




本文将通过在mysql中对地理位置信息存储的例子出发,在熟悉mysql对GIS的支持特性的同时,也会讲述如果利用geohash对查询性能优化,以及如果解决geohash在直接匹配时所产生的Peano空间曲线突变性误差,文章最后讲解如果利用8位邻近的geohash区域去解决这个突变性误差问题。

在mysql数据库中进行对geohash实战的演示。建表脚本如下:
CREATE TABLE `gis_info` (
`id` int unsigned auto_increment,
`name` varchar(10) NOT NULL COMMENT '地理位置名称',
`location` geometry NOT NULL COMMENT '空间位置信息',
`geo_hash` varchar(20) GENERATED ALWAYS AS (st_geohash(`location`,8)) VIRTUAL,
PRIMARY KEY (`id`),
UNIQUE KEY `id` (`id`),
SPATIAL KEY `idx_location` (`location`),
KEY `idx_geo_hash` (`geo_hash`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='空间位置信息';
利用百度拾取坐标系统(http://api.map.baidu.com/lbsapi/getpoint/index.html)
拾取坐标数据复制
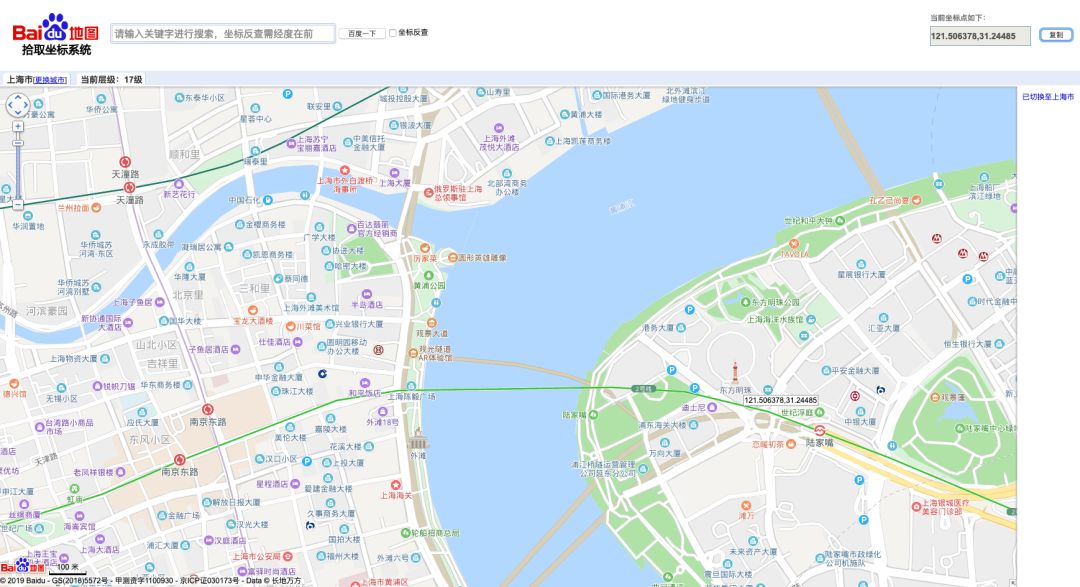
insert into gis_info(name, location) values
('陆家嘴中心绿地', ST_GeomFromText('point(121.513079 31.243777)')),
('人民广场', ST_GeomFromText('point(121.482106 31.238651)')),
('中信广场', ST_GeomFromText('point(121.490945 31.254196)')),
('黄埔公园', ST_GeomFromText('point(121.497484 31.247497)')),
('东方明珠', ST_GeomFromText('point(121.506396 31.244564)')),
('上海外滩', ST_GeomFromText('point(121.497233 31.243298)')),
('南京东路', ST_GeomFromText('point(121.490316 31.242912)'));复制
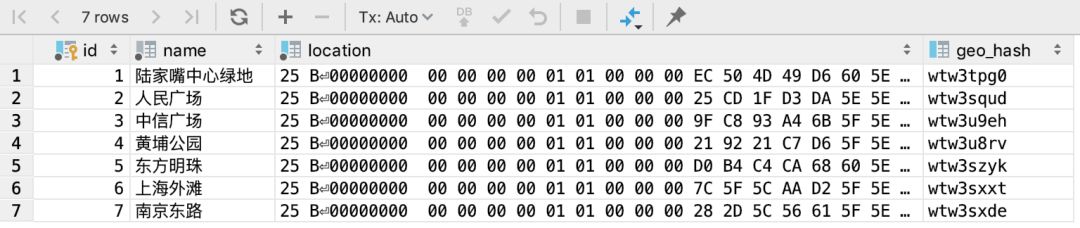
查询刚才插入数据的语句:select * from gis_info;复制
接下来进行几个简单的查询例子:
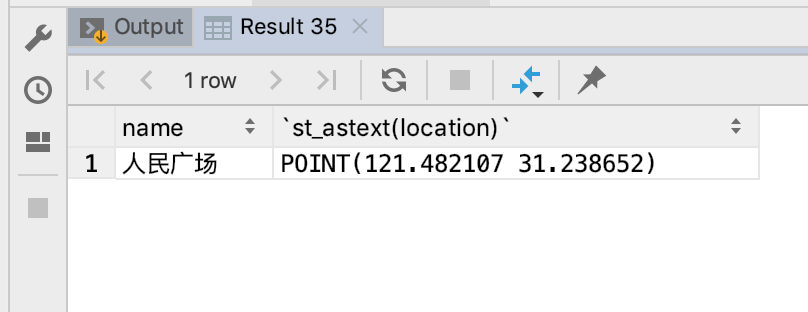
(1)查询人民广场的经纬度信息
select name, st_astext(location) from gis_info where name = '人民广场';复制
查询结果如下:

(2)修改人民广场的位置信息
update gis_info set location = st_geomfromtext('point(121.482107 31.238652)') where name = '人民广场';复制
再执行查询
select name, st_astext(location) from gis_info where name = '人民广场';
查询结果如下:
(3) 查询人民广场到南京东路的距离(单位米):
select floor(st_distance_sphere(
(select location from gis_info where name= '人民广场'),
location
)) distance from gis_info where name= '南京东路';复制
查询结果如下:

南京东路到人民广场的实地距离为912米。
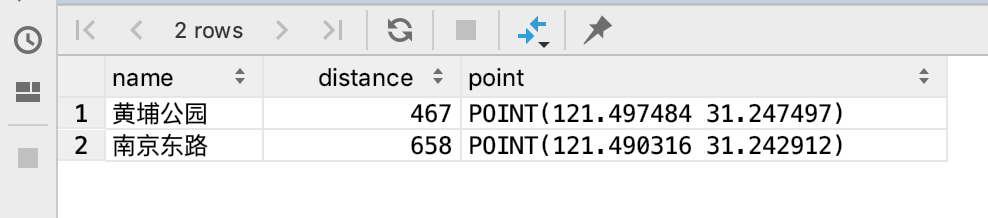
(4)查询上海外滩700米以内所有地点(单位米):
SELECT name,
floor(st_distance_sphere((SELECT location
FROM gis_info
WHERE name = '上海外滩'),
location)) distance,
st_astext(location) point
FROM gis_info
WHERE st_distance_sphere((SELECT location
FROM gis_info
WHERE name = '上海外滩'),
location) < 700 AND name != '上海外滩';复制
查询结果如下:
前面说过geohash是把经纬度转成字符串,建表的时候我定义让它转成8位字符,当两个点离得越近时,它生成的geohash字符串前面相同的位数越多,所以我在这里先用left()截取前6位字符,前6位相同的误差在±610米左右,然后模糊查询,查出大概符合条件的数据,最后再精确比较,下面是geohash官方文档对geohash长度和距离误差的说明:
| geohash长度 | 误差距离(km) |
|---|---|
| 1 | ±2500 |
| 2 | ±630 |
| 3 | ±78 |
| 4 | ±20 |
| 5 | ±2.4 |
| 6 | ±0.61 |
| 7 | ±0.076 |
| 8 | ±0.019 |
但是如果在千万条数据的数据库中直接执行上述的查询语句,将会发生很严重的性能问题,因为直接的距离计算将会给计算机cpu带来很大的计算开销,而且一般情况下,地理信息表存储的数据量都是非常大的,所以我们必须做性能优化。现在我们在进行一个实验,我们在查询的时候加上一个geohash的筛选条件,这样查询的话可以利用geohash大大的缩小查询范围,避免sql查询不必要的计算带来的性能消耗。此时我们根据精度表匹配geohash的前6位,也就是说精度限定在610米左右。
SELECT name,
floor(st_distance_sphere((SELECT location
FROM gis_info
WHERE name = '上海外滩'),
location)) distance,
st_astext(location) point
FROM gis_info
WHERE geo_hash like concat(left((select geo_hash from gis_info where name = '上海外滩'), 6), '%')
and st_distance_sphere((SELECT location
