在数据库组件中,一些组件是专用的,如词法解析只用于SQL引擎;而另外一些组件是公共的,用于整个数据库系统。openGauss的公共组件包括系统表、数据库初始化、多线程架构、线程池、内存管理、多维监控和模拟信号机制等。每个组件实现了一个独立的功能。本篇将从系统表、数据库初始化、多线程架构及线程池技术四个方面对公共组件的源代码实现进行介绍。
一、系统表
系统表又称为数据字典或者元数据,存储管理数据库对象的定义信息,如表、索引、触发器等。用户可通过系统表查询用户定义的具体对象信息,如表的每个字段类型。因为openGauss支持一个实例管理多个数据库,所以系统表分为实例级别的系统表和数据库级别的系统表。实例级别的系统表在一个实例管理的多个数据库之间共享,整个实例只有一份,这些系统表为pg_authid、pg_auth_members、pg_database、pg_db_role_setting 、pg_tablespace、pg_shdepend、pg_shdescription、pg_shseclabel。数据库级别的系统表比如pg_class,pg_depend,pg_index,pg_attribute等,每个数据库各有一份。
(一)系统表的定义
openGauss系统表定义全部在src/include/catalog目录下,每个头文件就是一个系统表的定义。如pg_database.h就是对pg_database的定义。在pg_database.h中,主要包括pg_database的表OID(object identifier,对象标识符)、类型OID、结构体定义、字段个数和每个字段ID(identifier,标识符)枚举值、数据库初始化默认值。下面是代码及其具体解释:
/* pg_database本身也是一张表,DatabaseRelationId表示pg_database在系统表pg_class中的OID为1262(pg_class系统表中保存的是表的定义信息) */#define DatabaseRelationId 1262/* pg_database本身也是一个结构类型,DatabaseRelation_Rowtype_Id表示pg_database在系统表pg_type中的OID为1248 */#define DatabaseRelation_Rowtype_Id 1248/* pg_database本身也是一个结构类型,DatabaseRelation_Rowtype_Id表示pg_database在系统表pg_type中的OID为1248 *//* BKI_SHARED_RELATION表示pg_database是实例级别的系统表 */CATALOG(pg_database,1262) BKI_SHARED_RELATION BKI_ROWTYPE_OID(1248) BKI_SCHEMA_MACRO{NameData datname; * 数据库名称 */Oid datdba; * 数据库拥有者 */int4 encoding; * 字符集编码 */NameData datcollate; * LC_COLLATE 设置值 */NameData datctype; * LC_CTYPE 设置值 */bool datistemplate; * 是否允许作为模板数据库*/bool datallowconn; * 是否允许链接 */int4 datconnlimit; * 最大连接数*/Oid datlastsysoid; * 系统OID最大值*/ShortTransactionId datfrozenxid; /* 冻结事务ID,所有小于这个值的事务ID已经冷冻。为了兼容原来的版本,使用32位事务ID*/Oid dattablespace; /* 数据库的缺省表空间 */NameData datcompatibility;/* 数据库兼容模式,比如除0是报错还是当做正常处理*/#ifdef CATALOG_VARLEN /* 下面字段是变长字段 */aclitem datacl[1]; /* 访问权限*/#endifTransactionId datfrozenxid64; /* 冷冻事务ID,64-bit(比特)事务ID */} FormData_pg_database;
CATALOG的宏定义代码为:
#define CATALOG(name,oid) typedef struct CppConcat(FormData_,name)
因此CATALOG(pg_database,1262)就是对结构体FormData_pg_database的定义。之所以采用CATALOG,是因为这个格式是和BKI(backend interface,后端接口)脚本约定的格式,BKI脚本根据这个格式生成数据库的建表脚本。
#define Natts_pg_database 14#define Anum_pg_database_datname 1#define Anum_pg_database_datdba 2#define Anum_pg_database_encoding 3#define Anum_pg_database_datcollate 4#define Anum_pg_database_datctype 5#define Anum_pg_database_datistemplate 6#define Anum_pg_database_datallowconn 7#define Anum_pg_database_datconnlimit 8#define Anum_pg_database_datlastsysoid 9#define Anum_pg_database_datfrozenxid 10#define Anum_pg_database_dattablespace 11#define Anum_pg_database_compatibility 12#define Anum_pg_database_datacl 13#define Anum_pg_database_datfrozenxid64 14
