




PostgreSQL是开源第二大数据库,其开源协议是纯免费的。依旧是其它人在其原代基础上修改后可以封装成商业产品。而MYSQL的开源协议是不能封装的。PostgreSQL是纯免费无风险开源产品!
从编译角度来说,MYSQL需要3个小时编译时间,而PostgreSQL需要30分钟!MYSQL源码是用C++编写的,PostgreSQL是用C语言编写的。对大多数中国学生来说PostgreSQL比较易懂!
PostgreSQL我简称PGSQL
PGSQL是教研关系型数据库,主要流行在学校象牙塔上。PGSQL优点是比较亲近ORACLE的 在LINUX下是进程模型,而MYSQL是线程模型!
PGSQL有共享池,而MYSQL没有。MYSQL UNDO的实现技巧和ORACLE差不多,而PGSQL使用表内多行实现,在实际高并发下相对来说是缺点!
PGSQL 安装很简单,基本都是源码编译安装。我银行无外网下,拷贝PGSQL安装也能安装进去,就不要一些额外的功能就行。下面是安装步骤
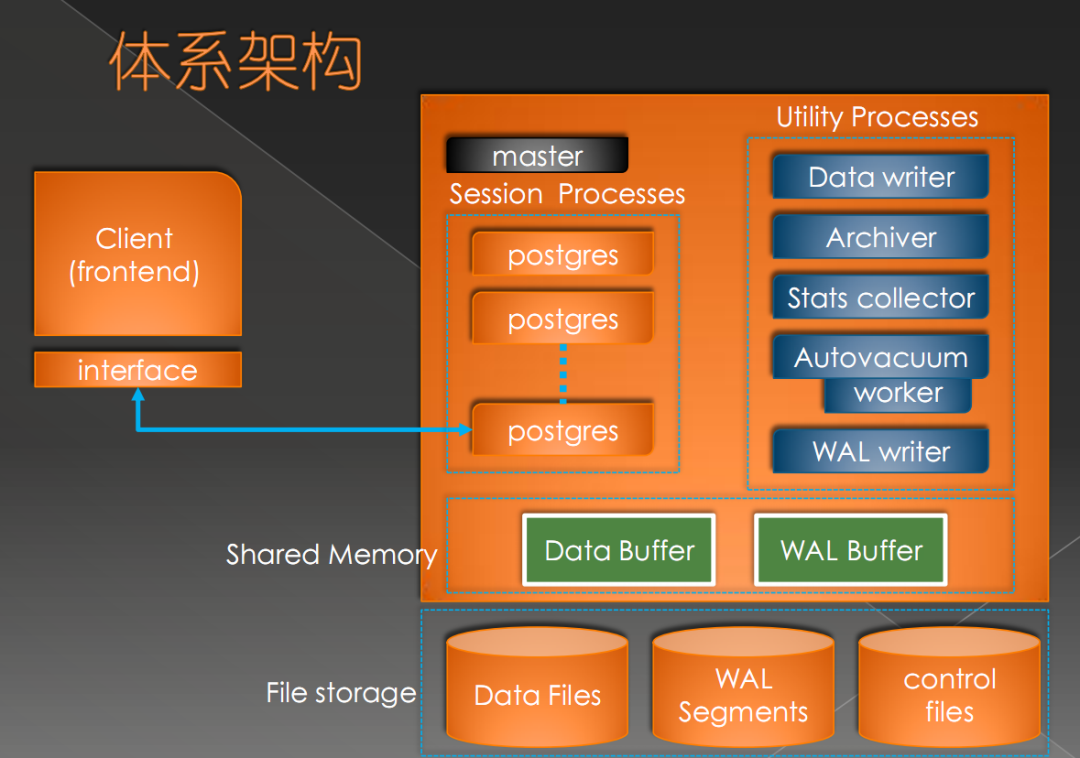
PostgreSQL把客户端称为前端(Frontend),把服务器端成为后端(Backend), 后端有复数个进程构成,这个在后面会进行说明。简单来说,大体的工作模式是:前端向后端发送查询的SQL文,然后后端通过复数个报文把结果返回给前端。
由于需要进行连接的初始化、错误等各种各样处理,PostgreSQL的协议的处理也是相当复杂,如果要自己从头实现这些协议的处理的话,还是相当麻烦的,所以PostgreSQL本身提供了C语言写的libpq这样一个协议处理库,利用这个库可以比较轻松地和后端进行通信。PostgreSQL的话除了C以外,还支持Perl和PHP等其他语言,这些语言在内部也调用了libpq.
