




3. 第三章 PCTP考试学习笔记之三:TiDB 数据库的事务设计
3.1. 分布式事务基本原理
3.1.1. 事务定义
“百度百科”对数据库事务(Transaction)的定义为“数据库事务是访问并可能操作各种数据项的 一个数据库操作序列,这些操作要么全执行,要么全不执行,是一个不可分割的工作单位”。事务具有 ACID 四大特性,这四大特性为:
-
原子性(Atomicity):事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失 败。例如,在同一个事务中的 SQL 语句,要么全部执行成功,要么全部执行失败。
-
一致性(Consistency):事务的前后,数据库中的数据的状态要确保一致。例如,张三向李四转 100 元,转账前和转账后,两人账号总和不变,这就叫一致性。如果出现张三转出 100 元,李四账号没 有增加 100 元,这就出现了数据错误(二者总和发生变化),就没有达到一致性。
-
隔离性(Isolation):事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事 务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。例如,张三账号余额 200 元,在 session1 中张三给李四转账 100 元。如果 session1 中的事务没有提交,那么在另外一个 session2 中 并不能查看 session1 中未提交的数据,即 session2 中看到的张三账户余额仍然为 200 元。
-
持久性(Durability):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的, 接下来即使数据库发生故障也不应该对其有任何影响。例如,张三向李四转转 100 元的事务提交成功, 则张三的账户永久性地减少了 100 元,而李四的账号永久地增加了 100 元。
