





2022年9月15日,WunderBase 开源版本发布。这是一个在 SQLite、Firecracker/Fly 机器和 Prisma 之上具有 GraphQL API 的无服务器数据库。 它非常简单,但功能强大,因为代码库不到 400 行 Go。
WunderBase 建立在 Fly 机器之上,这是一个 REST API,可让您在几秒钟内运行虚拟机。 机器的特别之处在于,当应用程序以零退出代码退出时,它们可以休眠。
当你向 WunderBase 发送请求时,虚拟机在大约 300-500 毫秒内唤醒并执行请求。 在处理最后一个请求后十秒(可配置),我们再次让机器进入睡眠状态。 这意味着您实际上只需为实际使用的存储和 CPU 时间付费, 因此得名“无服务器数据库”。
WunderBase GitHub开源地址:https://github.com/wundergraph/wunderbase
为什么我们创造了 WunderBase?
我们正在构建 WunderGraph Cloud,将 Vercel 的原则应用于后端/API 开发。 我们采用最重要的后端原语,如身份验证和授权、数据库、队列、PubSub、键值存储、缓存等 ,并将它们作为单个统一的 SDK 提供。
Git 推送,30 秒后,您就拥有了一个功能齐全的无服务器后端,而无需触及任何基础设施。 进行一些代码更改,打开 PR,并获得包含更改的预览环境。
为此,我们需要一种快速且廉价的方法来创建和销毁数据库。 但正如您将看到的,WunderBase 还有许多其他用例,而不仅仅是预览环境。
WunderBase 是如何工作的?
以下是 WunderBase 工作原理的概述:
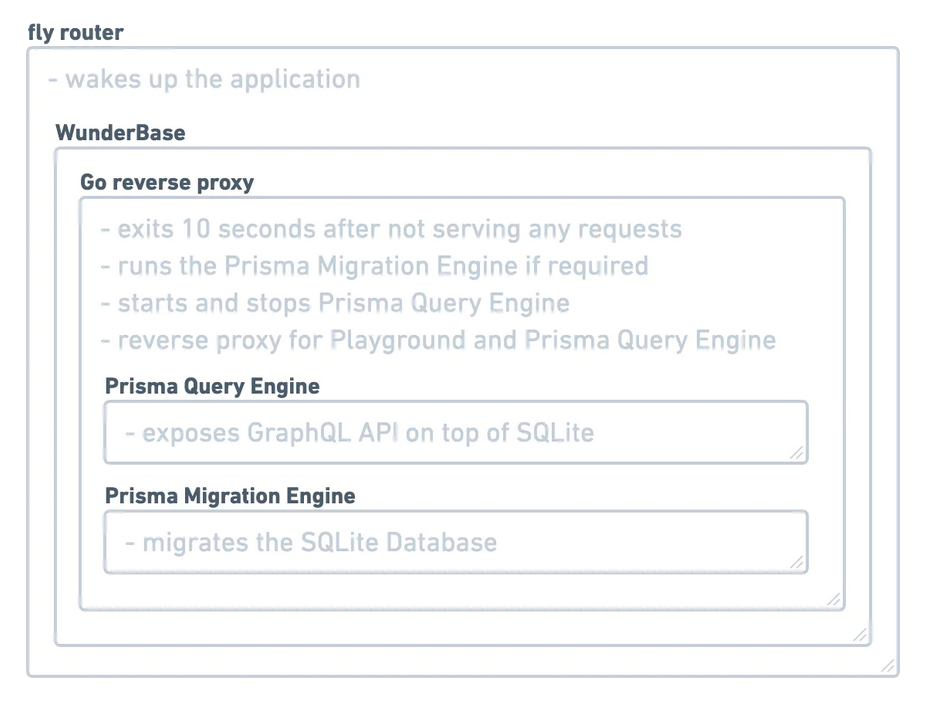
- 您将 WunderBase 部署到附加了卷的 Fly 机器
- Fly 机器启动并启动 WunderBase
- 我们使用该文件使用 Prisma Migration Engine 迁移数据库
prisma.schema - 迁移完成后,我们会创建一个锁定文件以防止将来在文件未更改时进行迁移
prisma.schema - 最后,我们启动 Prisma 查询引擎来服务 GraphQL API
- 在处理最后一个请求后十秒(可配置),我们以零退出代码退出 WunderBase,以指示飞行该机器应该进入睡眠状态
请求流程:
- 您向 WunderBase 发送请求
- Fly 机器在 300-500ms 左右唤醒
- 飞行代理将请求转发到 WunderBase
- WunderBase 清理请求并将其代理到 Prisma 查询引擎
- Prisma 查询引擎执行请求并返回结果
- WunderBase 将结果发送回客户端
- 再一次,在十秒钟不活动后,我们关闭了机器
用 Fly 机器重新思考无服务器
使用 AWS Lambda 时,您必须遵循某些规则以使您的应用程序与环境兼容。 例如,当您使用 Golang 时,您必须导出一个带有a和事件名称的函数。此外,您对应用程序运行的环境并没有太多控制权。在某些时候,Lambda 运行时会关闭您的应用程序。Handlercontext.Context
使用 Fly 机器,我们可以在低得多的水平上进行操作。 我们创建一个侦听特定端口的 Docker 容器。 我们告诉 fly 运行这个容器并将所有请求发送到这个端口。 如果我们认为机器应该休眠,我们以零退出代码退出容器。 当我们发送请求时,Fly 将保持我们的音量并再次启动容器。
许多应用程序都是以 Serverful 单租户方式编写的,作为多租户服务运行通常会非常昂贵。 使用 Fly 机器,我们可以以非常经济高效的方式运行这些应用程序。 但是,有一个问题。我们必须优化应用程序以实现快速启动和关闭。 我知道 fly 正在努力让机器“睡眠”和“恢复”,就像关闭和重新打开笔记本电脑一样。 这将允许我们运行未针对快速启动和关闭进行优化的应用程序。 与此同时,我们以优化快速启动和关闭时间的方式构建了 WunderBase。