也有不使用libpq而直接与PostgreSQL通信的库。比较具有代表性的是Java, PostgreSQL的JDBC驱动是不依赖于libpq直接与PostgreSQL通信的.
另外后端的话,比较核心的是进行数据库处理的数据库引擎(Database Engine)。数据库引擎可以对用户所编写的函数进行解析和处理,用户如果能够利用好这个功能的话,可以柔软地扩展PostgreSQL的功能。比较经常使用的是存储过程(PostgreSQL中称为用户自定义函数),
PostgreSQL的结构
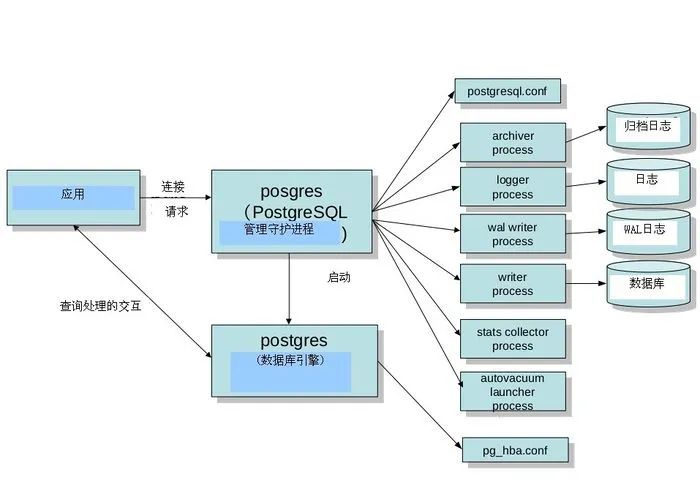
Potgres(常驻进程)
管理后端的常驻进程,也称为’postmaster’。其默认监听UNIX Domain Socket和TCP/IP(Windows等,一部分的平台只监听tcp/ip)的5432端口,等待来自前端的的连接处理。监听的端口号可以在PostgreSQL的设置文件postgresql.conf里面可以改。
一旦有前端连接过来,postgres会通过fork(2)生成子进程。没有Fork(2)的windows平台的话,则利用createProcess()生成新的进程。这种情形的话,和fork(2)不同的是,父进程的数据不会被继承过来,所以需要利用共享内存把父进程的数据继承过来。
这相对于ORACLE 主进程+监听程序
Postgres(子进程)
子进程根据pg_hba.conf定义的安全策略来判断是否允许进行连接,根据策略,会拒绝某些特定的IP及网络,或者也可以只允许某些特定的用户或者对某些数据库进行连接。
Postgres会接受前端过来的查询,然后对数据库进行检索,最好把结果返回,有时也会对数据库进行更新。更新的数据同时还会记录在事务日志里面(PostgreSQL称为WAL日志),这个主要是当停电的时候,服务器当机,重新启动的时候进行恢复处理的时候使用的。另外,把日志归档保存起来,可在需要进行恢复的时候使用。在PostgreSQL 9.0以后,通过把WAL日志传送其他的postgreSQL,可以实时得进行数据库复制,这就是所谓的‘数据库复制’功能。
这个相当于ORACLE的服务进程
其他的进程
Postgres之外还有一些辅助的进程。这些进程都是由常驻postgres启动的进程。
Writer process
Writer process在适当的时间点把共享内存上的缓存写往磁盘。通过这个进程,可以防止在检查点的时候(checkpoint),大量的往磁盘写而导致性能恶化,使得服务器可以保持比较稳定的性能。Background writer起来以后就一直常驻内存,但是并非一直在工作,它会在工作一段时间后进行休眠,休眠的时间间隔通过postgresql.conf里面的参数bgwriter_delay设置,默认是200微秒。
这个进程的另外一个重要的功能是定期执行检查点(checkpoint)。
检查点的时候,会把共享内存上的缓存内容往数据库文件写,使得内存和文件的状态一致。通过这样,可以在系统崩溃的时候可以缩短从WAL恢复的时间,另外也可以防止WAL无限的增长。可以通过postgresql.conf的checkpoint_segments、checkpoint_timeout指定执行检查点的时间间隔。
这个相当于ORACLE的DBWR
WAL writer process
WAL writer process把共享内存上的WAL缓存在适当的时间点往磁盘写,通过这样,可以减轻后端进程在写自己的WAL缓存时的压力,提高性能。另外,非同步提交设为true的时候,可以保证在一定的时间间隔内,把WAL缓存上的内容写入WAL日志文件。
这个相当于ORACLE的REDO WRITER LGWR
Archive process
Archive process把WAL日志转移到归档日志里。如果保存了基础备份以及归档日志,即使实在磁盘完全损坏的时候,也可以回复数据库到最新的状态。
这个相当于ORACLE的 ARCH
stats collector process