3.1.2. 隔离级别
ISO 定义了四种标准隔离级别:
-
可串行化/串行读(SERIALIZABLE):要求事务序列化(按顺序)执行,事务只能一个接着一个地执行,不能并发执行。如同多人过独木桥,每次只能通过一个人,大家排队按顺序通过。
-
可重复读(REPEATABLE READS):事务从开始到结束,读取的值不受其他事务所影响,前后读 到的值一致。可以避免 “脏读” 和 “不可重复读”, 但是可能造成 “幻读”。MySQL 的 InnoDB 存储引擎默 认使用 REPEATABLE-READ(可重复读)隔离级别。
-
读已提交/已提交读(READ COMMITTED):只能读到其他事务已提交的修改,可产生 “不可重复 读” 现象(如图4.1)。Oracle 隔离级别为 READ COMMITTED(读已提交)。
-
读未提交/未提交读(READ UNCOMMITTED):读到了其他事务未提交的修改,产生 “脏读” 现象 (如图4.1)。
如 Oracle 中的隔离级别就是读已提交,即事务过程中能读取到其他事务已提交的数据。MySQL 可 以在四种隔离级别中自由选择,TiDB 可以选择可重复读、读已提交。即当 TiDB 设置为可重复读时,事 务只能读取到事务开始时,其他事务已提交的数据。
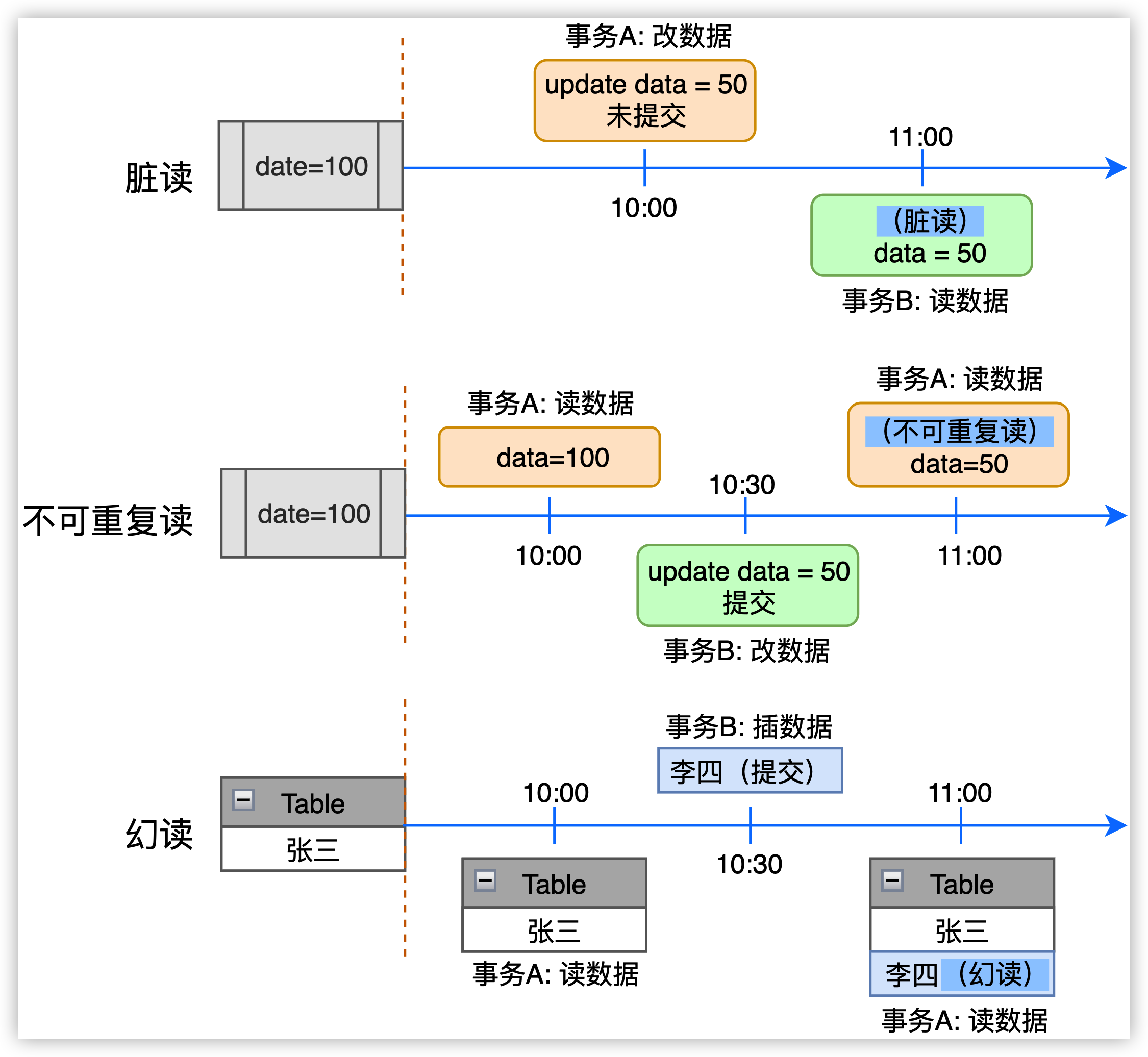
图4.1 脏读、不可重复读、幻读
不同的隔离级别,可出现如下三种现象(如图4.1所示):
-
脏读:如数据 data=100,事务 A 修改了数据(data=50),但未提交;与此同时,事务 B 读到了事务 A 对数据的修改(data=50),则称为 “脏读”。读未提交的隔离级别可出现 “脏读” 的现象。
-
不可重复读(主要指修改):同一事务,在不同时刻读到了不一样的值,这种现象称为 “不可重复 读”。如 10:00 事务 A 中读取 data=100,10:30 事务 B 修改数据 data=50,并提交;11:00 事务 A 再次读取 data,读取到 data=50,而不是 100(前后读取的数据不一致)。读已提交与读未提交的隔离级别, 均可出现 “不可重复读” 的现象
