




原文: Add AutoML capabilities to your analytics data with MindsDB and ClickHouse
链接: https://www.mindsdb.com/blog/machine-learning-models-as-tables-in-ch
作者:Zoran Pandovski
前言
我录了一份基于一条SQL语句搞定机器学习模型?的视频,有兴趣的可以到菜单里查看MindsDB系列文章。
这篇文章是一条SQL语句搞定机器学习模型?的续篇, 在一条SQL语句搞定机器学习模型?介绍了MindsDB+MariaDB, 今天介绍MindsDB[1]+ClickHouse[2]。
机器模型即表
让我们从机器学习的最常见问题之一开始本文,即机器学习和人工智能之间的区别是什么?当我们考虑机器学习时,我们可以将其视为人工智能的子集。简而言之,机器学习的思想是通过使用小型到大型数据集并在数据内部找到通用模式,使机器能够自行学习。也就是说,数据是任何机器学习算法的核心,访问数据是机器学习成功的关键步骤之一。这将使我们想到第二个问题:这些数据存放在哪里?
做机器学习,数据库是不错的选择
随着当今数据库中数据量,种类,速度的增加。与能够直接在数据库中进行机器学习相比,有没有更好的地方可以进行机器学习?
我们认为数据库用户满足了应用机器学习的最重要方面,即了解哪些预测性问题很重要以及哪些数据与回答这些问题相关。此外,添加用于创建最合适模型的统计分析将产生最佳组合,该组合是直接从数据库自动进行机器学习。将AutoML带给最了解数据的人员可以大大增强解决重要问题的能力。
因此,我们决定与Clickhouse建立无缝集成,以使任何ClickHouse用户都可以使用与结构化查询语言(SQL)相同的知识来创建,训练和测试机器学习模型。
如何做到这一点?
我们利用ClickHouse的巧妙功能来访问外部表,就像它们是内部表一样。因此,这些模型的集成是轻松而透明的,使我们能够:
公开可以查询的机器学习模型,例如表格。您只需SELECT 您想要的预测,然后在 WHERE语句中传递预测的条件。
使用简单的INSERT语句自动构建,测试和训练机器学习模型,您可以在其中指定要学习的内容和查询内容。
为什么要使用MindsDB?
MindsDB是一个快速发展的具有内置的可解释性的开源AutoML框架,其独特的可视化功能有助于更好地理解和信任预测的准确性。
使用MindsDB,开发人员可以构建,训练和测试机器学习模型,而无需数据科学家/机器学习工程师的帮助。它与典型的AutoML框架的不同之处在于,MindsDB通过可解释性将重点放在可信赖性上,使用户可以就模型为何以及如何达到其预测获得有价值的见解。
为什么要使用ClickHouse?
速度和效率是ClickHouse的关键。ClickHouse的查询处理速度是传统数据库的100倍,是数字广告,电子商务,Web和应用程序分析,监控,电信分析的理想解决方案。
在本文的其余部分中,我们将尝试通过MindsDB(作为自动机器学习框架)与ClickHouse(作为OLAP数据库管理系统)之间的集成来详细描述上述几点。
如何安装MindsDB
安装MindsDB与安装其他Python软件包一样容易。环境需求,
Linux, 本文基于Google Colab, 18.04.5 LTS (Bionic Beaver)
Python >=3.6
> 1GB 可用磁盘空间
pip3 或者conda
pip install mindsdb复制
如何安装ClickHouse
如果您已经安装了ClickHouse并保存了分析数据,那么您就可以开始使用MindsDB了,因此只需跳到将MindsDB连接到ClickHouse部分。
否则,ClickHouse可以在具有x86_64 CPU架构的任何Linux或Mac OS X(未测试成功,如果你知道怎么安装,可以告诉我,谢谢)上运行。