统计信息的收集进程。收集好统计表的访问次数,磁盘的访问次数等信息。收集到的信息除了能被autovaccum利用,还可以给其他数据库管理员作为数据库管理的参考信息。
Logger process
把postgresql的活动状态写到日志信息文件(并非事务日志),在指定的时间间隔里面,对日志文件进行rotate.
这个相当于ORACLE的 告警信息 这里不要把它看做REDO 哦!
Autovacuum启动进程
autovacuum launcher process是依赖于postmaster间接启动vacuum进程。而其自身是不直接启动自动vacuum进程的。通过这样可以提高系统的可靠性。
自动vacuum进程
autovacuum worker process进程实际执行vacuum的任务。有时候会同时启动多个vacuum进程。
这个相当于ORACLE的处理UNDO的工作进程
wal sender wal receiver
wal sender 进程和wal receiver进程是实现postgresql复制(streaming replication)的进程。Wal sender进程通过网络传送WAL日志,而其他PostgreSQL实例的wal receiver进程则接收相应的日志。Wal receiver进程的宿主PostgreSQL(也称为Standby)接受到WAL日志后,在自身的数据库上还原,生成一个和发送端的PostgreSQL(也称为Master)完全一样的数据库。
服务进程工作基本流程
下面看看数据库引擎postgres子进程的处理概要。为了简单起见下面的说明中,把backend process简称为backend。Backend的main函数是PostgresMain (tcop/postgres.c)。
接收前端发送过来的查询(SQL文)
SQL文是单纯的文字,电脑是认识不了的,所以要转换成比较容易处理的内部形式构文树parser tree,这个处理的称为构文解析。构文解析的模块称为parser.这个阶段只能够使用文字字面上得来的信息,所以只要没语法错误之类的错误,即使是select不存在的表也不会报错。这个阶段的构文树被称为raw parse tree. 构文处理的入口在raw_parser (parser/parser.c)。
构文树解析完以后,会转换为查询树(Query tree)。这个时候,会访问数据库,检查表是否存在,如果存在的话,则把表名转换为OID。这个处理称为分析处理(Analyze), 进行分析处理的模块是analyzer。另外,PostgreSQL的代码里面提到构文树parser tree的时候,更多的时候是指查询树Query tree。分析处理的模块的入口在parse_analyze (parser/analyze.c)
PostgreSQL还通过查询语句的重写实现视图(view)和规则(rule), 所以需要的时候,在这个阶段会对查询语句进行重写。这个处理称为重写(rewrite),重写的入口在QueryRewrite (rewrite/rewriteHandler.c)。
通过解析查询树,可以实际生成计划树。生成查询树的处理称为‘执行计划处理’,最关键是要生成估计能在最短的时间内完成的计划树(plan tree)。这个步骤称为’查询优化’(不叫query optimize, 而是optimize), 而完成这个处理的模块称为查询优化器(不叫query optimizer,而是optimizer, 或者称为planner)。执行计划处理的入口在standard_planner (optimizer/plan/planner.c)。
按照执行计划里面的步骤可以完成查询要达到的目的。运行执行计划树里面步骤的处理称为执行处理‘execute’, 完成这个处理的模块称为执行器‘Executor’, 执行器的入口地址为,ExecutorRun (executor/execMain.c)
执行结果返回给前端。
返回到步骤一重复执行。
PostgreSQL TRANSACTION(事务)
TRANSACTION(事务)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
