




数据库对象验证在数据库迁移过程中起着关键作用。这是一个通过比较所有源数据库对象的类型和计数来确定它们是否已成功迁移到目标数据库的过程。如果跳过验证阶段,可能会由于缺少数据库对象而遇到运行时错误,这可能会阻碍单元测试和代码部署。
在从Microsoft SQL Server迁移到Amazon RDS for PostgreSQL和Amazon Aurora PostgreQL后验证数据库对象中,我们讨论了从Microsoft SQL服务器迁移到AmaAmazon Relational database Service(Amazon RDS)for PostgeSQL和Amazon Aurora PostgreSQL Compatible Edition的验证。在本文中,我们讨论了从Microsoft SQL Server迁移到Amazon RDS for MySQL或Amazon Aurora MySQL兼容版时的数据库对象验证。
数据库对象验证
下面的列表包含我们使用计数和详细级别信息验证的各种类型的数据库对象,这有助于我们识别丢失或部分迁移的数据库对象。我们忽略源数据库和目标数据库中的系统模式。
-
架构
-
表
-
视图
-
存储过程
-
功能
-
索引
-
触发器
-
制约因素
让我们深入研究每种对象类型及其验证过程。我们可以使用SQL Server Management Studio(SSMS)连接到Microsoft SQL Server数据库和MySQL Workbench,连接到我们的RDS for MySQL或Aurora MySQL数据库,并运行以下查询来验证每个对象。
架构
模式用于表示为应用程序或微服务中的相关功能提供服务的数据库对象的集合。让我们使用以下查询验证源数据库和目标数据库中的模式。
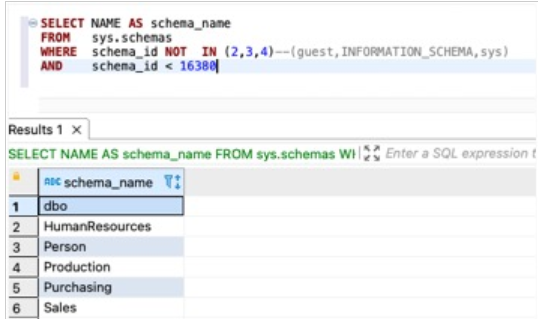
对于SQL Server,请使用以下查询:
SELECT NAME AS schema_name
FROM sys.schemas
WHERE schema_id NOT IN (2,3,4)--(guest,INFORMATION_SCHEMA,sys)
AND schema_id < 16380 –- (ignoring system schemas)
以下屏幕截图显示了我们的输出。
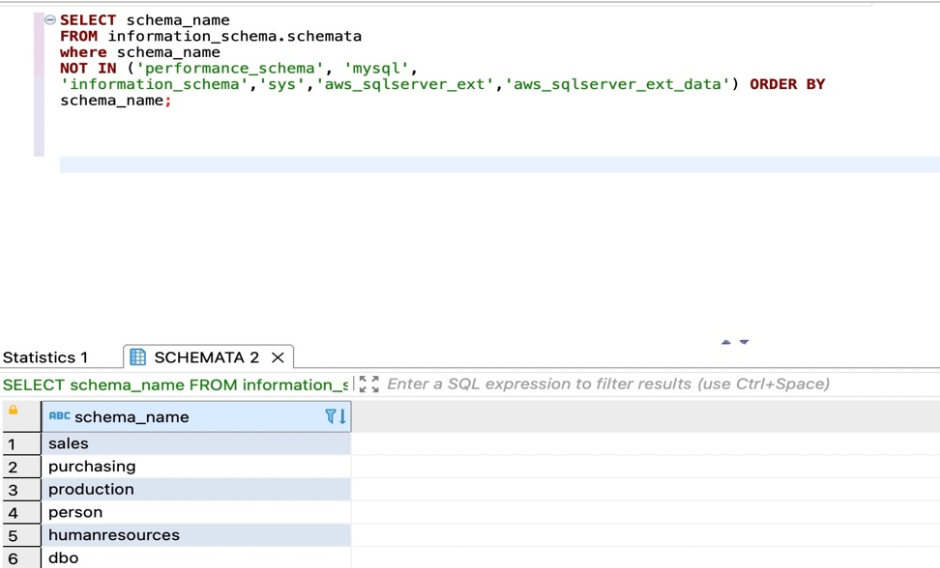
对于Amazon RDS For MySQL或Aurora MySQL,您有以下代码选项:
SELECT schema_name FROM information_schema.schemata
where schema_name
NOT IN ('performance_schema', 'mysql', 'information_schema','sys','aws_sqlserver_ext','aws_sqlserver_ext_data')
ORDER BY schema_name;
以下屏幕截图显示了我们的输出。
表
AWS架构转换工具(AWS SCT)使用应用的默认或自定义映射规则,将源SQL Server表转换为具有适当数据类型和相对表定义的等效目标(MySQL)表。假设源数据库没有任何分区表,以下脚本将返回所有表的计数和详细级别信息。
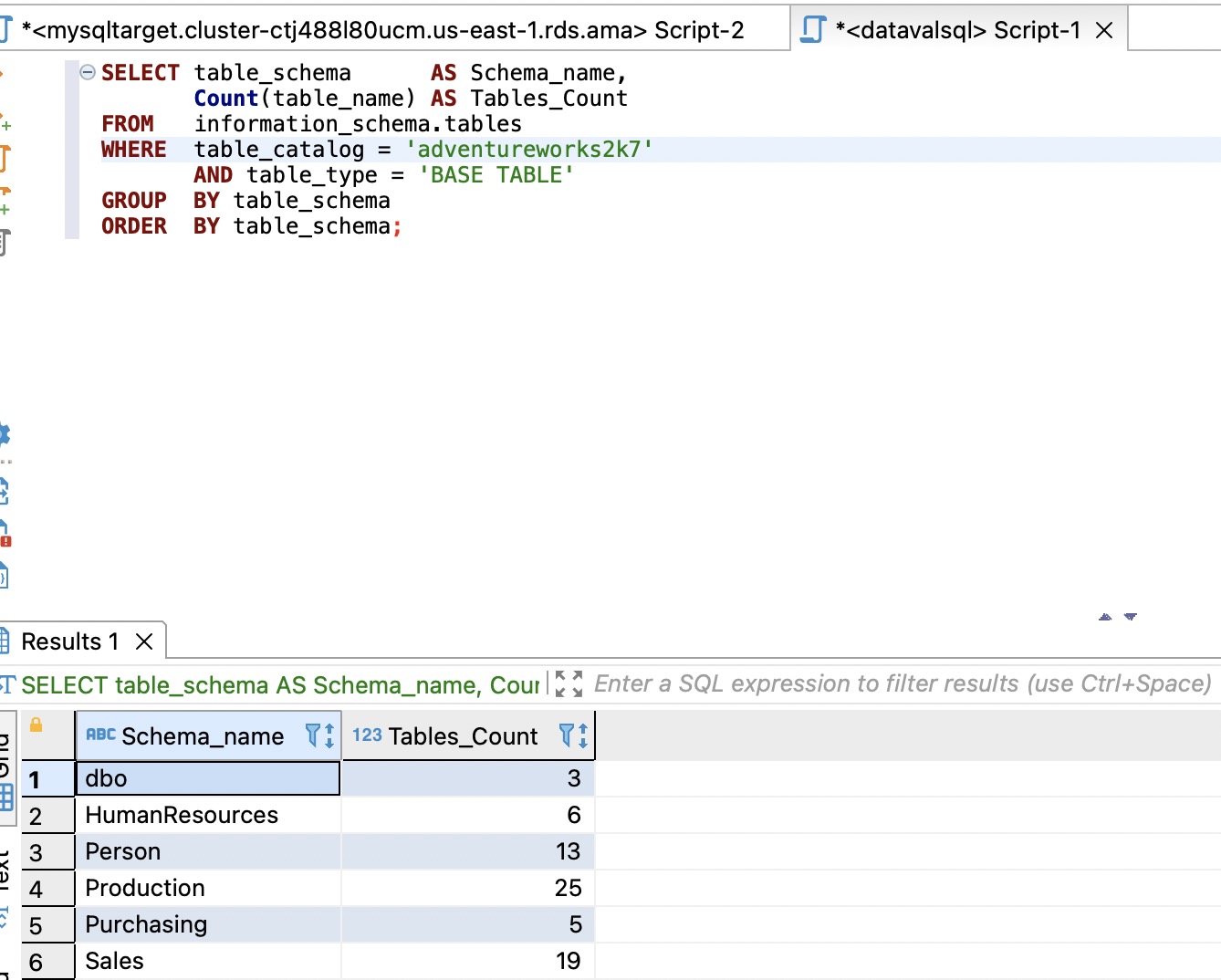
对于SQL Server,请使用以下代码:
SELECT table_schema AS Schema_name,
Count(table_name) AS Tables_Count
