




向量数据库检索,衡量不同向量数据库的受欢迎程度。
By Ben Lorica and Leo Meyerovich
介绍
越来越多的技术团队关注向量数据库和向量搜索。一个关键驱动因素是神经网络的进步使数据的密集向量表示更加普遍。由于科技公司决定开源其向量搜索核心系统(Yahoo Vespa、Facebook Faiss),兴趣也有所增长。此外,一些向量数据库初创公司已经筹集了近 2 亿美元的资金,从而催生了新的企业解决方案提供商和支持者。
虽然向量数据库用于推荐、异常检测和问答系统,但它们主要针对搜索和信息检索应用程序。向量数据库是专门为处理向量_嵌入_而设计的。向量嵌入的一个示例是从高分辨率 3D 模型生成的低分辨率图片。嵌入是可以将高维向量映射到的低维空间。嵌入可以表示多种数据,无论是文本句子、音频片段还是记录的事件。关键是嵌入捕获了输入的一些语义,并将语义相似的输入放在嵌入空间中。结果是,通过使用嵌入,人工智能应用程序可以更快、更便宜地运行,而不会降低质量。

图 1:流行向量数据库的代表性样本。请注意,基于它们的标语,许多系统突出了可扩展性和目标搜索应用程序。
一般原语是识别最近邻(“向量搜索”)。由于嵌入捕获了底层语义,它们为支持搜索应用程序的管道提供了很好的构建块。向量搜索的一些知名用户包括Facebook(相似性搜索)、Clubhouse(语义搜索)、电子商务网站(eBay、腾讯、沃尔玛、宜家)以及Google和Bing等搜索引擎。

图 2:语义和神经搜索管道,来自“语义搜索和神经信息检索”。
随着对嵌入的兴趣日益浓厚,人们越来越关注缩放和加速向量搜索技术,如KNN、ANN和HNSW,以及对硬件加速等相关工具的投资。下图显示了提及“相似性搜索”或“语义搜索”的研究论文数量的增长:
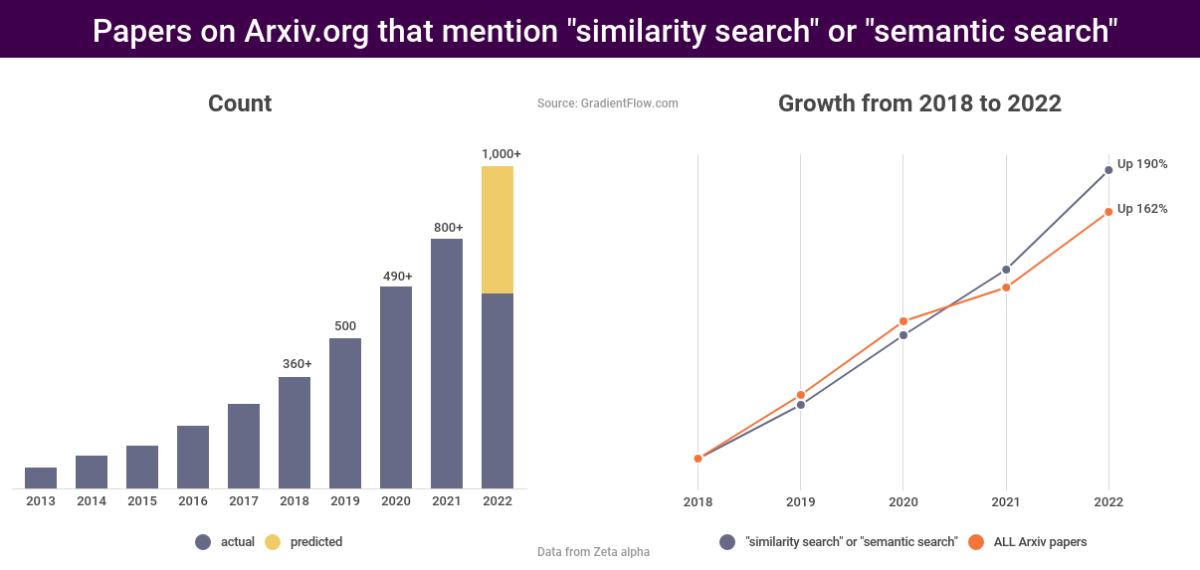
图 3:研究人员正在发表更多关于“相似性搜索”和“语义搜索”的论文。
向量数据库检索
这篇文章的目的是使用衡量_流行度_的检索来比较向量数据库。对于这个创始版本,我们专注于专门的系统,并且只包括一个通用检索引擎——Elasticsearch,它通过Apache Lucene 的新 ANN 功能整合了向量搜索。与我们之前关于实验跟踪和管理工具的文章一样,我们使用了一个依赖于公共数据并以TIOBE 的编程语言检索为模型的检索。我们的指数由以下部分组成:
- 检索:我们使用了 TIOBE 列表(谷歌、维基百科、亚马逊)中的一个子集,并将 Reddit、Twitter 和 Stack Overflow 添加到组合中。
- (人才)供应:此部分基于在其 LinkedIn 个人资料中将特定向量数据库列为技能的人数。
- 需求(人才):我们检查了来自Linkedin 和Indeed 的提及特定向量数据库的美国职位发布数量。
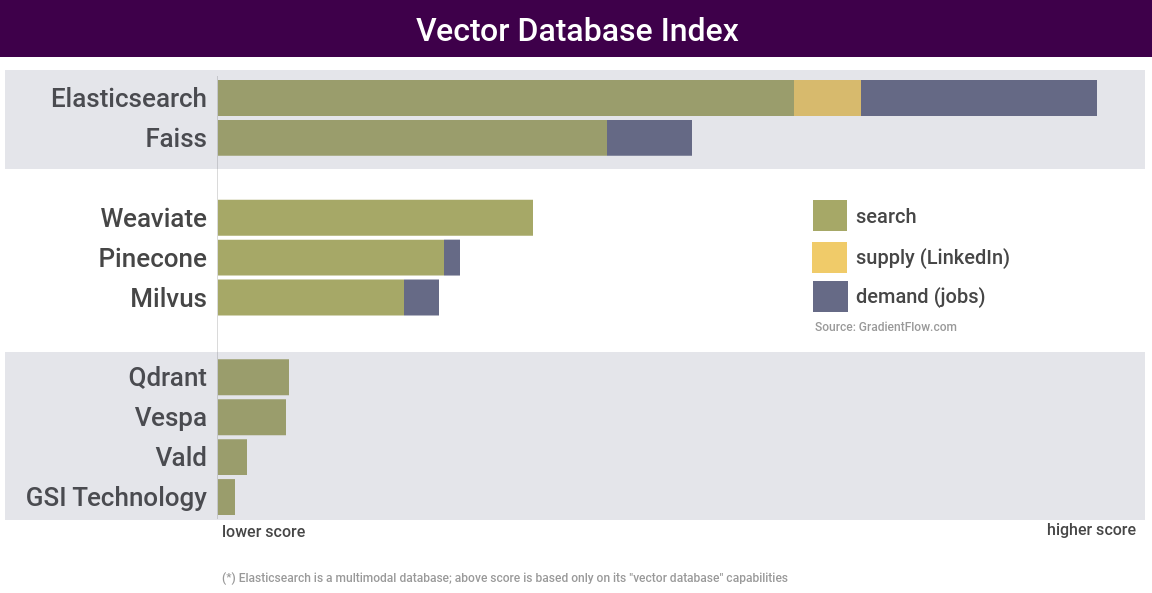
图 4:向量数据库检索——下一代搜索应用程序数据管理工具受欢迎程度的指标。
_搜索_是总分背后的驱动力。向量数据库仍然非常专业和先进,因此_人才需求和供应方面的_数据仍然非常稀少。由于人才数据(供需)的稀疏性,我们将我们的指数分成几层,因为这个新类别的排名仍然不稳定。例如,基于我们检索的最受欢迎的工具是 Elasticsearch 和Faiss,这是一个主要由 Facebook AI Research 开发的开源项目。技术团队在讨论向量数据库时经常引用 Faiss。在我们的人气排名第二梯队中有 3 家资金雄厚的初创公司:Weaviate、Pinecone、Milvus。
从这些工具的创建者提供的描述中可以看出(参见图 1),这些系统专注于可扩展性。向量数据库传统上为每台服务器检索几百万个向量(例如,参见Pinecone、Faiss、Weaviate)。散列和分片等技术有助于扩展到更大的数据集,但这可能非常昂贵。最近,一些系统一直在强调它们以经济高效的方式扩展到十亿个向量的能力,例如通过针对 SSD 存储优化的检索(参见Vespa、Milvus)或通过利用硬件加速来支持大于内存的数据集。见GSI 技术)。我们预计在不久的将来会有更多系统效仿。
结束观察
- 嵌入是现代 AI 的通用语——贵组织的 AI 嵌入战略是什么? 如果您的组织正在使用神经网络,那么您很可能有嵌入。从某种意义上说,向量数据库是关于嵌入整个数据库时所获得的。因此,向量数据库是一系列数据库管理架构,用于将 AI 引入您的数据管理系统。随着组织在其关键数据上利用 AI 的方式不断发展,该过程包括确定管理数据嵌入的正确方法,例如在计算层 (Faiss) 或数据库内部。