DATA(insert OID = 1 ( template1 PGUID ENCODING "LC_COLLATE" "LC_CTYPE" t t -1 0 0 1663 "DB_COMPATIBILITY" _null_ 3));SHDESCR("default template for new databases");#define TemplateDbOid 1#define DEFAULT_DATABASE "postgres" /* 表示创建默认数据库的名称为postgres */
(二)系统表的访问
{DatabaseRelationId, /* DATABASEOID */DatabaseOidIndexId,1,{ObjectIdAttributeNumber, 0, 0, 0},4},
struct cachedesc {Oid reloid; /* 缓存的表的OID */Oid indoid; /* 缓存数据的索引OID */int nkeys; /* 缓存搜索的key的个数 */int key[4]; /* key属性的编号*/int nbuckets; /* 缓存hash桶的个数*/};
其他系统表的逻辑与pg_database相似,不再重复。
二、数据库初始化

initdb在创建template1模板数据库时,命令参数指定了“snprintf_s(cmd, sizeof(cmd), sizeof(cmd) - 1, "\"%s\" --boot -x1 %s %s", backend_exec, boot_options, talkargs);”,其中“--boot”表示openGauss进程以一个特殊的bootstrap模式运行。在其他初始化系统表时,initdb命令参数指定了“snprintf_s(cmd, sizeof(cmd), sizeof(cmd) - 1, "\"%s\" %s template1 >%s", backend_exec, backend_options, DEVNULL); ”,其中“static const char* backend_options = "--single "”表示openGauss进程以单用户模式运行。
static void setup_schema(void){PG_CMD_DECL;char** line;char** lines;int nRet = 0;char* buf_features = NULL;fputs(_("creating information schema ... "), stdout);(void)fflush(stdout);lines = readfile(info_schema_file);/** 使用-j 避免在information_schema.sql反斜杠处理*/nRet = snprintf_s(cmd, sizeof(cmd), sizeof(cmd) - 1, "\"%s\" %s -j template1 >%s", backend_exec, backend_options, DEVNULL);securec_check_ss_c(nRet, "\0", "\0");PG_CMD_OPEN;for (line = lines; *line != NULL; line++) {PG_CMD_PUTS(*line);FREE_AND_RESET(*line);}FREE_AND_RESET(lines);PG_CMD_CLOSE;nRet = snprintf_s(cmd, sizeof(cmd), sizeof(cmd) - 1, "\"%s\" %s template1 >%s", backend_exec, backend_options, DEVNULL);securec_check_ss_c(nRet, "\0", "\0");PG_CMD_OPEN;PG_CMD_PRINTF1("UPDATE information_schema.sql_implementation_info "" SET character_value = '%s' "" WHERE implementation_info_name = 'DBMS VERSION';\n",infoversion);buf_features = escape_quotes(features_file);PG_CMD_PRINTF1("COPY information_schema.sql_features "" (feature_id, feature_name, sub_feature_id, "" sub_feature_name, is_supported, comments) "" FROM E'%s';\n",buf_features);FREE_AND_RESET(buf_features);PG_CMD_CLOSE;check_ok();}
在这个函数中,PG_CMD_DECL是一个变量定义宏,通过语句“char cmd[MAXPGPATH]”和“FILE* cmdfd = NULL”定义了两个变量。这样的作用是代码格式统一、阅读方便。
语句“readfile(info_schema_file)”表示读取info_schema_file文件,这个文件中存放了系统表初始化的SQL命令。
语句“snprintf_s(cmd, sizeof(cmd), sizeof(cmd) - 1, "\"%s\" %s -j template1 >%s", backend_exec, backend_options, DEVNULL)”是格式化openGauss后台进程的命令。语句“PG_CMD_OPEN”是以popen的方式运行cmd命令,启动openGauss进程。