FROM information_schema.tables
WHERE table_catalog = 'Your Database'
AND table_type = 'BASE TABLE'
GROUP BY table_schema
ORDER BY table_schema;
以下屏幕截图显示了我们的输出。
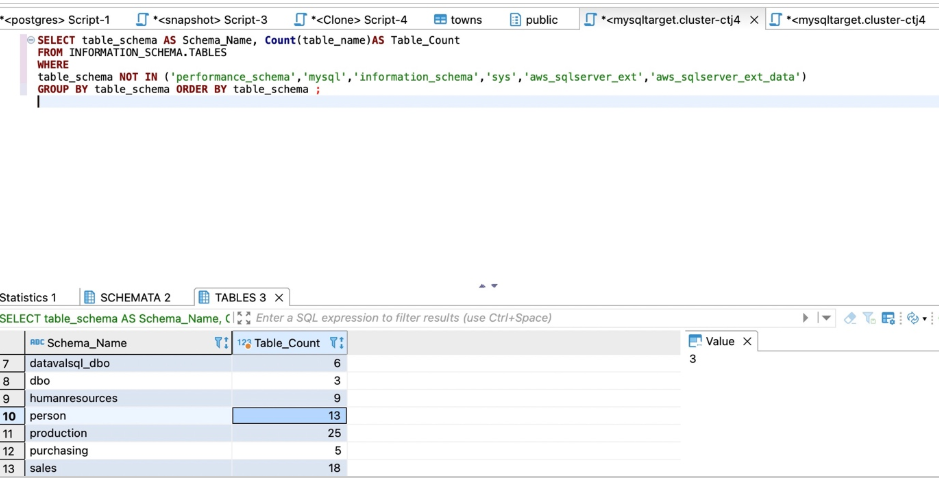
对于Amazon RDS For MySQL或Aurora MySQL,请使用以下代码进行计数:
SELECT table_schema AS Schema_Name, Count(table_name)AS Table_Count
FROM INFORMATION_SCHEMA.TABLES
WHERE table_schema
NOT IN ('performance_schema','mysql','information_schema','sys','aws_sqlserver_ext','aws_sqlserver_ext_data')
GROUP BY table_schema ORDER BY table_schema ;
以下屏幕截图显示了我们的输出。
视图
您可以通过在源数据库和目标数据库上使用以下查询来验证AWS SCT转换的视图计数。
对于SQL Server,请使用以下代码:
SELECT table_schema AS Schema_name,
Count(table_name) AS Views_Count
FROM information_schema.TABLES
WHERE table_catalog = 'Your Database'
AND table_type = 'VIEW'
GROUP BY table_schema
ORDER BY table_schema;
以下屏幕截图显示了我们的输出。
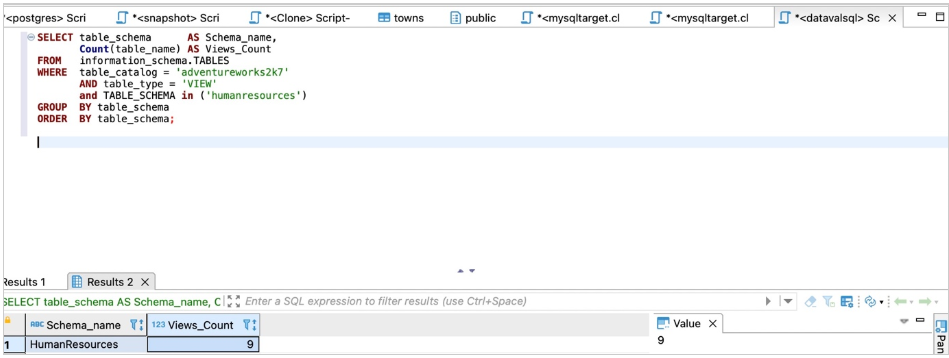
对于Amazon RDS For MySQL或Aurora MySQL,您有以下代码选项:
SELECT table_schema AS Schema_Name, Count(table_name)AS View_Count
FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE ='View'
AND table_schema NOT IN ('performance_schema', 'mysql', 'information_schema','sys','aws_sqlserver_ext','aws_sqlserver_ext_data')
GROUP BY table_schema ORDER BY table_schema;
以下屏幕截图显示了我们的输出。
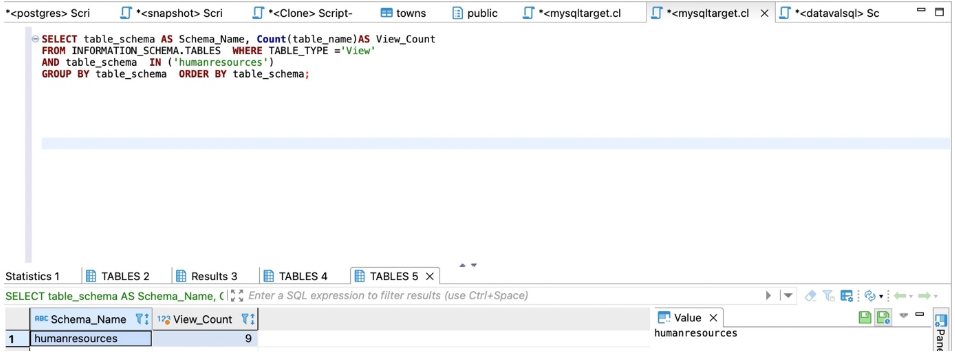
存储过程
对于SQL Server,使用以下代码进行计数:
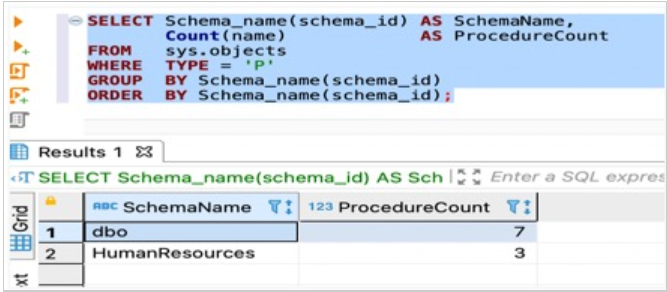
SELECT Schema_name(schema_id) AS SchemaName, Count(name) AS ProcedureCount
FROM sys.objects
WHERE TYPE = 'P'
GROUP BY Schema_name(schema_id)
ORDER BY Schema_name(schema_id);
以下屏幕截图显示了我们的输出。
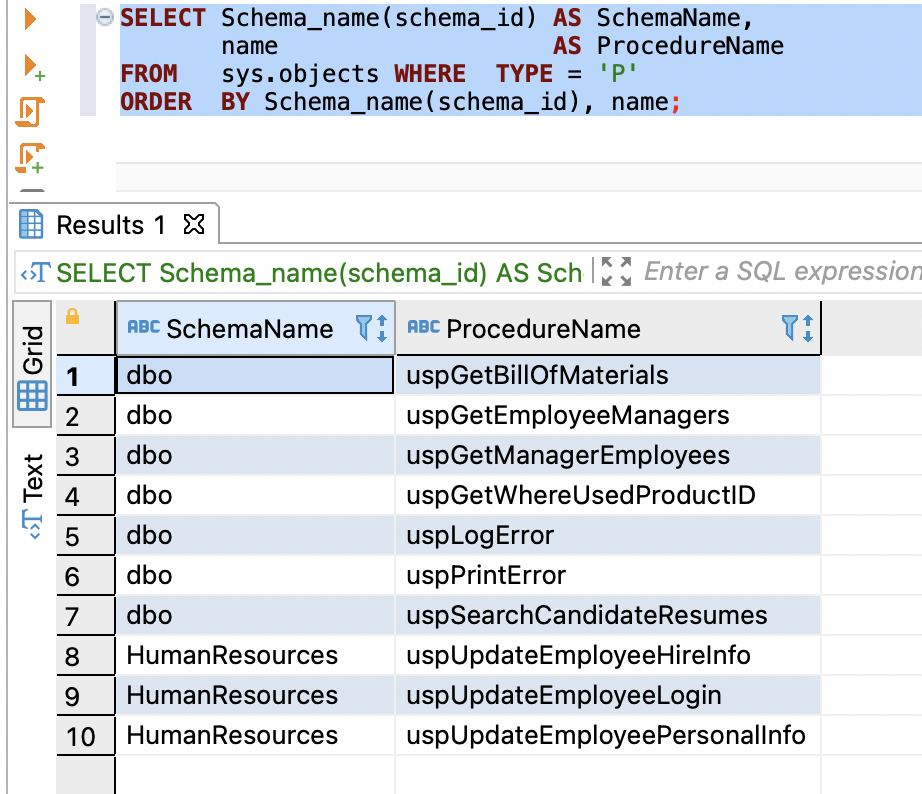