FROM gis_info
WHERE name = '上海外滩'),
location) < 700 AND name != '上海外滩';复制
此时我们观察一下查询结果:
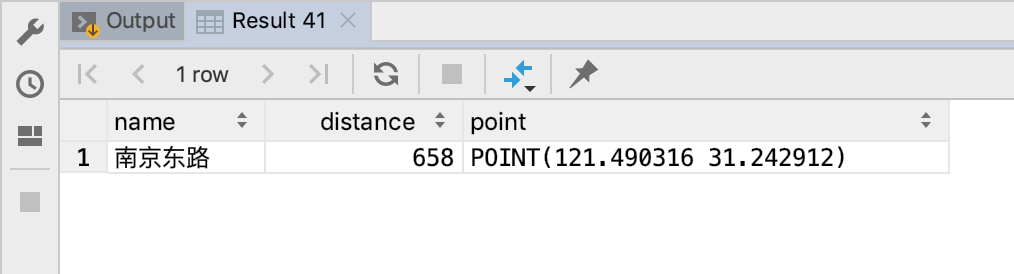
我们发现在上海外滩700米以内且精度在610米左右的只剩南京东路。但是黄埔公园467米竟然没有查到,这说明了一个问题,geohash本身是有误差的。如图:
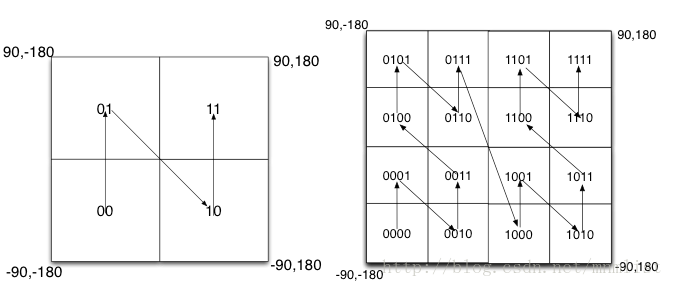
我们回顾一下geohash的原理:当空间划分为4块的时候我们,b编码顺序依次是左下角00,左上角01,右下角10,右上角11,类似于倒下的Z字形。当我们递归分解的时候,如右图所示,每一个子块也形成了Z形线。这种类型称为Peano空间曲线。这种类型的空间填充曲线的优点是将二维空间转换成一维曲线(事实上是分形维),对大部分而言,编码相似的距离也相近, 但Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,比如0111与1000,编码是相邻的,但距离相差很大。(此段引用https://www.jianshu.com/p/c4ad9cadd352的部分表述)
为了克服Peano空间曲线这个缺点,我们采用了计算出该查找地点的相邻的8个geohash值的解决方案。以下是经纬度的精度误差表:
| geohash length | lat bits | lng bits | lat error | lng error | km error |
|---|---|---|---|---|---|
| 1 | 2 | 3 | ±23 | ±23 | ±2500 |
| 2 | 5 | 5 | ±2.8 | ±5.6 | ±630 |
| 3 | 7 | 8 | ±0.70 | ±0.70 | ±78 |
| 5 | 12 | 13 | ±0.022 | ±0.022 | ±2.4 |
| 6 | 15 | 15 | ±0.0027 | ±0.0055 | ±0.61 |
| 7 | 17 | 18 | ±0.00068 | ±0.00068 | ±0.076 |
我们参照精度表,直接用mysql内置函数查找6位精度的邻近8块geohash区域(离上海外滩的610米附近的8块邻近geohash区域):
select st_geohash(POINT(121.490316 + 0.0055, 31.242912), 6) as '右边',
st_geohash(POINT(121.490316 - 0.0055, 31.242912), 6) as '左边',
st_geohash(POINT(121.490316, 31.242912 + 0.0027), 6) as '上边',
st_geohash(POINT(121.490316, 31.242912 - 0.0027), 6) as '下边',
st_geohash(POINT(121.490316 + 0.0055, 31.242912 + 0.0027), 6) as '右上',
st_geohash(POINT(121.490316 + 0.0055, 31.242912 - 0.0027), 6) as '右下',
st_geohash(POINT(121.490316 - 0.0055, 31.242912 + 0.0027), 6) as '左上',
st_geohash(POINT(121.490316 - 0.0055, 31.242912 - 0.0027), 6) as '左下';
查询结果如下:复制