语句“for (line = lines; *line != NULL; line++)” 表示遍历info_schema_file文件中的每条SQL命令,宏PG_CMD_PUTS把每个SQL命令发送给openGauss进程执行。
整个文件执行完毕,调用宏PG_CMD_CLOSE停止进程,关闭管道。setup_schema函数的后面代码处理是类似的,只是SQL命令是函数内生成的,使用宏PG_CMD_PRINTF1写入管道,发给openGauss进程。
setup_sysviews、setup_dictionary、setup_privileges等其他系统对象初始化函数过程都是类似的,不再重复描述。
initdb的整个初始化过程如下。
(1)对命令行参数进行解析。
(2)查找openGauss程序,设置$PGDATA、$PGPATH等环境变量。设置数据库初始化原始文件postgres.bki、postgres.description、postgres.shdescription、postgresql.conf.sample、mot.conf.sample、pg_hba.conf.sample、pg_ident.conf.sample。这些文件在shell命令make install执行安装后,默认都在“openGauss-server/dest/share/postgresql”目录下。
(3)数据库本地初始化,locale默认初始化为en_US.UTF-8,数据库编码默认初始化为UTF8,文本搜索默认初始化为english。
(4)检查数据库数据目录pg_data是否为空,是否需要创建,权限是否正确。
(5)创建subdirs变量指定的子目录。
(6)初始化postgresql.conf配置文件。
(7)创建template1数据库bootstrap_template1。这一步需要启动后台openGauss进程执行数据库的SQL语句,创建系统表。bootstrap_template1这个函数主要是读取postgres.bki文件中的SQL语句,发送到openGauss进程去执行,主要功能是创建系统表。SQL语句举例如下,其中语句create pg_type表示创建pg_type系统表,语句INSERT OID表示插入这个系统表的默认数据。这里的语法是专门为initdb定制的bootstrap解析语法,不是正式的SQL语法,语法文件也是单独的,可参照“openGauss-server\src\gausskernel\bootstrap”目录下的bootscanner.l和bootparse.y文件。pg_type系统对象在initdb初始化中的bootstrap语法相关代码如下,在初始化时就是解析下面语法格式完成pg_type系统对象的创建:
create pg_type 1247 bootstrap rowtype_oid 71(typname = name ,typnamespace = oid ,typowner = oid ,typlen = int2 ,typbyval = bool ,typtype = char ,typcategory = char ,typispreferred = bool ,typisdefined = bool ,typdelim = char ,typrelid = oid ,typelem = oid ,typarray = oid ,typinput = regproc ,typoutput = regproc ,typreceive = regproc ,typsend = regproc ,typmodin = regproc ,typmodout = regproc ,typanalyze = regproc ,typalign = char ,typstorage = char ,typnotnull = bool ,typbasetype = oid ,typtypmod = int4 ,typndims = int4 ,typcollation = oid ,typdefaultbin = pg_node_tree ,typdefault = text ,typacl = aclitem[])INSERT OID = 16 ( bool 11 10 1 t b B t t \054 0 0 1000 boolin boolout boolrecv boolsend - - - c p f 0 -1 0 0 _null_ _null_ _null_ )INSERT OID = 17 ( bytea 11 10 -1 f b U f t \054 0 0 1001 byteain byteaout bytearecv byteasend - - - i x f 0 -1 0 0 _null_ _null_ _null_ )...........close pg_type
(8)使用setup_auth函数初始化pg_authid权限。该函数执行的SQL语句是在函数内静态定义“static const char* pg_authid_setup[]”。
(9)使用setup_depend函数创建系统表依赖关系。该函数执行的SQL语句是在函数内静态定义“static const char* pg_depend_setup[]”。
(10)使用load_plpgsql函数加载plpgsql扩展组件。该函数只执行一条SQL语句“CREATE EXTENSION plpgsql;”。
(11)使用setup_sysviews函数创建系统视图。该函数会读取system_views.sql文件中的SQL语句,发送到openGauss去执行,主要功能是创建系统视图。