使用以下代码获取详细程度信息:
SELECT Schema_name(schema_id) AS SchemaName,
name AS ProcedureName
FROM sys.objects WHERE TYPE = 'P'
ORDER BY Schema_name(schema_id), name;
以下屏幕截图显示了我们的输出。
对于Amazon RDS For MySQL或Aurora MySQL,请使用以下代码进行计数:
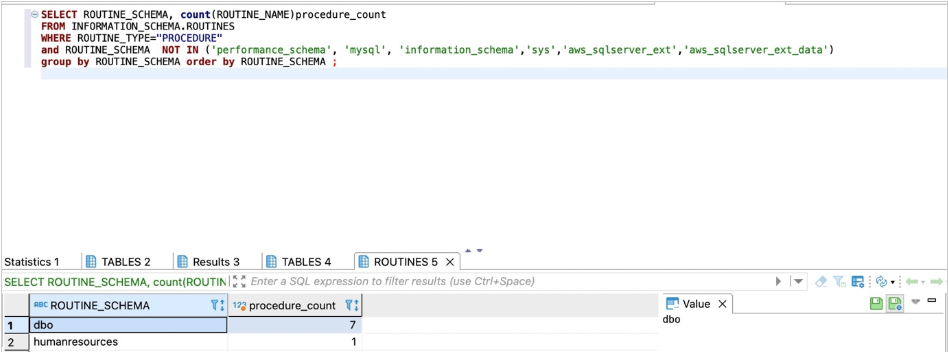
SELECT ROUTINE_SCHEMA, count(ROUTINE_NAME)procedure_count
FROM INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_TYPE="PROCEDURE"
group by ROUTINE_SCHEMA order by ROUTINE_SCHEMA;
以下屏幕截图显示了我们的输出。
使用以下查询获取详细级别信息:
SELECT ROUTINE_SCHEMA, ROUTINE_NAME as procedure_name
FROM INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_TYPE="PROCEDURE"
order by ROUTINE_SCHEMA;
以下屏幕截图显示了我们的输出。
功能
对于SQL Server,使用以下代码进行计数:
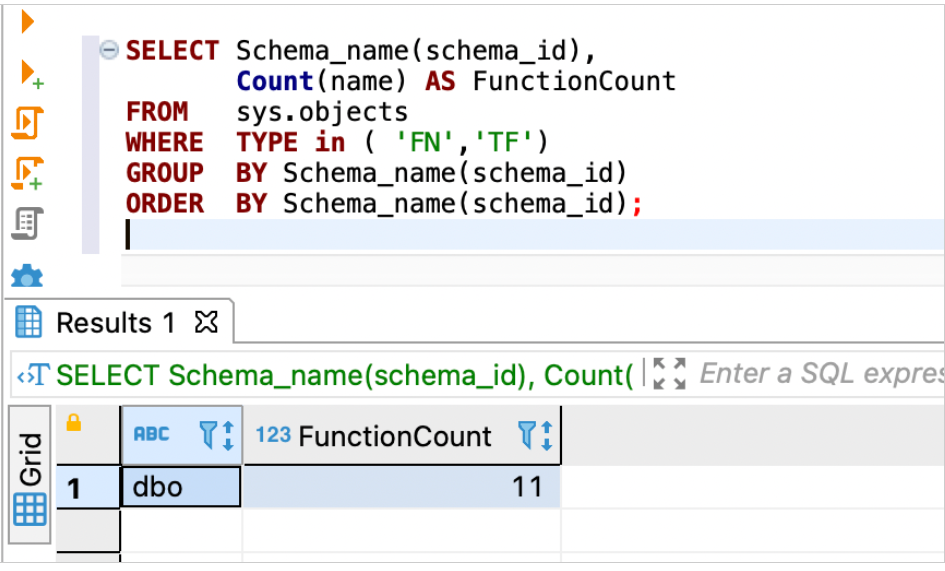
SELECT Schema_name(schema_id),
Count(name) AS FunctionCount
FROM sys.objects
WHERE TYPE in ('FN', 'TF')
GROUP BY Schema_name(schema_id)
ORDER BY Schema_name(schema_id);
以下屏幕截图显示了我们的输出。
使用以下代码获取详细程度信息:
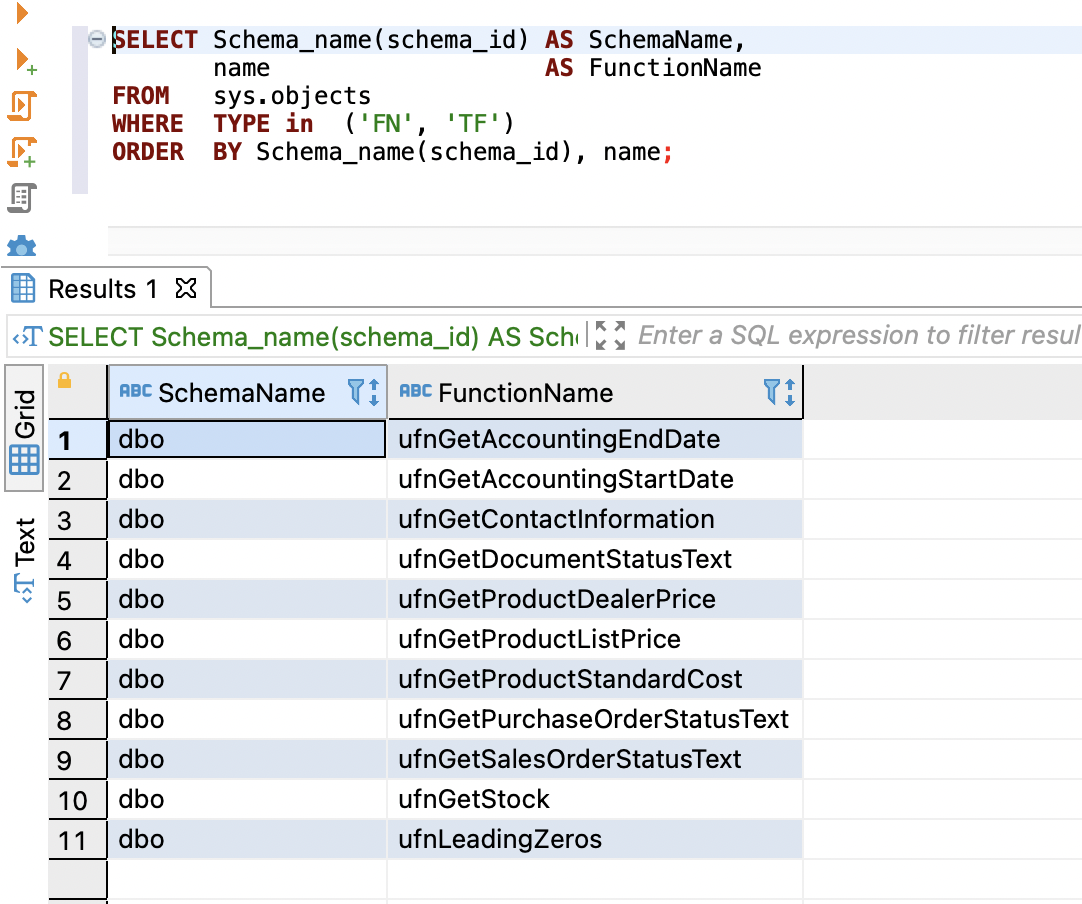
SELECT Schema_name(schema_id) AS SchemaName,
name AS FunctionName
FROM sys.objects
WHERE TYPE in ('FN', 'TF')
ORDER BY Schema_name(schema_id), name;
以下屏幕截图显示了我们的输出。
对于Amazon RDS For MySQL或Aurora MySQL,请使用以下代码进行计数:
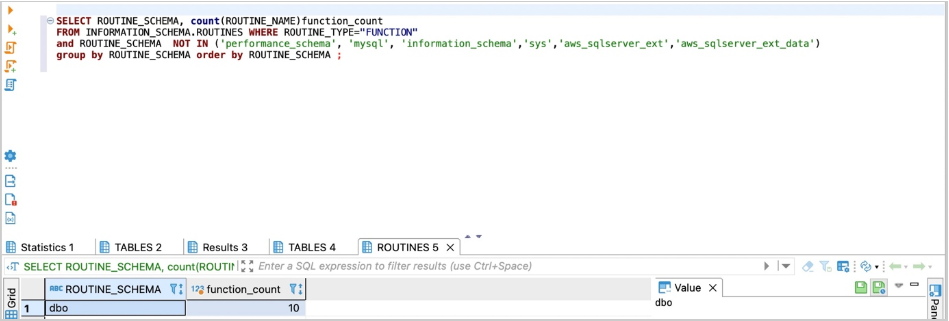
SELECT ROUTINE_SCHEMA, count(ROUTINE_NAME)function_count
FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_TYPE="FUNCTION"
group by ROUTINE_SCHEMA order by ROUTINE_SCHEMA;
以下屏幕截图显示了我们的输出。
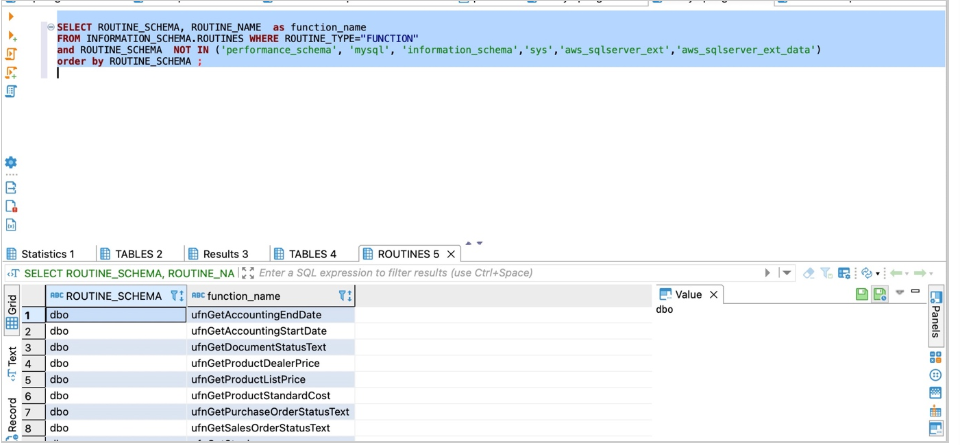
使用以下代码获取详细程度信息:
SELECT ROUTINE_SCHEMA, ROUTINE_NAME as function_name
FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_TYPE="FUNCTION"
