STREAM input_stream (p_id int,p_location geometry(point),time bigint)WITH (stream_topic='input', value_format='JSON', key_value = 'p_id');CREATE STREAM output_stream (p_id int,p_location geometry(point),route_id varchar,time bigint)WITH (stream_topic='output', value_format='JSON', key_value = 'p_id');复制
计算链路
CREATE CQ busRouteJoin INSERT INTO output_streamSELECTl.p_id AS p_id,l.p_location AS p_location,r.route_name AS route,l.time AS timeFROM input_stream l LEFT JOIN dimTable r ON ST_Contains(r.poly, l.p_location);复制
p_id | p_location | route | time |
0 | Point(116.4132, 40.0568) | 984路区间 | 2022-09-07 15:18:22 |
1 | Point(116.4133, 40.0569) | null | 2022-09-07 15:18:25 |
... |
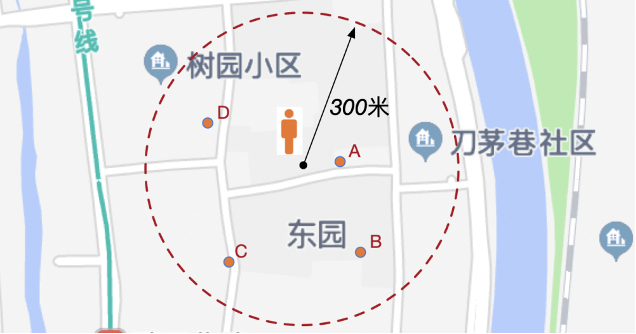
3.周边查询
周边查询一般只会指定中心点以及查询距离,距离的度量单位一般为米或千米,而时空范围查询一般是含有一系列坐标点的Polygon对象。 计算距离时,一般是指地球椭球体上的距离,而不是平面坐标系的距离。
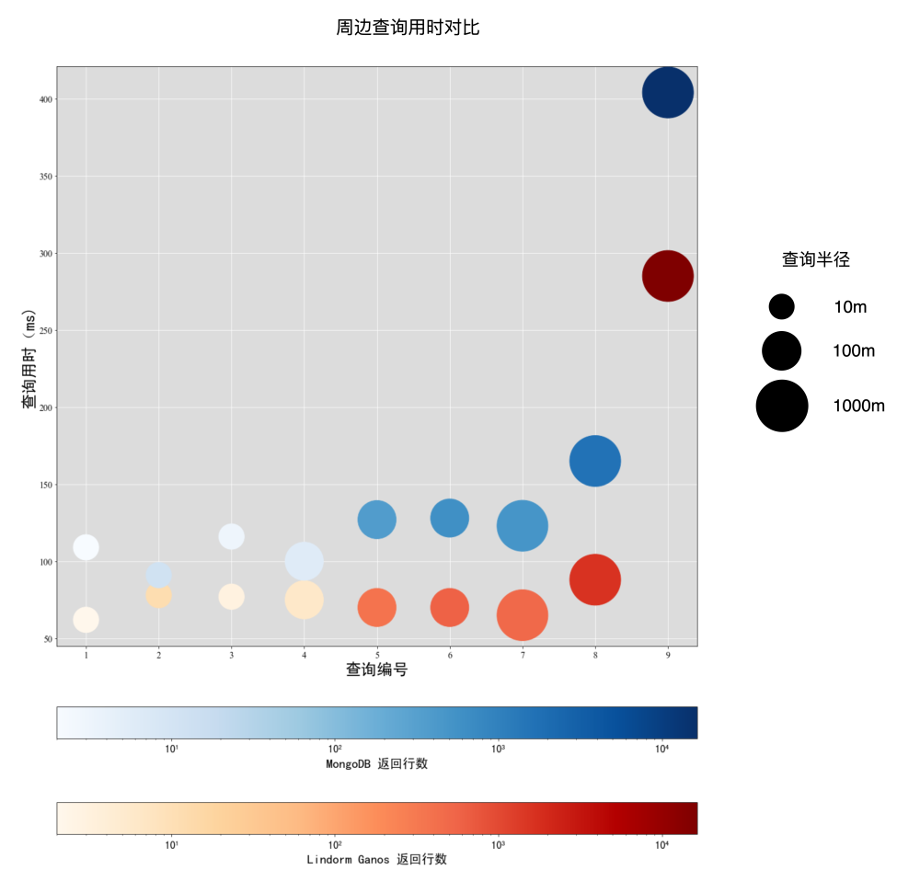
查询语句示例
Lindorm Ganos:使用SQL语法
SELECT medallionFROM foil_2010WHERE ST_DWithinSphere(ST_GeomFromText('POINT (120.177206 30.273576)'), geom, 300e0);复制
MongoDB
Bson filter = Filters.nearSphere("geom", new Point(new Position(120.177206, 30.273576)), 300.0, 0.0);MongoCursor<Document> cursor = collection.find(filter).iterator();while (cursor.hasNext()) {cursor.next();}复制
总结
可以通过SQL语法很便捷的处理各类查询场景,使用起来比较简单
可以与Lindorm宽表引擎、流引擎深度的融合,覆盖大部分常用的场景,减少了解决方案的复杂性
在存储成本上低于GeoMesa(HBase)以及MongoDB,可降低20%~50%的存储空间
在查询性能上,大部分查询场景的性能要大幅领先业界已有系统(2~3倍)




 点击「阅读原文」查看云原生多模数据库Lindorm更多信息
点击「阅读原文」查看云原生多模数据库Lindorm更多信息