(12)使用setup_perfviews函数创建性能视图。该函数会读取performance_views.sql文件中的SQL语句,发送到openGauss去执行,主要功能是创建性能视图。
(13)使用setup_conversion函数创建编码转换。该函数会读取conversion_create.sql文件中的SQL语句,发送到openGauss去执行,主要功能是创建编码转换函数。
(14)使用setup_dictionary函数创建词干数据字典。该函数会读取snowball_create.sql文件中的SQL语句,发送到openGauss去执行,主要功能是创建文本搜索函数。
(15)使用setup_privileges函数设置权限。setup_privileges函数通过xstrdu复制SQL常量字符串到一个动态数组内,然后遍历执行指定的SQL语句。
(16)使用load_supported_extension函数加载外表。该函数执行相应扩展组件的CREATE EXTENSION语句。
(17)使用setup_update函数更新系统表。该函数执行语句COPY pg_cast_oid.txt到数据库中,主要功能是创建类型强制转换处理函数。
(18)对template1进行垃圾数据清理,即执行三个SQL语句“ANALYZE;”、“VACUUM FULL;”、“VACUUM FREEZE;”。
(19)创建template0数据库,即复制template1到template0。
(20)创建postgres数据库,即复制template1到postgres。
(21)对template0、template1、postgres进行垃圾数据清理和事务ID冻结。
三、多线程架构
openGauss内核源自PostgreSQL,但在架构上进行了大量改造,其中一个调整就是将多进程架构修改为多线程架构。openGauss在启动后只有一个进程,后台任务都是以一个进程中的线程来运行。对于客户端的新连接,在非线程池模式下也是以启动一个业务线程来处理。在多线程架构下更容易实现多个线程资源的共享,如并行查询、线程池等。
(一)openGauss主要线程
表1 后台线程的功能
后台线程 | 功能介绍 |
Postmaster | openGauss数据库主线程。主要有两个功能:一是对连接进行监听,接收新的连接;二是监控所有子线程的状态,并且根据子线程退出状态进行处理,如果线程是FATAL退出,则重新拉起子线程。如果线程是PANIC退出,则进行整个数据库重新初始化。保证数据库的正常运行 |
Startup | 数据库启动线程。数据库启动时Postmaster主线程拉起的第一个子线程,主要完成数据库的日志REDO(重做)操作,进行数据库的恢复。日志REDO操作结束,数据库完成恢复后,如果不是备机,Startup线程就退出了。如果是备机,那么Startup线程一直在运行,REDO备机接收到新的日志 |
Bgwriter | 后台数据写线程。周期性的把数据库数据缓冲区的内容同步到磁盘上 |
Checkpointer | 检查点线程。进行检查点操作,完成数据库的周期性检查点和执行检查点命令 |
Walwriter | 后台WAL写线程。主要功能是周期性的把日志缓冲区的内容同步到磁盘上 |
Stat | 数据库运行信息统计收集线程。主要功能是收集各个线程操作数据库数据的统计信息,进行汇总后写入数据库的统计文件中,供查询优化分析和垃圾清理使用 |
Sysloger | 运行日志写线程。主要功能是把各个线程的运行日志信息写到运行日志文件中 |
Vacuum Launch | 垃圾清理启动线程。主要有两个功能:一是通知Postmaster 启动一个垃圾清理线程;二是平衡各个垃圾清理线程的负载 |
Vacuum worker | 垃圾清理线程。主要功能是对openGauss数据库的垃圾数据进行清理 |
Arch | 日志归档线程。主要功能是完成归档操作,把在线日志拷贝到归档目录 |
Postgres | 服务线程。在非线程池模式下,每个客户端连接对应一个服务线程,主要功能是接收客户端的操作请求,代表客户端在服务器完成数据库操作 |
通信方式 | 说明 |
共享内存 | 在数据库初始化时,Postmaster线程通过OS(操作系统)申请一块大的共享内存,并且完成初始化工作。openGauss使用到的所有共享内存都是这块内存的一部分。线程之间的一些信息交换就是通过共享内存完成的,共享内存的访问需要加锁保护 |
信号 | 对于一些紧急任务的处理,openGauss使用信号通知作为线程间通信的手段。因为信号可以中断处理线程当前的任务,立即响应信号对应的任务 |
TCP | 客户端连接数据库服务器时,一般使用TCP进行通信 |
UNIX域套接字协议 | 如果是本地客户端,即客户端和服务器在同一个机器上,并且是UNIX操作系统,可以使用UNIX域套结字协议建立客户端和服务器进程的通信 |
UDP | UDP(user datagram protocol,用户数据报协议)是不可靠协议,主要用于后台线程向统计线程发送统计信息时使用 |
管道 | 管道可以是双向的,也可以是单向的。在openGauss中,主要使用了单向管道,用在后台线程向运行日志守护线程发送运行日志信息时使用 |
文件 | 主要用于一些不太重要的场合,并且通信量比较大。在openGauss中,主要用在统计线程汇总统计信息,写到统计文件,供垃圾清理线程和后台服务器线程成本优化使用 |
全局变量 | 一种线程间共享信息的机制。openGauss对原来的PostgreSQL中进程内的全局变量添加THR_LOCAL定义为线程的局部变量,避免线程之间误用 |
(1) 进行Postmaster的Context初始化,初始化GUC参数,解析命令行参数。