数据库事务通常包含了一个序列的对数据库的读/写操作。包含有以下两个目的:
为数据库操作序列提供了一个从失败中恢复到正常状态的方法,同时提供了数据库即使在异常状态下仍能保持一致性的方法。
当多个应用程序在并发访问数据库时,可以在这些应用程序之间提供一个隔离方法,以防止彼此的操作互相干扰。
当事务被提交给了数据库管理系统(DBMS),则 DBMS 需要确保该事务中的所有操作都成功完成且其结果被永久保存在数据库中,如果事务中有的操作没有成功完成,则事务中的所有操作都需要回滚,回到事务执行前的状态;同时,该事务对数据库或者其他事务的执行无影响,所有的事务都好像在独立的运行。
事务的属性
事务具有以下四个标准属性,通常根据首字母缩写为 ACID:
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。
例子
某人要在商店使用电子货币购买100元的东西,当中至少包括两个操作:
该人账户减少 100 元。
商店账户增加100元。
支持事务的数据库管理系统就是要确保以上两个操作(整个"事务")都能完成,或一起取消,否则就会出现 100 元平白消失或出现的情况。
事务控制
使用下面的命令来控制事务:
<li》
COMMIT:事务确认,或者可以使用 END TRANSACTION 命令。
ROLLBACK:事务回滚。
事务控制命令只与 INSERT、UPDATE 和 DELETE 一起使用。他们不能在创建表或删除表时使用,因为这些操作在数据库中是自动提交的。
BEGIN TRANSACTION 命令
事务可以使用 BEGIN TRANSACTION 命令或简单的 BEGIN 命令来启动。此类事务通常会持续执行下去,直到遇到下一个 COMMIT 或 ROLLBACK 命令。不过在数据库关闭或发生错误时,事务处理也会回滚。以下是启动一个事务的简单语法:
BEGIN;或者BEGIN TRANSACTION;复制
COMMIT 命令
COMMIT 命令是用于把事务调用的更改保存到数据库中的事务命令,即确认事务。
COMMIT 命令的语法如下:
COMMIT;或者END TRANSACTION;复制
ROLLBACK 命令
ROLLBACK 命令是用于撤消尚未保存到数据库的事务命令,即回滚事务。
ROLLBACK 命令的语法如下:
ROLLBACK;复制
实例
创建 COMPANY 表(下载 COMPANY SQL 文件 ),数据内容如下:
runoobdb# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000(7 rows)复制
现在,让我们开始一个事务,并从表中删除 age = 25 的记录,最后,我们使用 ROLLBACK 命令撤消所有的更改。
runoobdb=# BEGIN;
DELETE FROM COMPANY WHERE AGE = 25;
ROLLBACK;复制
检查 COMPANY 表,仍然有以下记录:
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000复制
现在,让我们开始另一个事务,从表中删除 age = 25 的记录,最后我们使用 COMMIT 命令提交所有的更改。
runoobdb=# BEGIN;
DELETE FROM COMPANY WHERE AGE = 25;
COMMIT;复制
检查 COMPANY 表,记录已被删除:
id | name | age | address | salary
----+-------+-----+------------+--------
1 | Paul | 32 | California | 20000
3 | Teddy | 23 | Norway | 20000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000(5 rows)复制
PGSQL 开发语法在这个网站可以学习到,简单快捷!
https://www.runoob.com/postgresql/postgresql-tutorial.html
