




学习了ORACLE的存储结构的同学,应该对下面的图比较熟悉吧!MYSQL也有表空间,那是INNODB的存储结构,不过MYSQL的分区比较鸡肉,太多了分区会导致系统问题,因为MYSQL每个表都是两个文件,分区多了就消耗很多LINUX文件句柄。为什么不像ORACLE一样用1个数据文件去存储众多的表呢?
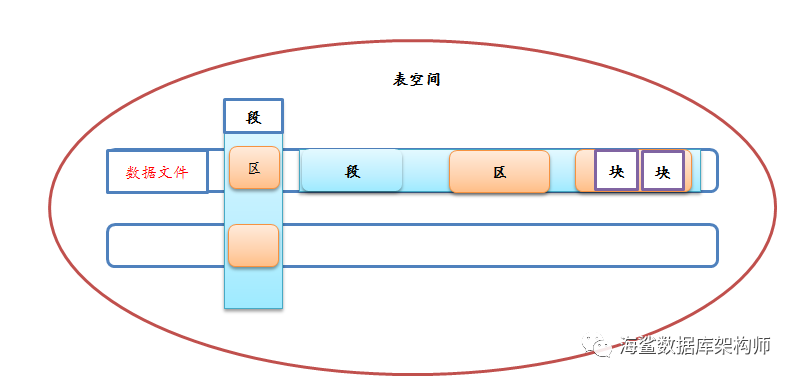
ORACLE的一个表空间可以拥有众多的数据文件,这个上限在控制文件中设定。每个数据文件在LINUX下最大是32GB。
每个表和每个索引属于一个段,每个段里面区(EXTENTS),每个区含有块(BLOCK),每个块含有行(ROW)和控制信息,每个行含有列(COL)和行控制信息。
而列信息 我们可以使用C语言的结构体来表示。
struct Row
{
int Row_Id; 行ID
bool LockFlag; //锁定标志
int XID; //事务ID
bool is_Distr; 支持分布式
time RCT;
void pUndoAddr;
void pRowValue;
}TROW;
以上是初步设计的行结构,其中pRowValue指向行的具体值。
我们可以把学生属性结构体
struct student
{
int id;
char name[50];
int scoe;
int age;
tim stude_date;
}
如何分配内存,并且把学生存入内存中并写入二进制文件可以参考
很显然 MYSQL每个表有定义和数据分别两个文件,类似这样的。不过我们要把它综合在一起,那么就要设计通用表定义,如下
struct
{
int col_id;
int col_size;
char col_name[30];
} TRowMeta
struct table
{
int table_id
int segment_id
TRowMeta Rowmeta;
} Ttable
通过以上两个结构体定义,我们可以知道pRowValue指向内存数据的类型和长度。
typedef struct
{
int tablespace_id;
char tablespace_name[50];
int segment_id_list[]; // 采用C语言动态数组或者链表结构
int datafile_list[];
} TTablespace;
typedef struct
{
int datafile_id;
char datafile_name[50];
char datafile_path[500];
} TDataFile;
这样我们通过 这两个结构体 关联表空间和数据文件的定义以及段的关联
typedef struct
{
int segment_id;
int segment_type;
int extent_count;
long File_offset;
TExtent pextent_list;
}TSegment;
我们初步定义段的信息,ID类型,有多少个EXTENT,以及段开始在文件的位置。
typede struct
{
int extent_id;
int file_id;
int block_count;
long file_offset;
long free_block_list;//采用位域表示哪个块有空闲 64*8=
TBLOCK * pblock_list;
} TExtent;
这里我们定义了区的信息,由区的file_id来实现跨文件。
typedef struct
{
int block_id;
int row_count;
int last_logSCN;
long free_row;
TROW pRow_list;
} TBLOCK;
最后我们定义块信息;我们规定块大小只能4K,当然也可以64 128KB;
不过我们设计是OLTP类型的数据库,防止块过大导致系统造成块裂,也就是避免MYSQL的双写的IO性能损失。
最后我们定义下ROWID
typedef struct
{
int tablespac_id;
int segment_id;
int extent_Id;
int file_id;
int block_id;
int row_id;
} TROW_ID;