(2) 调用StreamServerPort函数启动服务器监听和双机监听(如果配置了双机),调用reset_shared函数初始化共享内存和LWLock锁,调用gs_signal_monitor_startup函数注册信号处理线程,调用InitPostmasterDeathWatchHandle函数注册Postmaster死亡监控管道,把openGauss进程信息写入pid_file文件中,调用gspqsignal函数注册Postmaster的信号处理函数。
(3) 根据配置初始化黑匣子,调用pgstat_init函数初始化统计信息传递使用的UDP套接字通信,调用InitializeWorkloadManager函数初始化负载管理器,调用InitUniqueSQL函数初始化UniqueSQL,调用SysLogger_Start函数初始化运行日志的通信管道和SYSLOGGER线程,调用load_hba函数加载hba鉴权文件。
(4) 调用initialize_util_thread函数启动STARTUP线程,调用ServerLoop函数进入一个周期循环。在ServerLoop函数的周期循环中,进行客户端请求监听,如果有客户端连接请求,在非线程池模式下,则调用BackendStartup函数创建一个后台线程worker处理客户请求。在线程池模式下,把新的链接加入一个线程池组中。在ServerLoop函数的周期循环中,检查其他线程的运行状态。如果数据库是第一次启动,则调用initialize_util_thread函数启动其他后台线程。如果有后台线程FATAL级别错误退出,则调用initialize_util_thread函数重新启动该线程。如果是PANIC级别错误退出,则整个实例进行重新初始化。
ThreadId initialize_thread(ThreadArg* thr_argv){gs_thread_t thread;if (0 != gs_thread_create(&thread, InternalThreadFunc, 1, (void*)thr_argv)) {gs_thread_release_args_slot(thr_argv);return InvalidTid;}return gs_thread_id(thread);}
InternalThreadFunc函数的代码如下。该函数根据角色调用GetThreadEntry函数,GetThreadEntry函数直接以角色为下标,返回对应GaussdbThreadEntryGate数组对应的元素。数组的元素是处理具体任务的回调函数指针,指针指向的函数为GaussDbThreadMain。相关代码如下所示:
static void* InternalThreadFunc(void* args){knl_thread_arg* thr_argv = (knl_thread_arg*)args;gs_thread_exit((GetThreadEntry(thr_argv->role))(thr_argv));return (void*)NULL;}GaussdbThreadEntry GetThreadEntry(knl_thread_role role){Assert(role > MASTER && role < THREAD_ENTRY_BOUND);return GaussdbThreadEntryGate[role];}static GaussdbThreadEntry GaussdbThreadEntryGate[] = {GaussDbThreadMain<MASTER>,GaussDbThreadMain<WORKER>,GaussDbThreadMain<THREADPOOL_WORKER>,GaussDbThreadMain<THREADPOOL_LISTENER>,......};
在GaussDbThreadMain函数中,首先初始化线程基本信息,Context和信号处理函数,接着就是根据thread_role角色的不同调用不同角色的处理函数,进入各个线程的main函数,比如GaussDbAuxiliaryThreadMain函数、AutoVacLauncherMain函数、WLMProcessThreadMain函数等。其中GaussDbAuxiliaryThreadMain函数是后台辅助线程处理函数。该函数的处理也类似GaussDbThreadMain函数,根据thread_role角色的不同调用不同角色的处理函数,进入各个线程的main函数,比如StartupProcessMain函数、CheckpointerMain函数、WalWriterMain函数、walrcvWriterMain函数等。
总结上面整个过程,openGauss多线程架构主要包括3个方面:
(1) 多线程之间的通信,由主线程在初始化阶段完成。
(2) 多线程的启动,由主线程创建各个角色线程,调用不同角色的处理函数完成。
(3) 主线程负责监控各个线程的运行,异常退出和重新拉起。
四、线程池技术
openGauss在多线程架构的基础上,实现了线程池。线程池机制实现了会话和处理线程分离,在大并发连接的情况下仍然能够保证系统有很好的SLA响应。另外不同的线程组可绑到不同的NUMA(non-uniform memory access,非一致性内存访问)核上,天然匹配NUMA化的CPU架构,从而提升openGauss的整体性能。
(一)线程池原理
openGauss线程池机制原理如图2所示,图中的主要对象如表3所示。
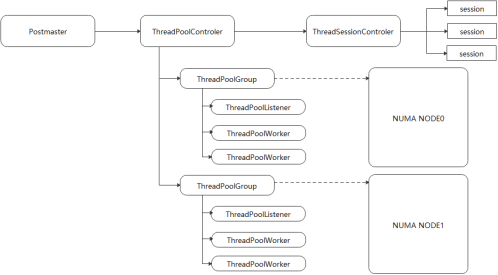
|图2 线程池机制原理|
表3 线程池对象
对象 | 说明 |
Postmaster | 主线程。负责监听客户端发出的请求 |
ThreadPoolControler | 线程池总控。负责线程池的初始化和资源管理 |