-
幻读(主要指插入):同一事务,在不同时刻读到其他事务新插入的数据,这种现象称为 “幻读”。如 10:00 事务 A 读取表,发现了 1 行 “张三”;10:30 事务 B 向表插入 1 行数据 “李四”,并提交;11:00 事 务 A 再次读取表,读到了 2 行数据 “张三、李四”。与 “不可重复读” 的主要差别在于 “幻读” 是涉及插入 操作,而 “不可重复读” 主要是更新。
3.1.3. 分布式事务模型:TCC 与 SAGA
分布式系统中,事务需要在多个物理节点中提交,如何保证分布式事务的原子性与一致性,成为了 分布式系统中的事务所需要面对的挑战。如图4.2所示,按地区划分数据库,每个地区都是一个独立的 MySQL 数据库。当分布式协调中间件接到事务请求后,根据地区将事务转发至对应地区的数据库中。 当事务操作的数据需要覆盖多个地区时,则分布式协调中间件会将事务请求转发至多个地区的数据库 中。当北京、上海、广州的事务提交成功,但深圳数据库宕机,无法完成事务的提交。此时,便破坏了 分布式事务的原子性与一致性。
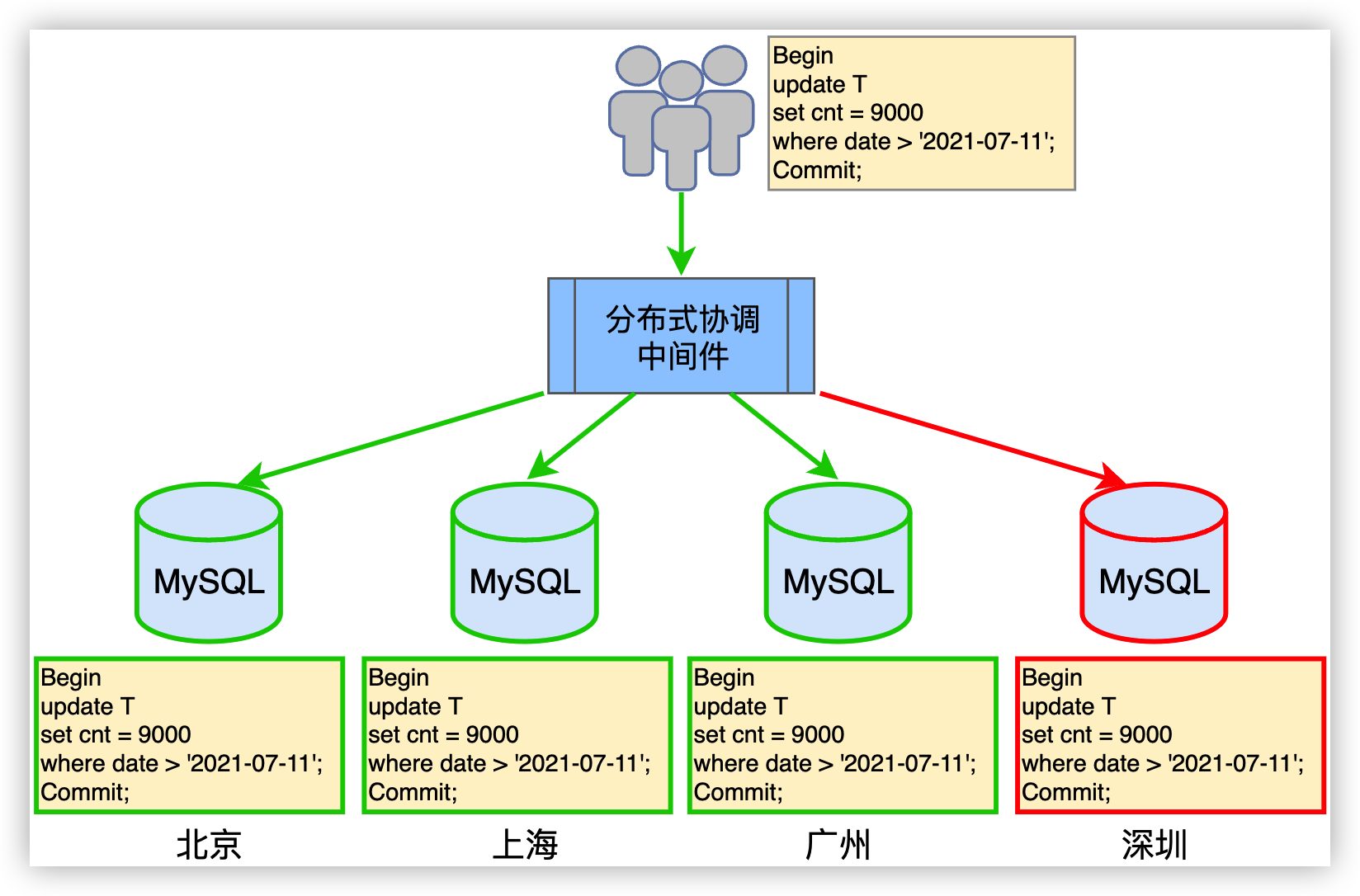
图 4.2 伪分布式系统
为了保证分布式事务的原子性及一致性,便产生了两种具有代表性的新的分布式事务模型:TCC (Try-Confirm-Cancel)、SAGA。
3.1.3.1. TCC(Try-Confirm-Cancel)
2007 年,Pat Helland 发表了一篇名为《Life beyond Distributed Transactions: an Apostate’s Opinion》的论文,提出了 TCC(Try-Confirm-Cancel)的概念。
TCC 是一种业务侵入式较强的分布式事务模型,要求业务处理过程必须拆分为 “预留业务资源(即 锁定资源)”、“确认/释放消费资源” 两个子过程(如图4.3 所示)。