减少冷启动和停机时间的优化
当请求等待被处理时,我们需要确保机器尽快启动。 同时,我们总是希望数据库模式与文件保持同步。如果我们每次机器启动时都运行一次迁移,我们将不得不等待迁移完成才能为请求提供服务。这并不理想,因此我们优化了这条路径。prisma.schema
当机器启动时,我们对文件进行哈希处理并检查是否存在具有相同哈希值的锁定文件。如果有锁定文件,我们将锁定文件的内容与文件的哈希值进行比较。如果它们相同,我们就知道该模式的迁移已经执行。如果没有锁定文件,我们运行迁移并使用文件的哈希创建一个锁定文件。prisma.schema prisma.schema prisma.schema
我们将锁定文件存储在卷中,因此即使机器处于睡眠状态也可以使用。
接下来,我们需要确保 Prisma 查询引擎正确关闭。 我们将 Prisma 查询引擎作为一个单独的进程启动。 在我们终止主进程之前,我们向Prisma 查询引擎发送一个信号。如果我们立即杀死主进程,子进程将使机器停止关闭几秒钟。相反,我们使用 a等待 Prisma 查询引擎在我们退出主进程之前关闭。这样,我们将关机时间从 5-10 秒减少到 1-2 秒。SIGTERM sync.WaitGroup
如果我们不这样做,您在向 WunderBase 关闭时发送请求时最多需要等待 10 秒。
WunderBase 与 DynamoDB、CockroachDB、MongoDB、FaunaDB、Planetscale 或 Neon 等其他无服务器数据库相比如何?
关于无服务器到底是什么,或者这个词是否真的有意义,我们可以进行长时间的辩论。 毕竟,仍然涉及服务器。 对我来说,无服务器意味着您不必担心基础设施 ,您只需为真正使用的东西付费。
长期以来,Serverless 主要是关于功能。 你编写一个函数,部署它,你就完成了。 其他人负责基础设施,您只需按请求付费。
然后出现了新的无服务器产品浪潮,为您提供了“无服务器数据库”。 你编写一个模式,部署它,你就完成了。 但这些真的是 Serverless 吗?
从用户的角度来看,是的。 从技术角度来看,没有。 大多数数据库仍然是“服务器的”,因为数据库服务器始终在运行。
一些解决方案,比如 Neon,试图通过分离计算层和存储层来解决这个问题。 其他的,比如 CockroachDB 或 Mongo 在数据库前面放置了一个代理,这样你就可以“模仿”一个无服务器数据库。
相比之下,WunderBase 的存储层一直在“休眠”,因为它只是一个文件。 SQLite 可能是唯一真正的无服务器数据库,因为它只是一个文件。 WunderBase 的 Serverful 部分是运行 Prisma 查询引擎并在 GraphQL 和 SQL 之间进行转换的代理。 但正如我们之前讨论过的,我们可以让这个代理进入睡眠状态,并在需要时再次唤醒它。
WunderBase 的另一个重要方面是它实际上非常简单且非常透明。 我们有一个在 GraphQL 和 SQL 之间转换的代理, 我们在一个卷上有一个 SQLite 数据库/文件。
我告诉我的一位联合创始人,我对发布 WunderBase 感到有些尴尬,因为它非常简单而且只有几百行代码。 他回答说这根本不令人尴尬,因为我们设法构建了如此简单但又如此强大的东西,这确实令人印象深刻。 他是对的!有时,您以正确的方式组合正确的成分,并实现其他人需要数年才能完成的事情。 我只花了几个小时就建立了 WunderBase。最耗时的部分是编写适当的测试和这篇博文。
WunderBase 的用例是什么?