Ubuntu(Debian下快速安装脚本):
sudo apt-get install apt-transport-https ca-certificates dirmngrsudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv E0C56BD4echo "deb https://repo.clickhouse.tech/deb/stable/ main/" | sudo tee \etc/apt/sources.list.d/clickhouse.listsudo apt-get updatesudo apt-get install -y clickhouse-server clickhouse-client#运行 clickhouse serversudo service clickhouse-server start#测试clickhouse客户端clickhouse-client复制
注:clickhouse-client在Google Colab该程序会报错,
src/tcmalloc.cc:283] Attempt to free invalid pointer 0x7f008fe16000
可以使用Python客户端pip install clickhouse_driver
或者usql。
将数据导入ClickHouse
与任何其他数据库管理系统一样,ClickHouse也是将表分组到数据库中。要列出可用的数据库,您可以运行一个show databases
查询命令,该查询将显示默认数据库:
SHOW DATABASES;复制
为了存储数据,我们将创建一个名为data的新数据库:
CREATE DATABASE IF NOT EXISTS data;复制
我们将在本教程中使用由data.seoul[2]提供的数据集[3]。让我们创建一个表并将数据存储在ClickHouse中。请注意,您可以使用不同的数据来继续本教程,只需根据您的数据编辑示例查询。
CREATE TABLE pollution_measurement(`Measurement date` DateTime,`Station code` String,Address String,Latitude Float32,Longitude Float32,SO2 Decimal32(5),NO2 Decimal32(5),O3 Decimal32(5),CO Decimal32(5),PM10 Decimal32(1),`PM2.5` Decimal32(1)) ENGINE = MergeTree()ORDER BY (`Station code`, `Measurement date`);复制
请注意,我们需要使用反引号来转义列名称中的特殊字符。
添加到Decimal32(p)的参数是十进制数字的精度,例如Decimal32(5)可以包含-99999.99999至99999.99999之间的数字。Engine = MergeTree,在ClickHouse中指定表的类型。要了解有关所有可用表引擎的更多信息,请转到table-engines文档[5]。
最后,我们需要做的是将数据导入pollution_measurement中:
clickhouse-client --date_time_input_format=best_effort \--query="INSERT INTO data.pollution_measurement FORMAT CSV" \< Measurement复制
--date_time_input_format = best_effort 使日期时间解析器能够解析基本的和所有的ISO 8601[6]标准日期和时间格式。
SELECT * FROM data.pollution_measurement LIMIT 5;复制