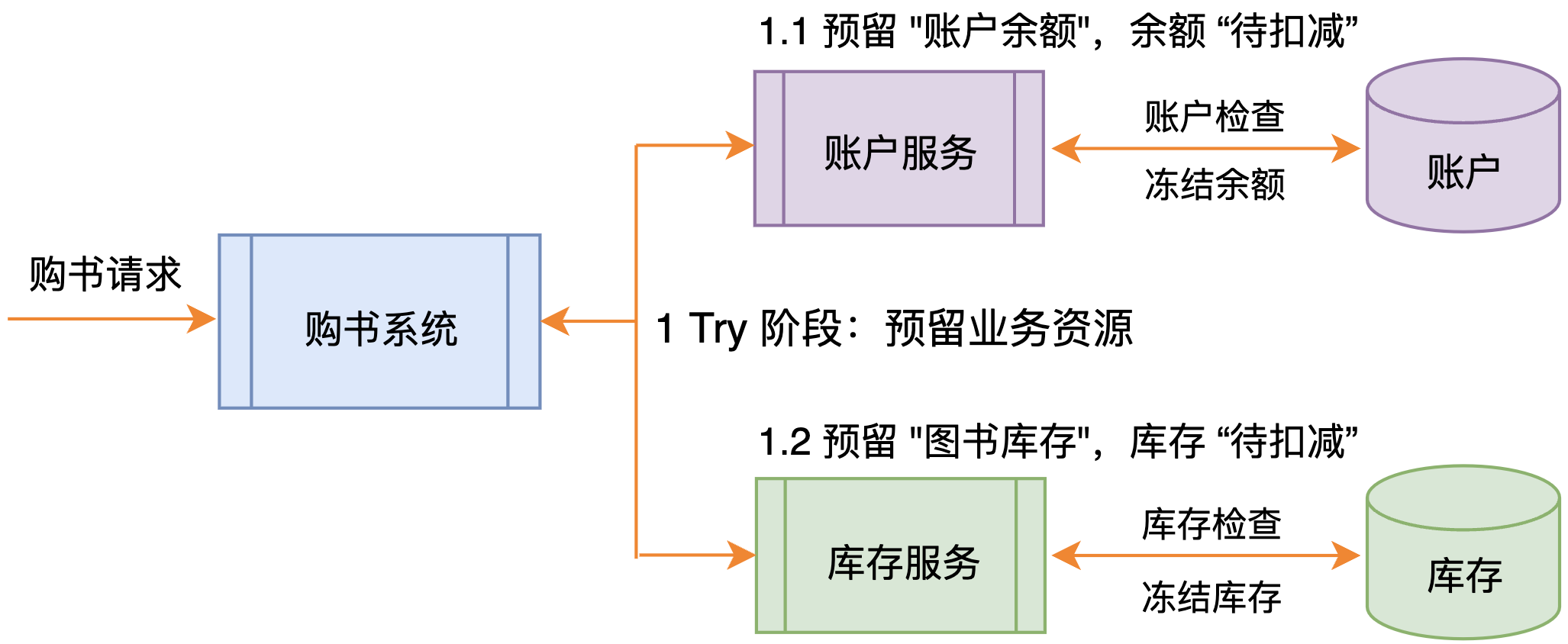
图4.3 TCC 分布式事务
如同 TCC(Try-Confirm-Cancel)名字所示,TCC 分 为三个阶段:
-
Try:尝试执行阶段,该阶段完成所有业务的可执行检查(保障一致性),并预留好全部需要用到的 业务资源(即锁定业务资源)。
-
Confirm:确认执行阶段,不进行任何业务检查,直接使用 Try 阶段准备好的资源,来完成业务处 理。Confirm 阶段可能会重复执行,因此本阶段执行的操作需要具备幂等性。
-
Cancel:取消执行阶段,释放 Try 阶段预留的业务资源,即释放 Try 阶段锁定的资源。Cancel 阶 段也可能会重复执行,因此本阶段执行的操作也需要具备幂等性。
【补充知识】
幂等性是指一个操作无论执行多少次,产生的效果是一样的。比如账户扣款接口(扣款 10 元),可能因为超时需要重试多次,于是会执行多 次扣款。执行一次扣款和重试多次扣款,最终结果需一致,都是扣款 10 元。
以 “用储值卡在线上书店购书” 为例,简要描述 TCC 的事务处理流程。假设该购书系统由 “账户服 务”、“库存服务” 构成。
- Try 阶段:用户提交购书的事务请求,“购书系统” 将事务分别提交至 “账户服务子系统”、“库存服务 子系统”,进行资源预留。
“账户服务子系统” 检查 “账户余额”,将余额置为“待扣款”。若 “余额” 不足,则释放资源, 直接进入 Cancel 阶段;
“库存服务子系统” 检查 “图书库存”,将库存置为“待扣减”。若 “库存” 不足,则释放资源, 直接进入 Cancel 阶段;
若账户服务与库存服务任意子系统的资源预留失败,则预留成功的子系统,需执行回滚操作,以释 放预留的资源,分布式事务进入 Cancel 阶段;若两个子系统均预留资源成功,则进入 Confirm 阶段。
-