order by ROUTINE_SCHEMA;
以下屏幕截图显示了我们的输出。
索引
索引在提高查询性能方面起着关键作用。由于优化方法因数据库而异,索引的数量及其类型因SQL Server和MySQL数据库的不同用例而异,因此索引计数也可能不同。
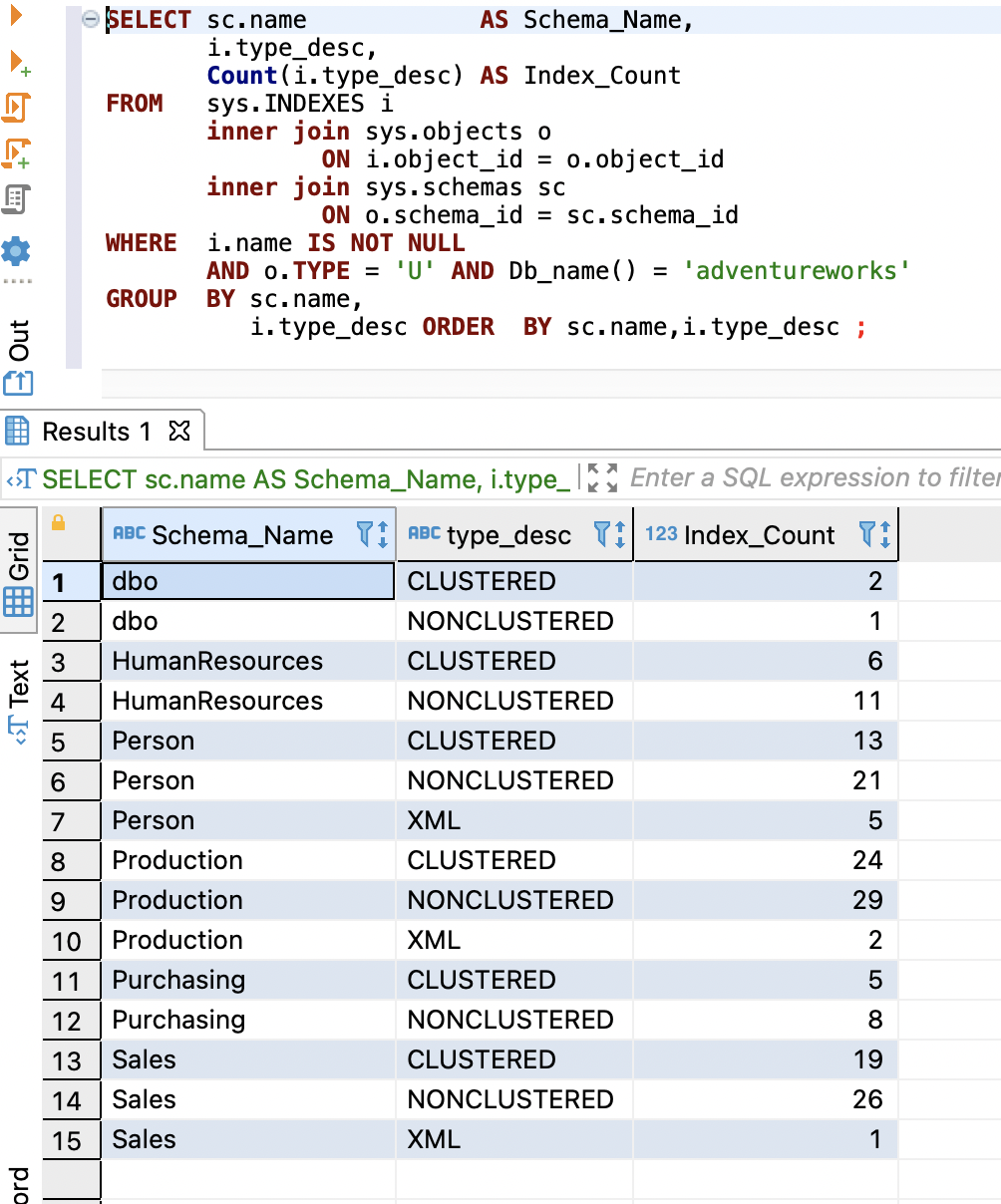
SELECT sc.name AS Schema_Name,
i.type_desc,
Count(i.type_desc) AS Index_Count
FROM sys.INDEXES i
inner join sys.objects o
ON i.object_id = o.object_id
inner join sys.schemas sc
ON o.schema_id = sc.schema_id
WHERE i.name IS NOT NULL
AND o.TYPE = 'U' AND Db_name() = 'Your Database'
GROUP BY sc.name,
i.type_desc ORDER BY sc.name,i.type_desc;
以下屏幕截图显示了我们的输出。
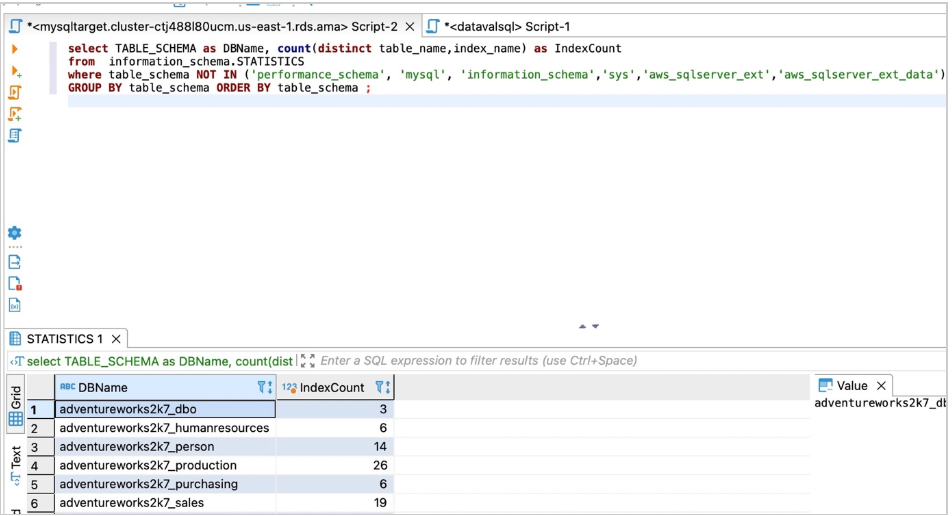
对于Amazon RDS For MySQL或Aurora MySQL,请使用以下代码进行计数:
select TABLE_SCHEMA as DBName, count(distinct table_name,index_name) as IndexCount
from information_schema.STATISTICS
where table_schema NOT IN ('performance_schema', 'mysql', 'information_schema','sys','aws_sqlserver_ext','aws_sqlserver_ext_data')
GROUP BY table_schema ORDER BY table_schema;
以下屏幕截图显示了我们的输出。
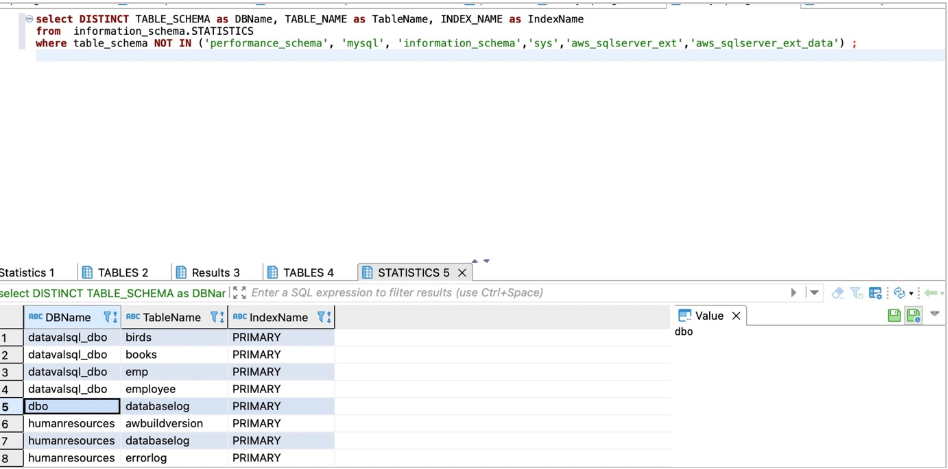
使用以下代码获取详细程度信息:
select DISTINCT TABLE_SCHEMA as DBName, TABLE_NAME as TableName, INDEX_NAME as IndexName
from information_schema.STATISTICS
where table_schema NOT IN ('performance_schema', 'mysql', 'information_schema','sys','aws_sqlserver_ext','aws_sqlserver_ext_data') ;
以下屏幕截图显示了我们的输出。
触发器
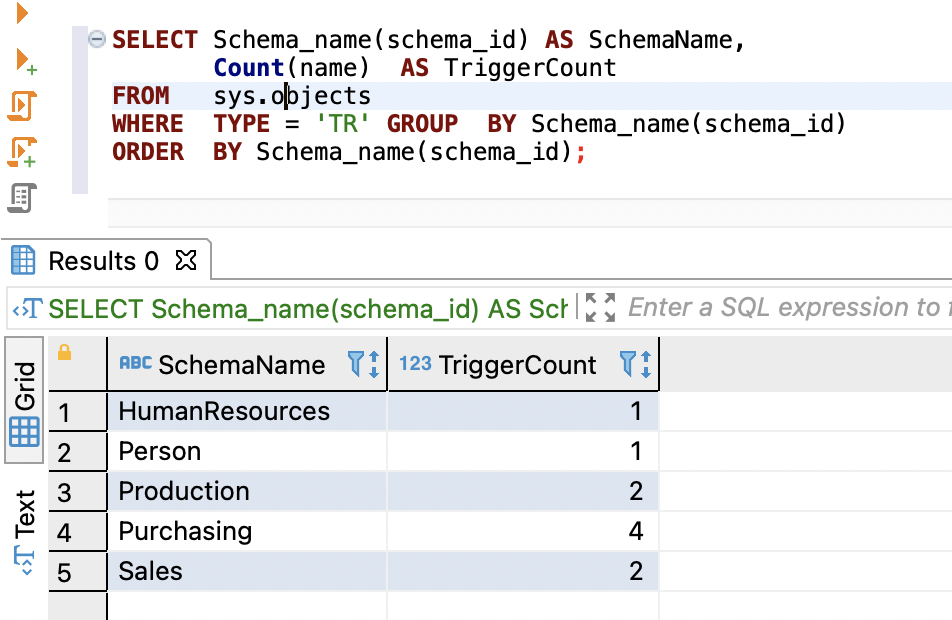
触发器可帮助您审核数据库中的DML或DDL更改。它们还可以根据适当区域的使用情况影响性能。以下查询为您提供源数据库和目标数据库的触发器计数和详细信息。
SELECT Schema_name(schema_id) AS SchemaName,
Count(name) AS TriggerCount
FROM sys.objects
WHERE TYPE = 'TR' GROUP BY Schema_name(schema_id)
ORDER BY Schema_name(schema_id);
以下屏幕截图显示了我们的输出。