ThreadSessionControler | 会话生命周期管理 |
ThreadPoolGroup | 线程组。可以定义灵活的线程数量和绑核策略 |
ThreadPoolListener | 线程组监听线程。负责事件的分发和管理 |
ThreadPoolWorker | 工作线程 |
session | 客户端连接的一个会话 |
NUMA NODE | NUMA节点。表示一个线程组在NUMA结构下可以映射到一个NUMA节点上 |
这些对象相互配合实现了线程池机制,它们的主要交互过程如下。
(1)客户端向数据库发起连接请求,Postmaster线程接收到连接请求并被唤醒。Postmaster线程创建该连接对应的socket,调用ThreadPoolControler函数创建会话(session)数据结构。ThreadPoolControler函数遍历当前所有的Thread Group(线程组),找到当前活跃会话数量最少的Thread Group,并把最新的会话分发给该Thread Group,加入该Thread Group的epoll列表之中。
(2)Thread Group的listener线程负责监听epoll列表中所有的客户连接。
(3)客户端发起任务请求,listener线程被唤醒。listener线程检查当前的Thread Group是否有空闲worker线程;如果有,则把当前会话分配给该worker线程,并唤醒该worker线程;如果没有,则把该会话放在等待队列之中。
(4)worker线程被唤醒后,读取客户端连接上的请求,执行相应请求,并返回请求结果。在一次事务结束(提交、回滚)或者事务超时退出的时候,worker线程的一次任务完成。worker线程将session返回给listener线程,listener线程继续等待该会话的下一次请求。worker线程返还会话后,检查会话等待队列;如果存在等待响应请求的会话,则直接从该队列中取出新的会话并继续工作;如果没有等待响应的session,则将自身标记为free(空闲)状态,等待listener线程唤醒。
(5)客户端断开连接时,worker线程被唤醒,关闭连接,同时清理会话相关结构,释放内存和fd(文件句柄)等资源。
(6)如果worker线程FATAL级别错误退出,退出时worker线程会从worker队列中注销掉。此时listener线程会重新启动一个新的worker线程,直到达到指定数量的worker线程。
(二)线程池实现
线程池功能由GUC参数enable_thread_pool控制,该变量设置为true时才能使用线程池功能。代码主要在“openGauss-server/src/gausskernel/process/threadpool”目录中,下面介绍主要代码实现流程。
if (threadPoolActivated) {bool enableNumaDistribute = (g_instance.shmem_cxt.numaNodeNum > 1);g_threadPoolControler->Init(enableNumaDistribute);}
Postmaster线程在ServerLoop中如果监听到有客户端链接请求,判断启用了线程池功能,则会调用“ThreadPoolControler::DispatchSession”函数进行会话分发。相关代码如下:
if (threadPoolActivated &&!(i < MAXLISTEN && t_thrd.postmaster_cxt.listen_sock_type[i] == HA_LISTEN_SOCKET))result = g_threadPoolControler->DispatchSession(port);/* ThreadPoolControler::DispatchSession的代码实现如下,找到一个会话数最少的线程组,创建会话,把会话添加到线程组的监听线程中 */int ThreadPoolControler::DispatchSession(Port* port){ThreadPoolGroup* grp = NULL;knl_session_context* sc = NULL;grp = FindThreadGroupWithLeastSession();if (grp == NULL) {Assert(false);return STATUS_ERROR;}sc = m_sessCtrl->CreateSession(port);if (sc == NULL)return STATUS_ERROR;grp->GetListener()->AddNewSession(sc);return STATUS_OK;}
(1)worker线程准备就绪的通知。
(2)等待会话通知。
(3)连接退出处理。
worker线程的相关代码如下:
if (IS_THREAD_POOL_WORKER) {u_sess->proc_cxt.MyProcPort->sock = PGINVALID_SOCKET;t_thrd.threadpool_cxt.worker->NotifyReady();}if (IS_THREAD_POOL_WORKER) {t_thrd.threadpool_cxt.worker->WaitMission();Assert(u_sess->status != KNL_SESS_FAKE);}case 'X':case EOF:RemoveTempNamespace();InitThreadLocalWhenSessionExit();if (IS_THREAD_POOL_WORKER) {t_thrd.threadpool_cxt.worker->CleanUpSession(false);break;}