Confirm 阶段:“账户服务子系统”、“库存服务子系统” 不进行资源检查,直接执行 “扣减余额”、“扣减库存”。执行失败的子系统需要一直重试,直至 “扣减余额/库存” 成功,并且重试接口需要保证幂等性。
-
Cancel 阶段:“账户服务子系统”、“库存服务子系统” 均执行回滚操作,释放资源。执行回滚失败的子系统需要一值重试,直至回滚成功,并且重试接口需要保证幂等性。
TCC 的弊端是对业务侵入性过强,Try 阶段资源的预留、Confirm 和 Cancel 阶段的重试及接口的幂等性等业务补偿代码,均需要由程序员来完成。整个分布式事务处理过程中,数据库不做任何干预。
3.1.3.2. SAGA
1987 年普林斯顿大学的 Hector Garcia-Molina 和 Kenneth Salem 发表了一篇关于 Sagas 的论文, 讲述的是如何处理 long lived transaction(长活事务)。Saga 是一种纯业务补偿模式,其设计理念为, 业务在调用的时候正常提交,当一个服务失败的时候,所有其依赖的上游服务都进行业务补偿操作。因 此,程序员在开发业务处理代码的同时,需要开发对应的业务补偿代码。如 “扣款” 处理需要开发对应 的 “退款” 处理。
以 “电商购物流程(支付订单-扣减库存-发货)” 为例,简介 SAGA 分布式事务模型的处理流程:
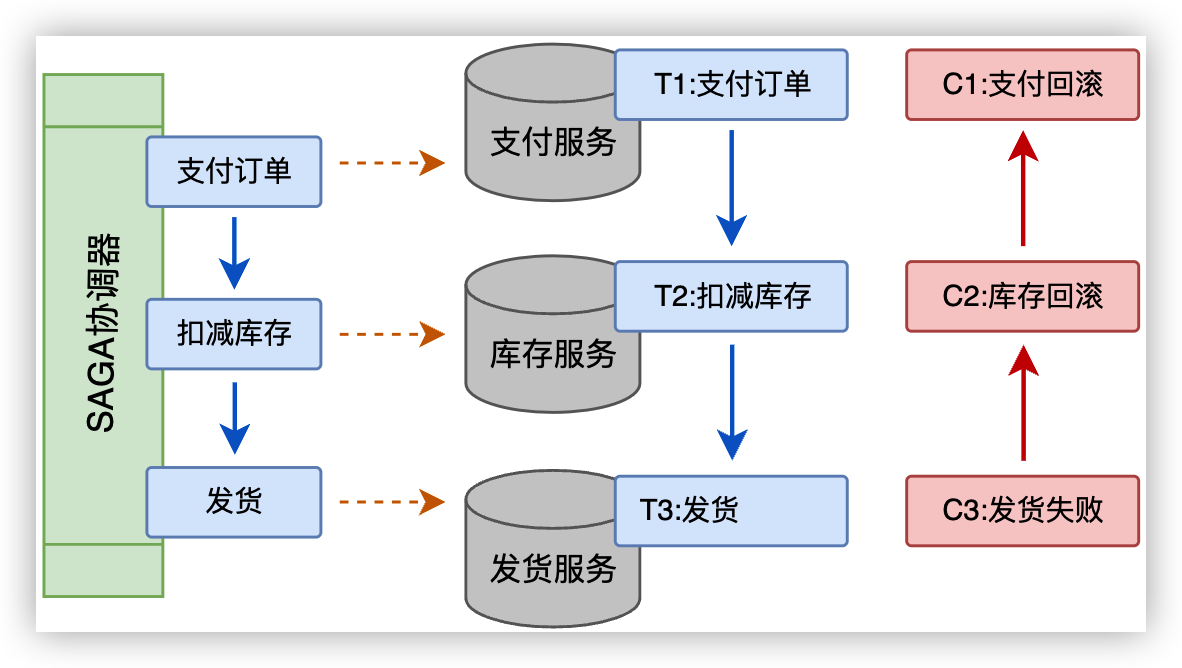
首先,将一个 “购物请求” 的大事务按服务类型拆分成 “支付”、“库存”、“发货” 三个子服务。每个子 服务对应一个数据库,如 “支付” 对应支付数据库,“库存” 对应库存数据库,“发货” 对应发货数据库。同 时,程序员需要针对每个子服务的处理,开发其对应的补偿方案,以便服务失败时进行回退。如针对“支付” 扣款的处理,需要开发对应的 “退款” 方案;针对 “扣减库存”,需要开发对应的 “库存回滚” 方案等。