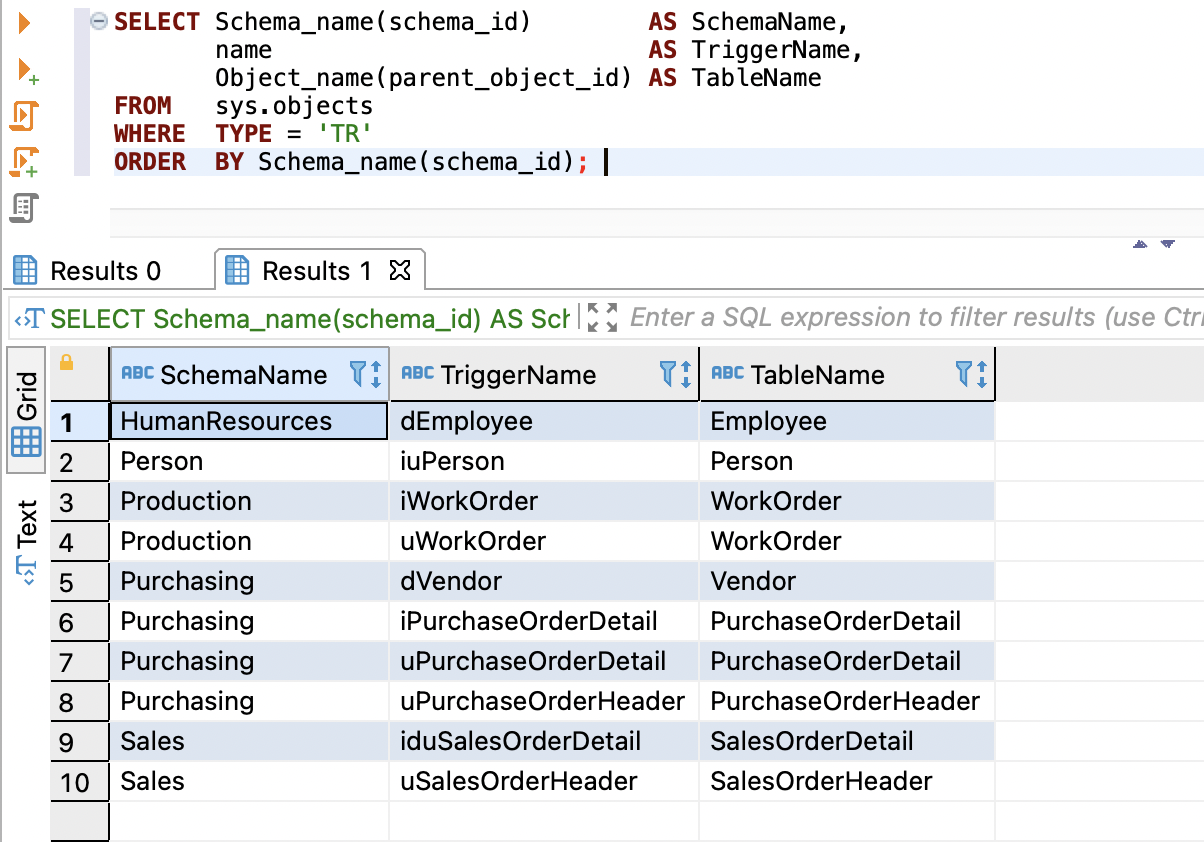
使用以下代码获取详细程度信息:
SELECT Schema_name(schema_id) AS SchemaName,
name AS TriggerName,
Object_name(parent_object_id) AS TableName
FROM sys.objects
WHERE TYPE = 'TR'
ORDER BY Schema_name(schema_id);
以下屏幕截图显示了我们的输出。
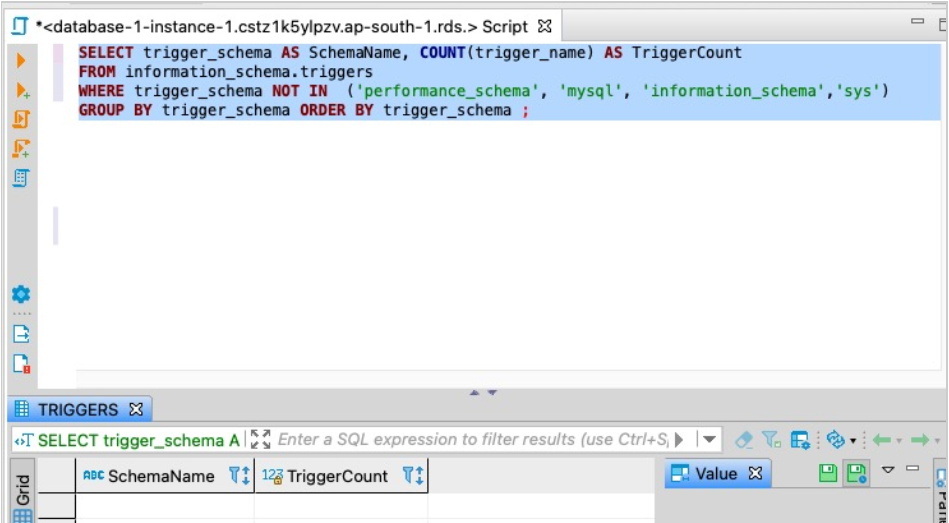
对于Amazon RDS For MySQL或Aurora MySQL,请使用以下代码进行计数:
SELECT trigger_schema AS SchemaName, COUNT(trigger_name) AS TriggerCount
FROM information_schema.triggers
WHERE trigger_schema NOT IN ('performance_schema', 'mysql', 'information_schema','sys','aws_sqlserver_ext','aws_sqlserver_ext_data')
GROUP BY trigger_schema ORDER BY trigger_schema;
以下屏幕截图显示了我们的输出。
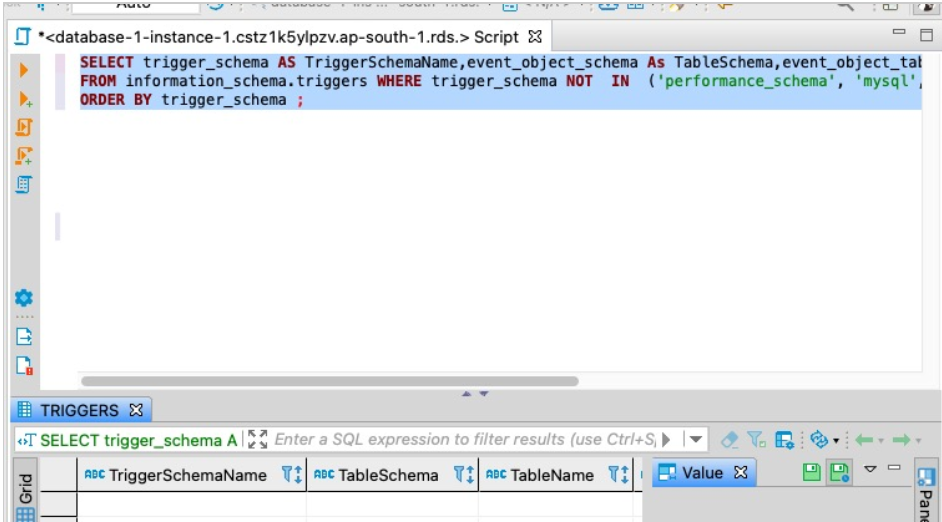
使用以下代码获取详细程度信息:
SELECT trigger_schema AS TriggerSchemaName,event_object_schema As TableSchema,event_object_table As TableName , trigger_name ,event_manipulation AS TriggerType
FROM information_schema.triggers
WHERE trigger_schema NOT IN ('performance_schema', 'mysql', 'information_schema','sys','aws_sqlserver_ext','aws_sqlserver_ext_data')
ORDER BY trigger_schema;
以下屏幕截图显示了我们的输出。
在使用AWS数据库迁移服务(AWS DMS)执行迁移之前,应关闭这些密钥。
制约因素
除了数据库对象验证之外,还需要确保数据的一致性和完整性。不同类型的约束为您提供了在插入期间控制和检查数据的灵活性,以避免运行时数据完整性问题。
主键
主键允许列具有唯一的值,这样可以防止在规范化过程之后信息重复。
此键有助于改进基于键值的搜索,并避免表扫描。
以下查询可帮助您提取源数据库和目标数据库中主键的计数和详细信息。
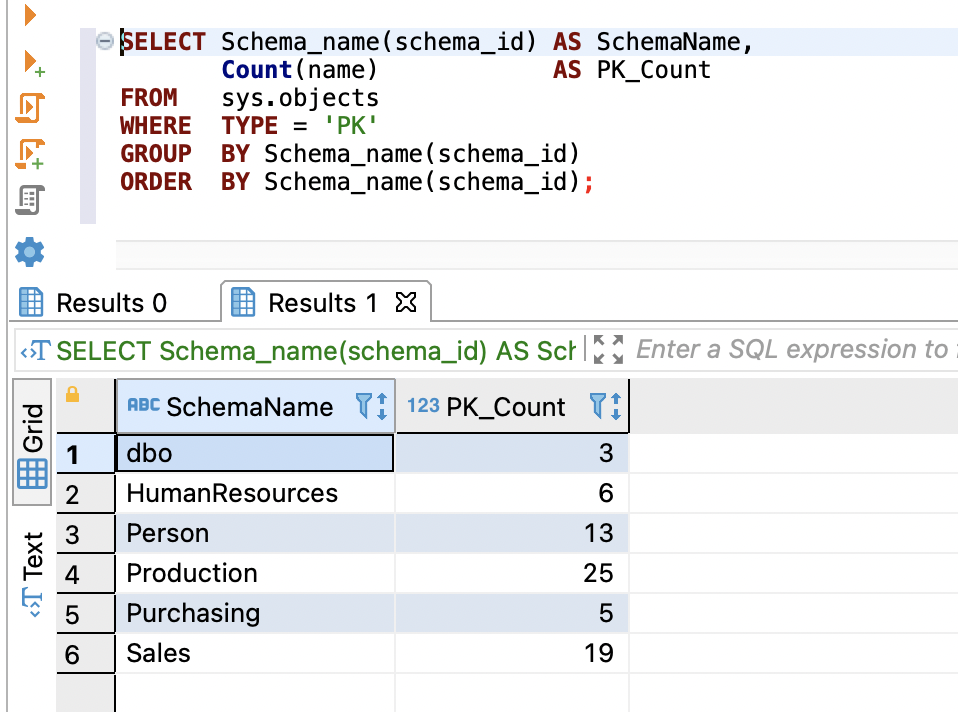
对于SQL Server,使用以下代码进行计数:
SELECT Schema_name(schema_id) AS SchemaName,
Count(name) AS PK_Count
FROM sys.objects
WHERE TYPE = 'PK'
GROUP BY Schema_name(schema_id)
ORDER BY Schema_name(schema_id);
以下屏幕截图显示了我们的输出。
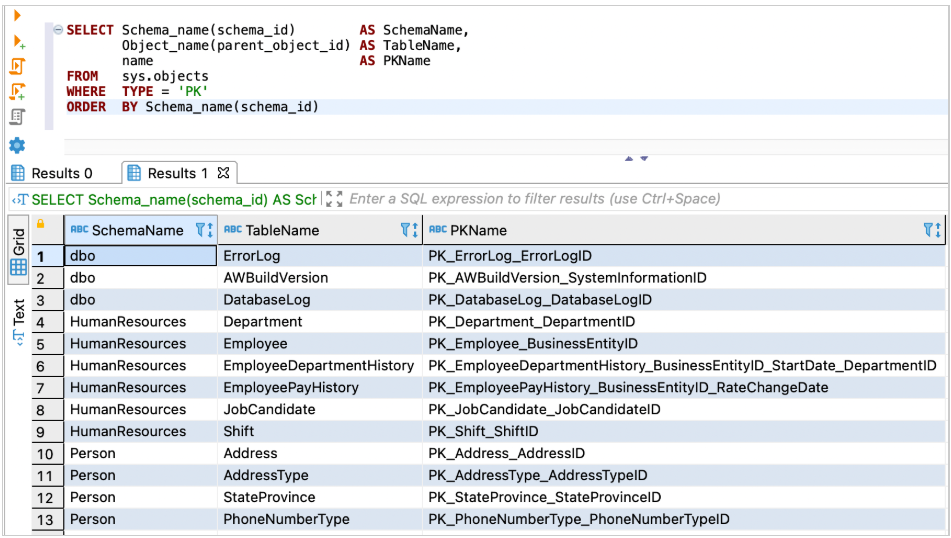