- 大规模管理嵌入的其他方面值得考虑。(1)支持流式传输,例如连续数据摄取的高吞吐量、连续模型更新和高每秒查询数;(2)向_量化_和更广泛的_特征工程_过程(将原始数据转化为高质量的嵌入)是计算密集型的,通常需要像Ray这样的计算框架;(3)_版本控制_能力是新功能商店擅长的领域。
当您嵌入整个数据库时,您会得到向量数据库
- 向量搜索和向量数据库并不是用于非结构化数据的唯一新系统。其他初创公司正在构建工具来解决阻碍构建和扩展特定_BI、分析或机器学习_应用程序的质量、性能和管理问题。一些示例包括以数据标记为目标的数据管理系统,以及以可快速流式传输以训练深度学习模型的格式存储数据的数据管理系统。同样,知识图数据库正在添加原生向量功能,图数据库供应商建议将关联表示为关联节点或关联边,以便重用其更具可扩展性和成熟的功能。
- 从长远来看,专门的数据库甚至向量硬件是否有意义?正如我们在上面提到的,像 Elasticsearch 这样的现代多模式数据库已经增加了向量搜索功能。然而,专业系统的出现表明,人工智能团队的需求超出了一般搜索引擎和数据库目前所能提供的范围。从长远来看,独立向量数据库会成为大多数 AI 团队选择添加的组件吗?或者大多数人只会在 Elasticsearch、数据仓库 (BigQuery) 和Lakehouses等系统中使用优化的向量检索,尤其是考虑到底层(开源)引擎正在由资金充足的大型 AI 组织使用和维护。即使 AI 团队采用通用数据库,计算层解决方案是否会更好地服务于剩余的利基用例,如果是这样,这对不断增长的风险投资的向量数据库生态系统意味着什么?答案主要取决于现有系统提高其向量搜索能力的速度和效果。
Ben Lorica是 Gradient Flow 的负责人。他是Graphistry 和其他初创公司的顾问。
Leo Meyerovich是第一个图形 AI 视觉平台Graphistry的创始人兼首席执行官。向量搜索是 Graphistry 如何帮助安全、欺诈、社交、供应链和其他数据密集型团队将图神经网络和流形学习转化为洞察力和行动的一部分。
原文标题:The Vector Database Index
原文作者:Ben Lorica 、 Leo Meyerovich
原文链接:https://gradientflow.com/the-vector-database-index/