到此,我们走了一半了!我们已经成功安装了MindsDB和ClickHouse,并将数据保存在数据库中。现在,我们将使用MindsDB连接到ClickHouse,并从空气污染测量数据中训练和查询机器学习模型。如果您不想在本地安装ClickHouse,ClickHouse Docker映像[7]是一个很好的解决方案。
连接MindsDB与ClickHouse
python3 -m mindsdb --api mysql --config config.json复制
--api 参数指定要使用的API的类型(mysql)。--config指定配置文件的位置。连接到ClickHouse所需的最低配置为:
{"config_version": 1,"use_gpu": false,"api": {"http": {"host": "0.0.0.0","port": "47334"},"mysql": {"certificate_path": "/flows/config/cert.pem","datasources": [],"host": "127.0.0.1","log": {"console_level": "INFO","file": "mysql.log","file_level": "INFO","folder": "logs/","format": "%(asctime)s - %(levelname)s - %(message)s"},"password": "mysql pass","port": "47335","user": "mysql user"}},"debug": false,"integrations": {"default_clickhouse": {"enabled": true,"type": "clickhouse","host": "localhost","password": "pass","port": 8123,"user": "default"}},"interface":{"datastore": {"enabled": false,"storage_dir": "/content/storage"},"mindsdb_native": {"enabled": true,"storage_dir": "/content/storage"}}}复制
在default_clickhouse键中,包括用于连接到ClickHouse的值。在mindsdb_native storage_dir 中,添加路径到MindsDB将某些配置另存为的位置(元数据和.pickle文件)。
如果成功启动MindsDB,将显示Running on http://0.0.0.0:47334/(Press CTRL + C to quit)消息。这意味着MindsDB服务器正在运行并在localhost:47334上监听。
首先,当MindsDB启动时,它将在ClickHouse内创建一个数据库和表。创建的数据库是ENGINE类型的MySQL(connection),其中“ connection”是根据config.json内部提供的参数建立的。
USE mindsdb;SHOW TABLES;复制
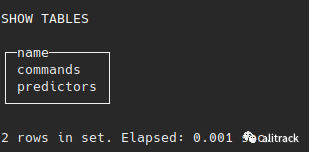
在mindsdb数据库中创建的默认表将是predictors,其中MindsDB将保留有关预测变量(ML模型),训练状态,准确性,目标变量和其他训练选项的信息。
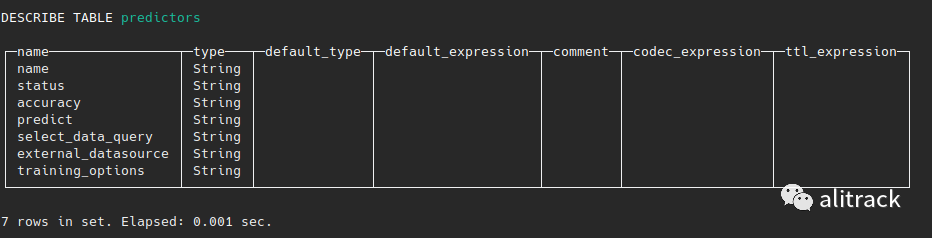
DESCRIBE TABLE predictors;复制
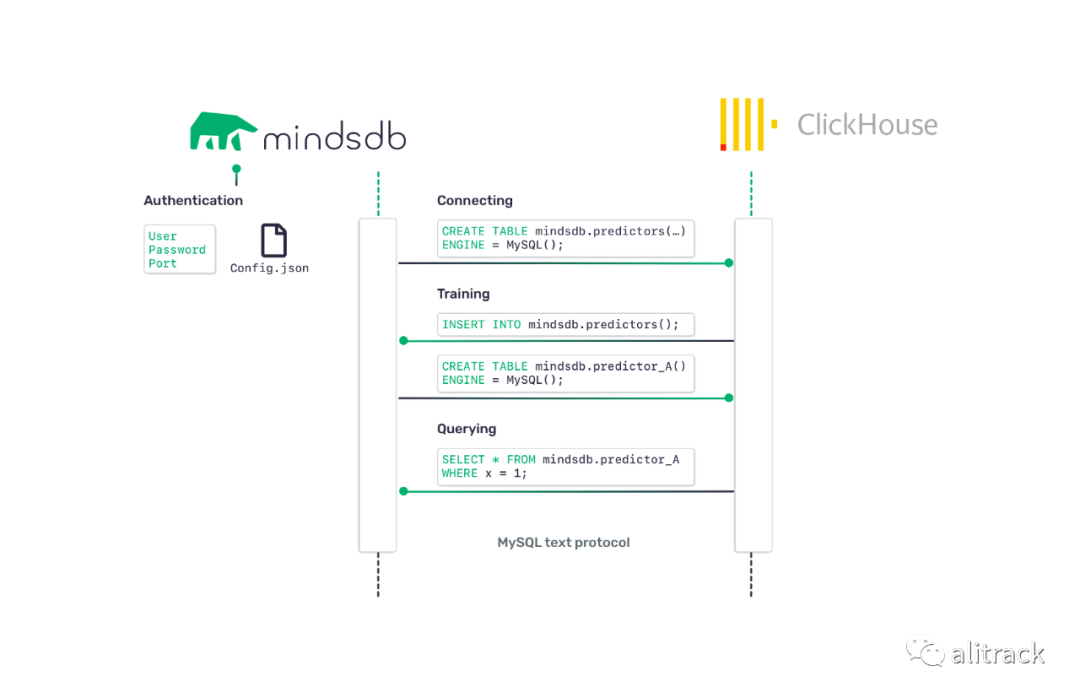
当用户创建新模型或对任何表进行查询时,查询将通过MySQL文本协议发送到MindsDB,并在其中命中MindsDB的API [8]负责训练,分析,查询模型。