使用以下代码获取详细程度信息:
SELECT Schema_name(schema_id) AS SchemaName,
Object_name(parent_object_id) AS TableName,
name AS PKName
FROM sys.objects
WHERE TYPE = 'PK'
ORDER BY Schema_name(schema_id);
以下屏幕截图显示了我们的输出。
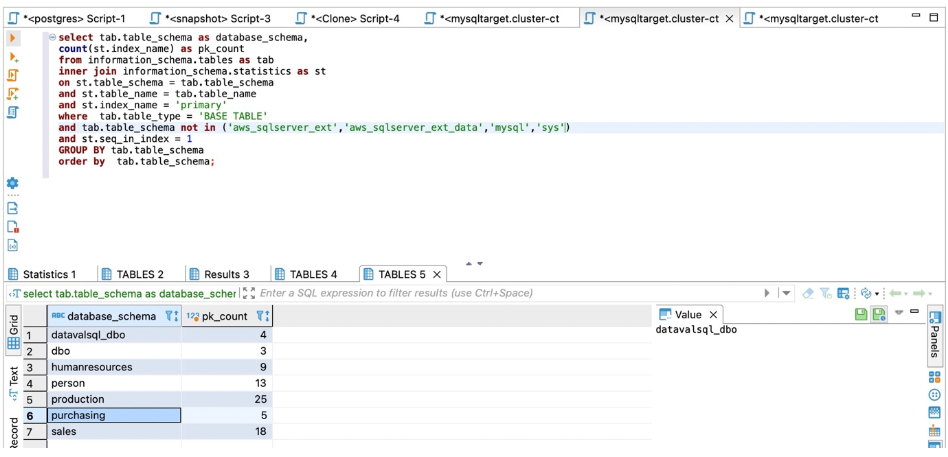
对于Amazon RDS For MySQL或Aurora MySQL,请使用以下代码进行计数:
select tab.table_schema as database_schema,
count(st.index_name) as pk_count
from information_schema.tables as tab
inner join information_schema.statistics as st
on st.table_schema = tab.table_schema
and st.table_name = tab.table_name
and st.index_name = 'primary'
where tab.table_type = 'BASE TABLE'
and st.seq_in_index = 1
GROUP BY tab.table_schema
order by tab.table_schema;
以下屏幕截图显示了我们的输出。
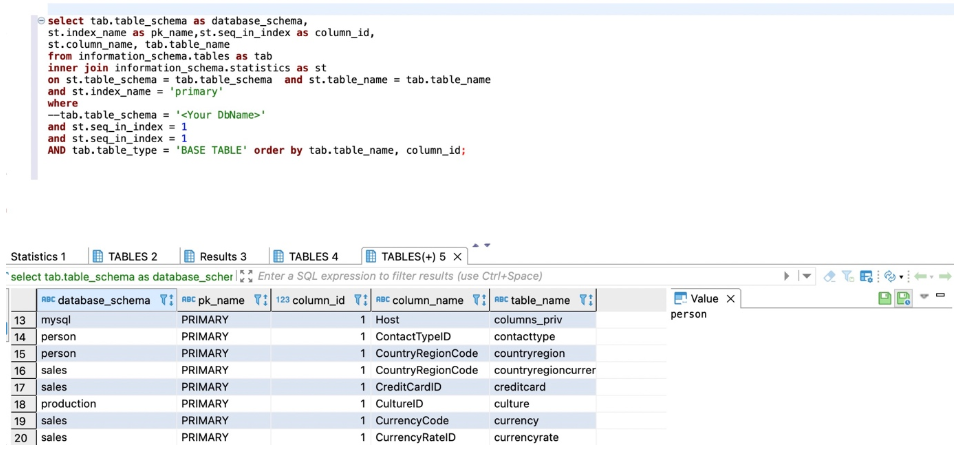
使用以下内容获取详细程度信息:
select tab.table_schema as database_schema,
st.index_name as pk_name,st.seq_in_index as column_id,
st.column_name, tab.table_name
from information_schema.tables as tab
inner join information_schema.statistics as st
on st.table_schema = tab.table_schema and st.table_name = tab.table_name
and st.index_name = 'primary'
where tab.table_schema = '<Your DbName>'
and st.seq_in_index = 1
and st.seq_in_index = 1
tab.table_type = 'BASE TABLE' order by tab.table_name, column_id;
以下屏幕截图显示了我们的输出。
外键
外键有助于识别表之间的关系,可以使用外键形成数据库规范化表单,将相关数据存储在适当的表中。在使用AWS DMS执行迁移之前,应关闭这些密钥。
通过以下查询,您可以获得源数据库和目标数据库中外键的计数和详细级别信息。
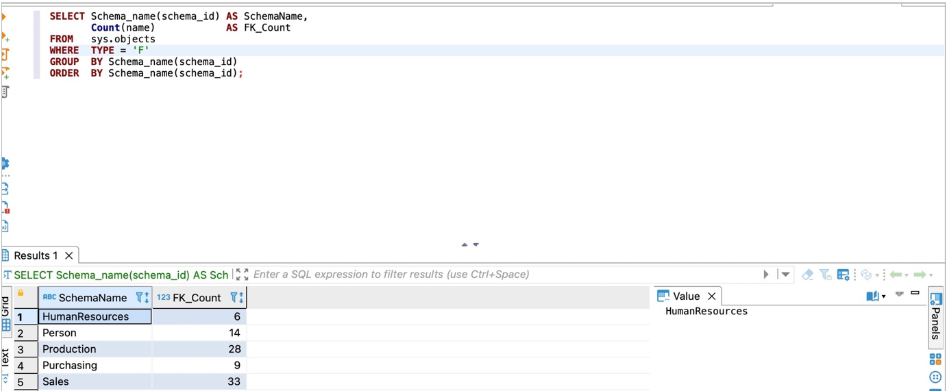
对于SQL Server,使用以下代码进行计数:
SELECT Schema_name(schema_id) AS SchemaName,
Count(name) AS FK_Count
FROM sys.objects
WHERE TYPE = 'F'
GROUP BY Schema_name(schema_id)
ORDER BY Schema_name(schema_id);