在地图上则近似为以下的划分范围
:

我们发现根据geohash前缀的前6位直接匹配的时候,黄埔公园和外滩只有467米的距离,结果geohash值却不一样,此时如果我们用6位精度的邻近8块的geohash区域去圈定这个矩形区域的时候,这个问题就解决了,误差也被消除了。看如下的查询语句:
SELECT name,
floor(st_distance_sphere((SELECT location
FROM gis_info
WHERE name = '上海外滩'),
location)) distance,
st_astext(location) point
FROM gis_info
WHERE (geo_hash like concat(left((select geo_hash from gis_info where name = '上海外滩'), 6), '%')
or geo_hash like concat('wtw3sx', '%')
or geo_hash like concat('wtw3sr' ,'%')
or geo_hash like concat('wtw3u8', '%')
or geo_hash like concat('wtw3sx', '%')
or geo_hash like concat('wtw3u8', '%')
or geo_hash like concat('wtw3sx', '%')
or geo_hash like concat('wtw3u2', '%')
or geo_hash like concat('wtw3sr', '%'))
and st_distance_sphere((SELECT location
FROM gis_info
WHERE name = '上海外滩'),
location) < 700
and name != '上海外滩';复制
查询结果如图:

这正是我们想要的结果。特别注意的是在我们计算邻近的8块区域的时候,要注意精度的误差,比如要查询2千米以内的地点时,我们就要用计算8个邻近的5位的geohash值(5位的geohash值的区域精度是2.4km)进行匹配,而8个邻近的6位的geohash值则不符合匹配要求,会产生结果漏查。
综上所述,我们现在知道了geohash的用处,它是用来对查询的性能进行优化的一个索引字段方案,我们设想一下,在地理位置信息表里面有千万级别的数据,我们如果没有geohash方案的情况下,直接进行距离计算,这是非常消耗性能的(球面计算距离时的sin和cos函数是非常吃cpu性能的),如果利用geohash做查询条件进行缩小区域在进行距离的筛选的话,我们可以大大的减少目标数据计算的数据量,很有效的提高了应用的响应速度和性能。但是由于geohash直接进行匹配是存在Peano空间曲线突变性缺陷的,所以后面设计了利用邻近8个点的方案来解决这一突变性缺陷所产生的精度不准确问题。geohash是一种解决问题的思想,并不局限于在mysql中运用,地理信息数据的存储同样可以放在其他类型的数据库中进行运用。
