





Apache Kafka是一个基于分布式流处理的软件平台。它是一个发布订阅的消息系统,使得应用,服务器,处理器可以交换数据。Kafka最初由Linkedin开发,随后捐赠给Apache软件基金会。Apache Kafka解决了发送方和接收方之间数据通信的问题。
kafka架构
架构包含了 —
主题
它是表示相似类型数据的通用名字或标题。在Apache Kafka中,一个集群中可以有多个主题。每个主题指定不同类型的消息。
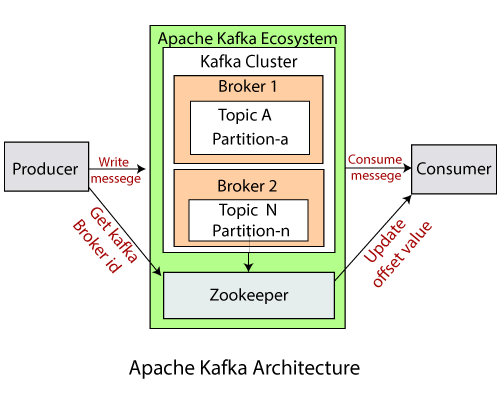
分区
数据或消息被划分为更小的部分,称为分区。每个分区中数据都有一个偏移量(offset)。数据以顺序方式写入。我们可以有无限多的分区,有无限多的偏移量。然而,我们不能保证信息将被写入哪个分区。
副本
Apache Kafka是大数据领域的分布式软件系统。因此数据有很多份拷贝。在Kafka中,每一个Broker包含一系列数据,但是如果Broker或机器宕机了呢?数据就会丢失。为防患于未然,Apache Kafka启用了复制的特性,以避免数据的丢失,即使在Broker故障的情况下。要做到这一点,需要为Broker中的主题设置副本因子(replication factor)。
生产者
它们是使用生产者的API向集群内的主题写入/发布数据的应用程序。生产者可以在主题或主题内指定分区上写入数据。
消费者
它们是使用消费API从集群内的主题中读取/消费数据的应用程序。消费者可以读取主题的或主题内指定分区的数据。
Broker
Broker是维护和管理已发布的消息的软件进程。Broker管理消费者的偏移量,并负责将消息传递给正确的消费者。
Zookeeper
zookeeper用于监控Kafka集群并协调每个Broker。它以键值对的形式保存所有与Kafka集群相关的元数据信息。
Kafka如何工作的?
Kafka是一个分布式系统,由服务器和客户端组成,通过高性能的TCP网络协议进行通信,并部署在任何虚拟机和云环境中。
服务器
Kafka以一个或多个服务器集群的形式运行,可以跨越多个数据中心或云区域。其中一些服务器形成了存储层,称为Broker。其他的服务器运行Kafka Connect,不断地导入和导出数据到流事件。
客户端
它们允许编写分布式应用和微服务,这些应用和微服务可以并行地、大规模地读取、写入和处理事件流,即使在网络问题或机器故障的情况下也能以容错的方式进行。
Kafka特性

伸缩性
Apache Kafka可以扩展数据生产者、数据Broker和数据消费者。无论你是由几个数据生产者创建很大的数据集,然后发送给许多消费者组,还是以其他方式,Kafka都能满足你的需求。
扩展性
Kafka在过去几年非常流行,也促进了大量应用程序开发与Kafka的集成。 这使得新功能的添加变得很容易,比如说以插件集成到应用程序中。
容错
Kafka Streams建立在Kafka内部原生集成的容错能力上。Kafka分区是高度可用和复制的,所以当流数据被持久化到Kafka时,即使应用程序失败并需要重新处理,它也是可用的。Kafka Stream中的任务利用了Kafka消费者客户端提供的容错能力来处理故障。如果一个任务运行在一台有故障的机器上,Kafka Streams会自动在应用程序的一个剩余运行实例中重新启动该任务。
减少了对多种整合的需求
生产者生产的所有数据都要经过Kafka。因此,我们只需要创建一个Kafka的集成,就可以自动将每个生产者和消费进行集成。
分布式系统
Apache Kafka是个分布式架构,具有可扩展性。分区和复制是分布式系统下的两种能力。
实时处理
Kafka近乎实时地监控所有的数据通信,以实现访问控制,检测异常,并提供安全通信。这种架构能够与没有连接的遗留系统整合,以收集传感器数据,但也确保外部系统不能访问不安全的机器。
Kafka使用场景

消息
Kafka有更强的吞吐量,内置分区、复制和容错功能,这使它成为处理大规模消息应用的解决方案。
网站活动追踪
Kafka最初的使用场景是重建用户活动追踪管道,作为实时发布-订阅的消息流。
度量
Kafka用于运维监控数据。这涉及到从分布式应用中聚合统计数据,以产生集中的运维数据。
日志聚合
许多人使用Kafka作为日志聚合解决方案的替代品。日志聚合通常收集服务器上的物理日志文件,并将它们放在一个中心位置(也许是文件服务器或HDFS)进行处理。Kafka抽象了文件的细节,并给日志或事件数据的消息流创建了一个更简洁的抽象。
流式处理
许多使用Kafka的用户在多个阶段组成的管道中处理数据,原始输入数据在Kafka主题中被消耗,丰富组合或转化后发给新的主题。
事件溯源
事件溯源是一种应用程序的设计风格,将状态变化记录成一个时间序列记录。Kafka支持日志数据的海量存储,这使得它成为该风格应用程序后端的出色选择。
Apache Kafka应用
2010年,LinkedIn开发了Apache Kafka。由于Kafka是一个发布-订阅的消息系统,因此在LinkedIn的各种产品,如LinkedIn Today和LinkedIn Newsfeed都使用它来消费消息。
Uber
Uber使用Kafka作为消息总线来连接生态系统的不同部分。Kafka帮助乘客和司机满足彼此的匹配。它从乘客的应用程序以及司机的应用程序中收集信息,然后将这些信息提供给各种下游的消费者。
由于Kafka满足了数据复制和持久性的需求,Twitter已经成为Apache Kafka的最佳应用/用户之一。采用Kafka使Twitter节省了高达75%的大量资源,很好地降低了成本。
Netflix
Netflix在Keystone Pipeline下使用Kafka。Keystone是一个统一的收集、事件发布和路由基础设施,用于流处理和批处理。
结论
Kafka支持低延迟的消息传递,并在机器出现故障时提供容错保证。它可以处理大量不同的消费者。Kafka的速度非常快,可以达到200万次/秒的写入速度。
原文标题:Introduction to Kafka
原文作者:Mohd Uzair
原文地址:https://blog.knoldus.com/introduction-to-kafka/