以下屏幕截图显示了我们的输出。
使用以下代码获取详细程度信息:
SELECT Schema_name(schema_id) AS SchemaName,
Object_name(parent_object_id) AS TableName,
name AS FKName
FROM sys.objects
WHERE TYPE = 'F'
ORDER BY Schema_name(schema_id);
以下屏幕截图显示了我们的输出。
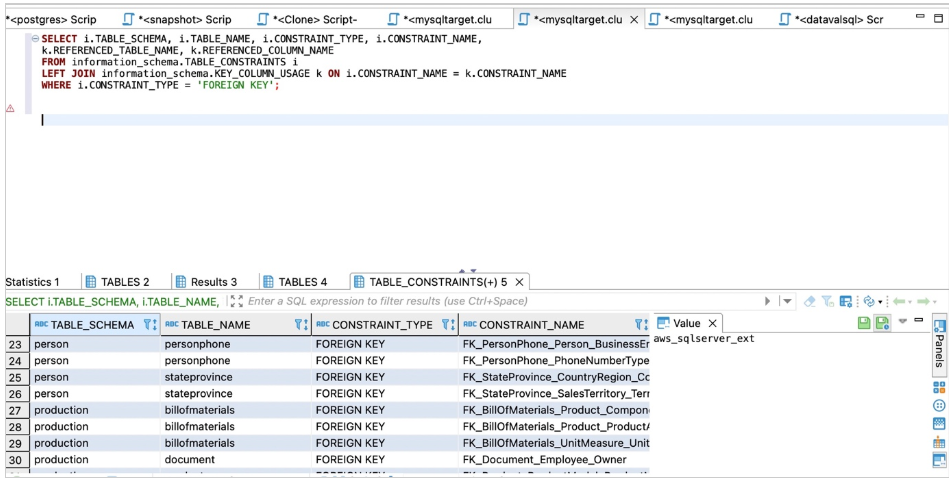
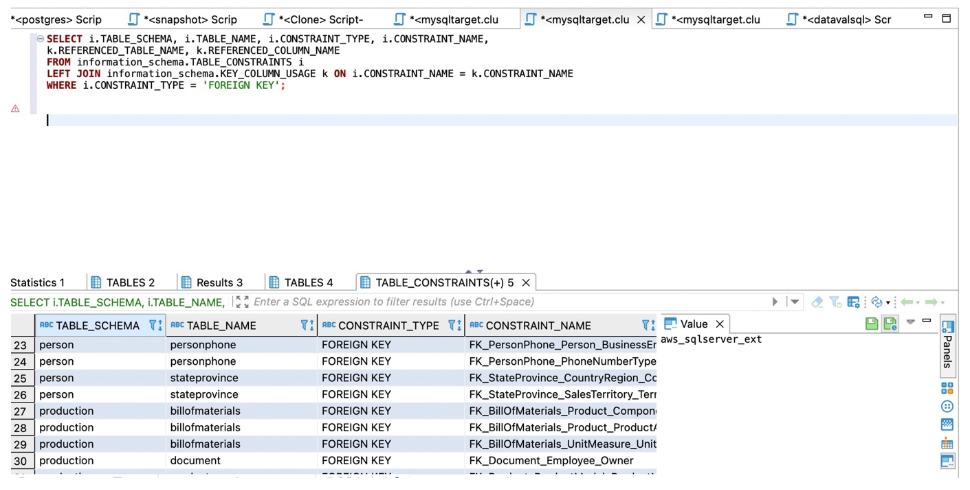
对于Amazon RDS For MySQL或Aurora MySQL,请使用以下代码进行计数:
SELECT i.TABLE_SCHEMA, i.TABLE_NAME, i.CONSTRAINT_TYPE, i.CONSTRAINT_NAME,
k.REFERENCED_TABLE_NAME, k.REFERENCED_COLUMN_NAME
FROM information_schema.TABLE_CONSTRAINTS i
LEFT JOIN information_schema.KEY_COLUMN_USAGE k ON i.CONSTRAINT_NAME = k.CONSTRAINT_NAME
WHERE i.CONSTRAINT_TYPE = 'FOREIGN KEY';
以下屏幕截图显示了我们的输出。
唯一键
使用唯一键可以限制列中数据的唯一性,并防止重复值。您可以使用此键来避免数据冗余,这间接有助于适当的数据存储和检索。通过以下查询,您可以获得有关源数据库和目标数据库中唯一键的计数和详细级别信息。
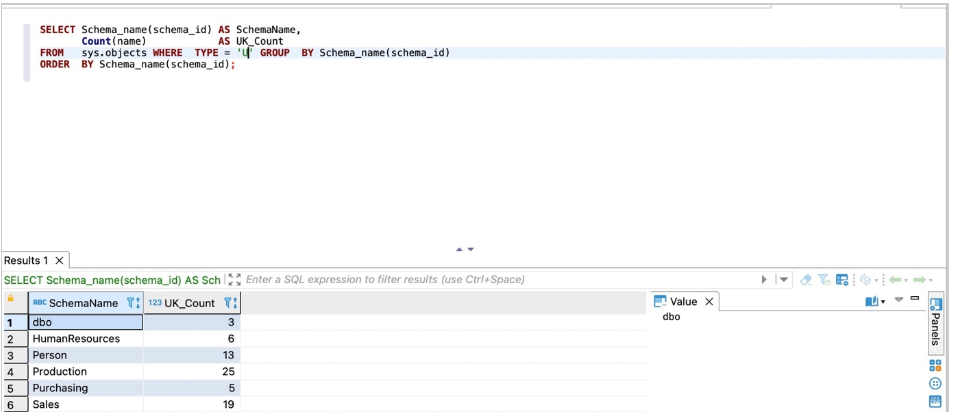
对于SQL Server,使用以下代码进行计数:
SELECT Schema_name(schema_id) AS SchemaName,
Count(name) AS UK_Count
FROM sys.objects WHERE TYPE = 'U' GROUP BY Schema_name(schema_id)
ORDER BY Schema_name(schema_id);
以下屏幕截图显示了我们的输出。
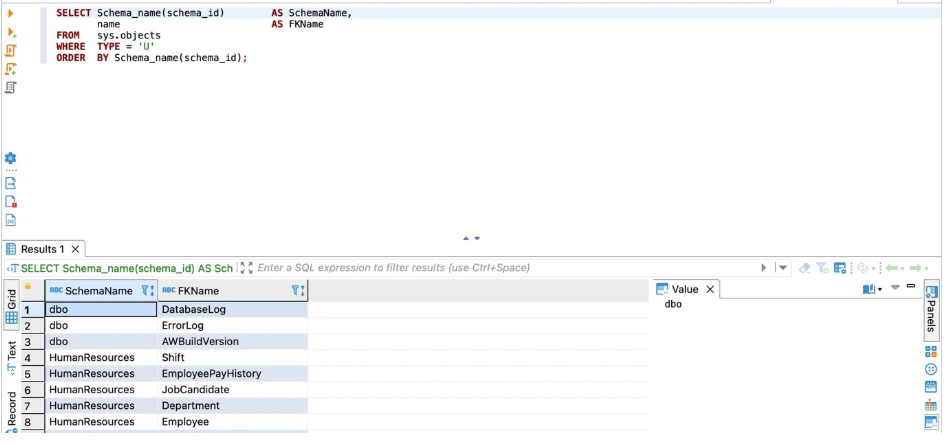
使用以下代码获取详细程度信息:
SELECT Schema_name(schema_id) AS SchemaName,
Object_name(parent_object_id) AS TableName,
name AS UK_Name
FROM sys.objects
WHERE TYPE = 'U'
ORDER BY Schema_name(schema_id);
以下屏幕截图显示了我们的输出。
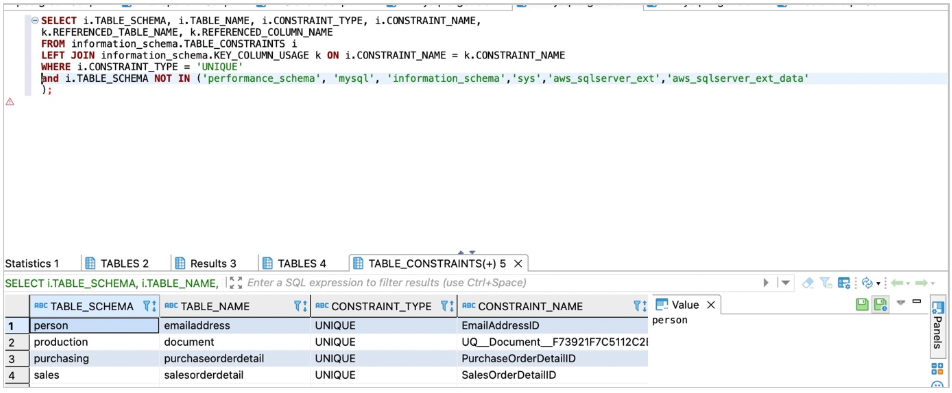
对于Amazon RDS For MySQL或Aurora MySQL,请使用以下代码进行计数:
SELECT i.TABLE_SCHEMA, i.TABLE_NAME, i.CONSTRAINT_TYPE, i.CONSTRAINT_NAME,
k.REFERENCED_TABLE_NAME, k.REFERENCED_COLUMN_NAME
FROM information_schema.TABLE_CONSTRAINTS i
LEFT JOIN information_schema.KEY_COLUMN_USAGE k ON i.CONSTRAINT_NAME = k.CONSTRAINT_NAME