现在,我们已经准备就绪,可以创建模型了。我们将使用污染测量表中的数据来预测空气中的二氧化硫(SO2)。创建模型就像编写INSERT查询一样简单,我们将在其中提供一些必需属性的值。在创建预测变量之前,请确保已使用mindsdb数据库:
use mindsdb;INSERT INTO predictors(name, predict, select_data_query)VALUES ('airq_predictor', 'SO2','SELECT * FROM data.pollution_measurementwhere SO2 > 0ORDER BY rand() LIMIT 10000');复制
在MindsDB里,Predictor表示机器学习模型。用于创建预测变量(模型)的列值为:
名称(*string) -- 预测变量的名称。
预测(*string) -- 您要预测的功能,在此示例中为SO2。
select_data_query(*string) -- 将提取数据以训练模型的SELECT查询。
training_options(词典) -- 包含其他培训参数的optional值。有关参数的完整列表,请检查mindsdb.docs[9]。
在后台,将INSERT到预测变量的查询将调用mindsdb-native,它将进行黑盒分析,并开始提取,分析和转换数据的过程。根据数据大小、列、列类型等,训练模型会花费一些时间,因此为了保持更快的速度,我们通过向SELECT查询中添加ORDER BY rand() LIMIT 10000
来使用10000个随机行数据。您应该看到类似以下的消息:
INSERT INTO predictors (name, predict_cols, select_data_query) VALUESOk.1 rows in set. Elapsed: 0.824 sec.*复制
要检查模型训练是否成功完成,可以运行:
SELECT * FROM predictors WHERE name='airq_predictor'复制

状态complete表示模型训练已成功完成。现在,让我们通过查询创建的预测变量来根据数据创建预测分析。这个想法是根据不同的测量参数(例如NO2,O3,CO,位置等)来预测首尔航空站中二氧化硫的值。
SELECT SO2 as predicted, SO2_confidence as confidencefrom airq_predictorWHERE (NO2=0.005)AND CO=1.2 AND PM10=5;复制
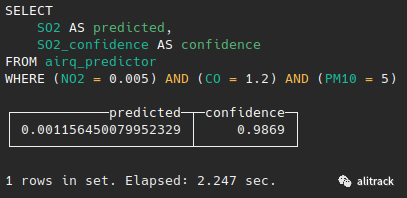
现在您可以看到MindsDB预测二氧化硫的值为0.00115645,置信度约为98%。
要获取有关预测值和置信度的其他信息,我们应包括解释列。在这种情况下,除了置信度外,MindsDB的解释功能还可以提供其他信息,例如预测质量,置信区间,缺少用于改进预测的信息等。我们可以扩展查询,并在解释信息中增加一列:
SELECTSO2 AS predicted,SO2_confidence AS confidence,SO2_explain AS infoFROM airq_predictorWHERE NO2 = 0.005 AND CO = 1.2 AND PM10 = 5复制
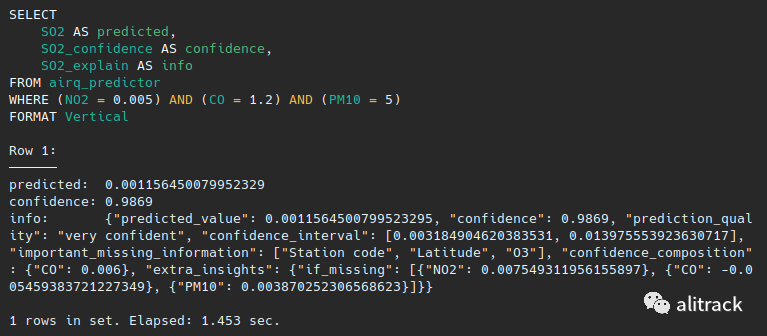
现在我们获得了更多信息:
{"predicted_value": 0.001156540079952395,"confidence": 0.9869,"prediction_quality": "very confident","confidence_interval": [0.003184904620383531, 0.013975553923630717],"important_missing_information": ["Station code", "Latitude", “O3”],"confidence_composition": {"CO": 0.006},"extra_insights": {"if_missing": [{"NO2": 0.007549311956155897}, {"CO": 0.005459383721227349}, {"PM10": 0.003870252306568623}]}}复制
通过查看新信息,我们可以看到MindsDB对此预测的质量非常有信心。在置信区间内确定预测值所在的值范围。同样,在某些未提供的功能(在WHERE子句中)的情况下,额外的洞察力可提供SO2的值。MindsDB认为台站代码以及纬度和O3是进行更精确预测的非常重要的功能,因此这些值应包含在WHERE子句中。让我们尝试添加站台代码并查看新的预测:
SELECTSO2 AS predicted,SO2_confidence AS confidenceFROM airq_predictorWHERE (NO2 = 0.005)AND (CO = 1.2) AND (PM10 = 5)AND (`Station code` = '32') AND `PM2.5`=50复制
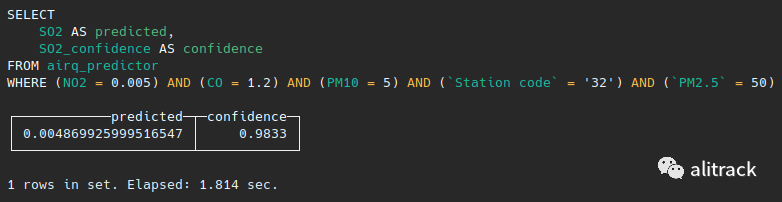
现在,通过添加MindsDB认为对于更好地进行预测非常重要的功能,已更改了预测值。此外,我们可以尝试在将来的某个日期预测空气中的二氧化硫。我们所能做的就是将WHERE子句中的Measurement date值包含在要获取预测的特定日期内,例如:
SELECTSO2 AS predicted,SO2_confidence AS confidenceFROM airq_predictorWHERE (NO2 = 0.005)AND (CO = 1.2) AND (PM10 = 5)AND (`Station code` = '32') AND `PM2.5`=50AND `Measurement date`=’2020-07-03 00:01:00’复制
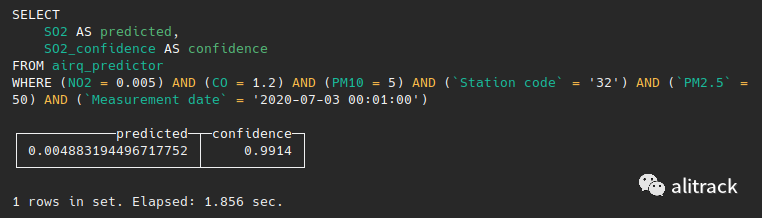
或几周后为:

最后,整个流程非常简单,就像将MindsDB视为ClickHouse中的数据库并直接从中执行INSERT和SELECT查询一样。

如果您使用自己的数据继续学习本教程,我们很高兴听到有关MindsDB如何对您有用的信息。我们在本教程中所做的所有操作都可以在下一版本中通过MindsDB的图形用户界面MindsDB Scout[10]获得。这意味着只需单击MindsDB Scout,您也可以从ClickHouse数据库成功训练ML模型。
参考
https://mp.weixin.qq.com/s/NtYpKhRTV-6wWmrPA9swDg
https://clickhouse.tech/
https ://data.seoul.go.kr/dataList/OA-15526/S/1/datasetView.do
https://github.com/mindsdb/mindsdb-examples/blob/master/others/air_pollution_seoul
https://clickhouse.tech/docs/en/engines/table-engines/
https://en.wikipedia.org/wiki/ISO_8601
https://hub.docker.com/r/yandex/clickhouse-server/
https://apidocs.mindsdb.com/?version=latest
https://docs.mindsdb.com/PredictorInterface/#learn
https://www.mindsdb.com/product