您可能会认为 WunderBase 只是一个玩具项目。 我们绝对不会与无服务器数据库领域的大玩家竞争。 相反,我们正在研究服务其他人无法服务的用例。
我给你举几个例子:
- 创建一个新的 WunderBase 实例需要几秒钟。您可以将其用于快速原型或测试某些东西。
- 对于您部署的每个分支,您可以拥有一个与主分支/数据库隔离的单独的 WunderBase 实例。
- 许多应用程序存储的数据不超过几 GB,流量也很少。WunderBase 非常适合这些用例。
最让我兴奋的一个用例是您可以在数据库层“分片”。 这意味着您可以拥有跨多个数据库共享的单个数据库模型。 您可以为每个用户、租户或任何其他密钥拥有一个数据库,并根据用户(租户)的 ID 将流量路由到正确的数据库。 如果您的客户拥有大量数据,您可以轻松地将它们放在单独的数据库中。 如果每个客户都有自己的数据库,您可以单独为每个客户执行时间点恢复。
另一个有趣的用例是 OLAP。 假设我们想在几秒钟内分析 TB 的数据。 我们可以跨多个数据库分片数据,并在每个数据库上并行运行查询。 然后我们可以聚合结果并将它们返回给用户。 虽然我们不处理任何请求,但我们可以关闭数据库。 这样,我们只需要为我们使用的存储和计算付费。 这可能是 BigQuery 的开源替代方案。
WunderBase 有多快?
我做了一些基准测试,能够达到每秒 2k 的写入请求和每秒 10k 的读取请求。 WunderBase 存储库中有一个基准测试脚本,您可以使用它来运行自己的基准测试。 确保正确设置速率限制环境变量,以免受到速率限制。 在我的测试过程中,我意识到 2k/10k 是在出现超时错误之前我可以达到的最大值, 因此我为代理添加了一些速率限制以保持一切稳定。
如何扩展 WunderBase?
有多种方法可以扩展 WunderBase。 我们可以添加只读副本来扩展读取。 有工具可以在本地甚至远程复制 SQLite 数据库。 所以我们可以有一个主数据库和不同区域的只读副本。
扩展 WunderBase 的另一种方法是拥有多个主数据库。 通过这种方法,我们可以根据用户 ID 或租户 ID 等键来扩展写入。
如果您的用户遍布世界各地,您可以结合这两种方法来优化延迟。
您可以轻松地从 WunderBase 迁移到不同的数据库吗?
您可能会问的另一个问题是您是否能够从 SQLite 迁移到例如 PostgreSQL 或 MySQL。 答案是肯定的,而且实际上很容易。 当我们使用 Prisma 时,我们只需更改文件中的块中的。如果我们使用相同的 Schema,即使我们使用不同的数据库,Prisma 也会为我们提供相同的 GraphQL API。providerdatasourceprisma.schema
因此,可以从 SQLite 切换到 MySQL、PostgreSQL、SQLServer 甚至 Planetscale。
如何备份 WunderBase?
例如,可以通过利用 LiteStream 来实现备份, 这是一种将更改从 SQLite 数据库流式传输到 S3 的工具。
注意事项
您应该注意一个警告。 WunderBase(Prisma 查询引擎)公开的 GraphQL API 并不打算公开。 您应该始终放置像 WunderGraph 这样的 GraphQL API 网关
此外,Prisma 查询引擎只公开了 GraphQL 的一个子集, 例如你不能使用变量定义。 我们在 WunderGraph 中做了一些额外的步骤以使其与 GraphQL 兼容, 例如编写“变量定义内联器”来自动内联变量定义并使 GraphQL 操作与 Prisma 引擎兼容。 我将跟进有关此主题的博客文章,因为对 Prisma 查询引擎进行逆向工程并使所有这些协同工作实际上非常有趣。
谢谢 Prisma!如果没有 Prisma 团队所做的出色工作,所有这一切都是不可能的。 除了我写的 400 行胶水代码,剩下的就是 Prisma。
我也知道这不是 Prisma 的预期用例。 Nikolas Burk 不断提醒我,Prisma 是一个 ORM,而 Prisma 查询引擎的 GraphQL 层是一个内部细节。 Prisma 在此引擎之上生成一个客户端库,该库在内部使用 GraphQL。
我个人认为直接暴露 GraphQL API 要强大得多。 这样我就可以加入了
所以,谢谢你,很抱歉滥用你的产品!开源太棒了!=)
基于 Firecracker 的应用程序的未来
我对基于 Firecracker 的应用程序的未来感到非常兴奋。 我很确定这种范式将使我们能够以更有效的方式构建或重新构建许多应用程序, 例如无服务器数据库、无服务器缓存、无服务器队列、无服务器搜索引擎等。
下一步是什么?
我们对 WunderGraph 的目标是创建一个 TypeScript 框架,允许您以非常简单的方式构建无服务器应用程序。 从数据库到文件存储、队列、发布/订阅、键值和缓存。 我们希望提供一个统一的 SDK,让您可以专注于代码,而不是基础设施。
原文标题:WunderBase - Serverless GraphQL Database on top of SQLite, Firecracker and Prisma
原文作者:Jens Neuse
原文链接:https://wundergraph.com/blog/wunderbase_serverless_graphql_database_on_top_of_sqlite_firecracker_and_prisma#thank-you-prisma!