WHERE i.CONSTRAINT_TYPE = 'UNIQUE' and i.TABLE_SCHEMA NOT IN ('performance_schema', 'mysql', 'information_schema','sys','aws_sqlserver_ext','aws_sqlserver_ext_data');
以下屏幕截图显示了我们的输出。
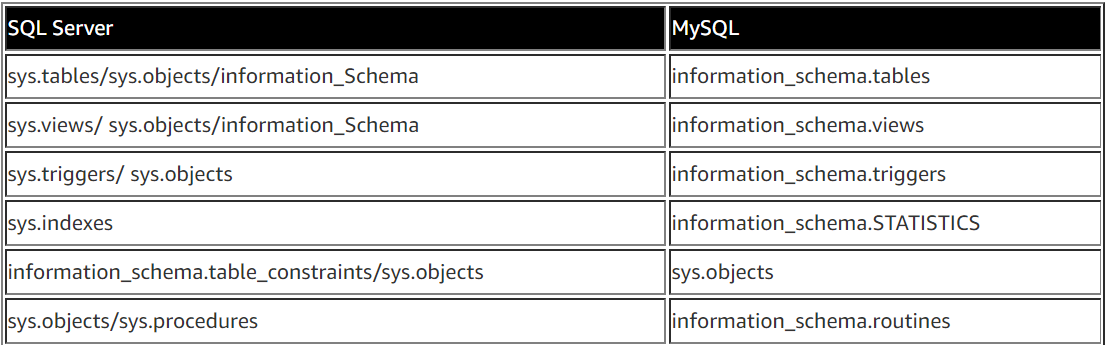
有用的MySQL目录表
下表总结了一些对数据库对象验证有用的SQL Server和MySQL系统表和视图。这些表和视图包含有关各种数据库对象及其详细信息的元数据,您可以使用这些元数据进行验证。
识别并修复丢失的对象
正如您所看到的,SQL Server和MySQL之间的一些查询输出不匹配,因为AWS SCT不能转换所有内容。本文中的查询可以帮助您在从源数据库迁移到目标数据库的过程中识别丢失的数据库对象。可以使用查询结果执行比较,以确定数据库对象中的间隙。这缩小了对迁移中丢失对象的关注范围。在修复丢失的对象之后,可以反复使用查询,直到达到所需的状态。
结论
验证数据库对象对于提供数据库迁移准确性和确认所有对象都已正确迁移至关重要。验证所有数据库对象有助于确保目标数据库的完整性,从而允许应用程序像在源数据库上一样无缝运行。
在本文中,我们讨论了数据库对象的迁移后验证。随着数据库从SQL Server迁移到Amazon RDS for MySQL或Aurora MySQL,我们澄清了验证过程的重要性和验证的数据库对象类型,提高了迁移数据库的可信度。如果出现错误,此解决方案还可以帮助您识别错误,并在迁移后帮助您识别丢失或不匹配的对象。
如果你对这篇文章有任何疑问或建议,请留言。
关于作者

Shyam Sunder Rakhecha是位于印度Hyderabad的AWS专业服务团队的数据库顾问,擅长数据库迁移。他正在AWS云中帮助客户迁移和优化。他很想探索数据库方面的新兴技术。他对RDBMS和大数据着迷。他还喜欢组织团队建设活动和团队盛宴。

Pradeepa Kesiraju是位于印度Hyderabad的AWS专业服务团队的高级业务经理。她擅长管理大规模数据库迁移到AWS云。她利用自己在数据库技术方面的丰富经验,主动识别潜在风险和问题。她努力使自己跟上新的数据库技术,并使其与客户的业务成果保持一致。

Sai Krishna Namburu是位于印度Hyderabad的AWS专业服务公司的数据库顾问。凭借在关系数据库方面的良好知识,以及在同质和异构数据库迁移方面的实践经验,他帮助客户迁移到AWS云及其优化。对数据库和过程自动化领域的新技术充满热情。对开源技术、数据分析和ML感兴趣,因为它们可以提高客户的结果。
原文标题:Validate database objects post-migration from Microsoft SQL Server to Amazon RDS for MySQL and Amazon Aurora MySQL
原文作者:Shyam Sunder Rakhecha, Pradeepa Kesiraju, and Sai Krishna Namburu
原文链接:https://aws.amazon.com/cn/blogs/database/validate-database-objects-post-migration-from-microsoft-sql-server-to-amazon-rds-for-mysql-and-amazon-aurora-mysql/
