




接上回,填写必须配置就可以搭集群,示例:
#主节点配置node_id=1node_name=node1conninfo='host=192.168.101.9 port=5432 user=postgres dbname=postgres'data_directory='/var/lib/pgsql/12/data'
故障恢复必须参数
此时搭建好的集群是不具备自动故障转移功能的,我们还需要配置以下必要参数,示例:
failover='automatic'promote_command='/usr/pgsql-12/bin/repmgr standby promote'follow_command='/usr/pgsql-12/bin/repmgr standby follow'
参数说明:
failover
automatic:表示开启故障自动转移
manual:不开启故障自动转移
promote_command
当repmgrd确定当前节点将成为新的主节点时 ,将在故障转移情况下执行中定义的程序或脚本。
follow_command
当repmgrd确定当前节点将跟随新的主节点时 ,将在故障转移情况下执行中定义的程序或脚本。
简单来讲,集群主机故障后(断电,断网,系统崩溃等等),如果集群repmgr.conf中failover='manual',则需要人工干预,集群啥也不干 ,如果failover='automatic',则集群备机会触发选举,在备机中选举一个备机升级为主机,其他备机在新主机升级为主机后自动跟随新的主机继续同步数据,基本流程如下:
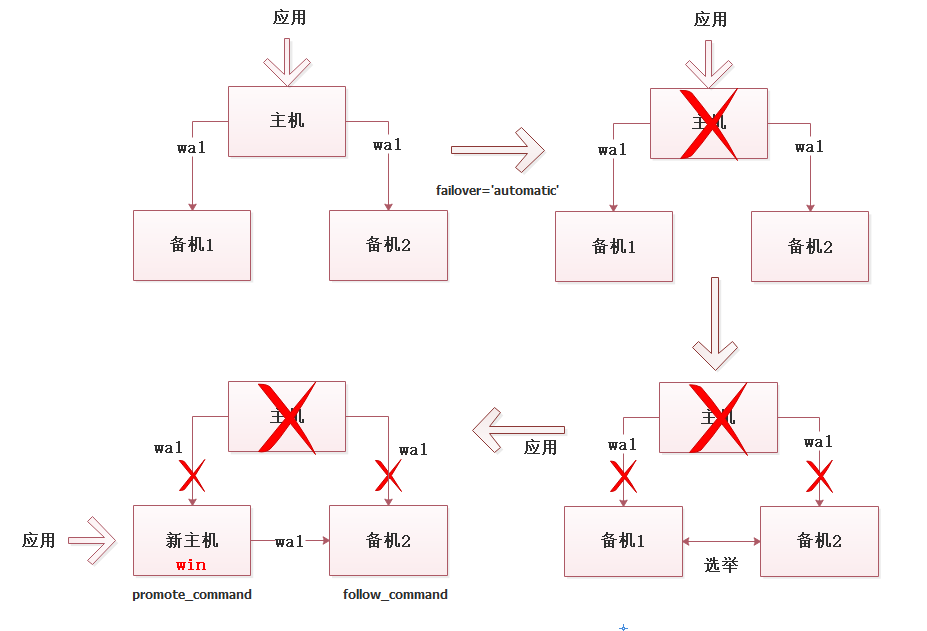
一幅极丑的流程图
故障转移的可选参数
priority=60
权重,在选举主机过程中,权重高的备机具有升主的更高优先级,如果权重为0,则该备机永远不会升级为主机
monitor_interval_secs = 2
此参数告诉repmgr守护程序应该多久(以秒为单位)检查上游节点的可用性。默认2s检查一次。
connection_check_type ='ping'
用什么方式联系上游节点。此参数可以采用三个值:默认为ping
ping: repmgr uses the PQPing() method
connection: repmgr tries to create a new connection to the upstream node
query: repmgr tries to run a SQL query on the upstream node using the existing connection
reconnect_attempts = 6reconnect_interval = 10
当主节点不可用时,备用节点中的repmgr守护程序将尝试重新连接到主节点达到reconnect_attempts次。此参数的默认值为6。在每次重新连接尝试之间,它将等待reconnect_interval秒,默认值为10。
primary_visibility_consensus = true
当主节点在多节点群集中不可用时,备用节点可以相互协商以建立有关故障转移的仲裁。这是通过询问每个备用数据库上次看到主数据库的时间来完成的。如果节点的最后一次通信是最近的,并且晚于本地节点看到主节点的时间,则本地节点会假定主节点仍然可用,并且不会继续执行故障转移决定。
standby_disconnect_on_failover = true
在备用节点中将standby_disconnect_on_failover参数设置为“ true”时,repmgr守护程序将确保其WAL接收者与主节点断开连接并且不接收任何WAL段。在做出故障转移决定之前,它还将等待其他备用节点的WAL接收器停止。在每个节点中,此参数应设置为相同的值。
将此参数设置为true意味着在发生故障转移时,每个备用节点都已停止从主节点接收数据。该过程将有5秒钟的延迟加上WAL接收器在做出故障转移决定之前停止所花费的时间。默认情况下,repmgr守护程序将等待30秒以确认所有同级节点在故障转移发生之前已停止接收WAL段。
repmgrd_service_start_command ='sudo usr / bin / systemctl start repmgr12.service'repmgrd_service_stop_command ='sudo / usr / bin / systemctl stop repmgr12.service'
这两个参数指定如何使用“ repmgr守护程序启动”和“ repmgr守护程序停止”命令启动和停止repmgr守护程序。