比如,当 “支付订单”、“扣减库存” 成功,而 “发货” 失败时。首先,“发货” 服务回滚,并分别执行 “扣 减库存” 的补偿方案(加回库存)与 “支付订单” 的补偿方案(退款处理)。从而,整个 “购物请求” 的大 事务被回滚。
SAGA 分布式事务模型通常按服务来进行分片,因此更适用于微服务的应用场景。
3.1.4. 2PC(Two-Phase Commit)
2PC(Two-Phase Commit)即两阶段提交,又称为 XA Transactions,即将整个分布式事务流程分 为 Prepare、Commit 两个阶段:
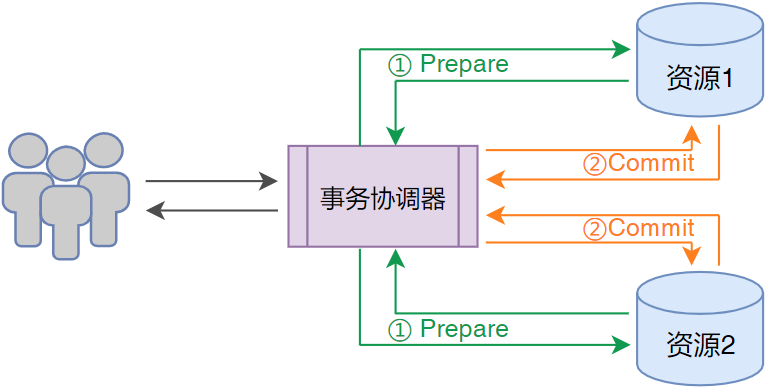
-
准备阶段(Prepare phase):事务管理器给每个参与者发送 Prepare 消息,每个数据库参与者在 本地执行事务,并写本地的 Undo/Redo 日志,此时事务没有提交。(Undo 日志是记录修改前的数据, 用于数据库回滚,Redo 日志是记录修改后的数据,用于提交事务后写入数据文件);
-
提交阶段(Commit phase):如果事务管理器收到了参与者的执行失败或者超时消息时,直接给每 个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据事务管理器的指令 执行提交或者回滚操作,并释放事务处理过程中使用的锁资源。
与 TCC 和 SAGA 的区别是 2PC 中的 Prepare 与 Commit 都交由数据库来处理,无需程序员干预, 对业务开发几乎零侵入。但是,2PC 事务模型会存在如下问题:
- 同步阻塞
Prepare 阶段对需要操作的数据行进行加锁、数据修改操作,但是,不提交。其他事务若要操作这些行,需要等待锁的释放。
- 单点故障
负责事务管理的事务协调器存在单点故障。
- 网络延迟
Prepare 与 Commit 均需要通过网络传输数据,因此可能存在网络延迟。
3.2. Percolator 事务模型
3.2.1. Percolator 简介
Percolator 是 Google 提出的分布式事务解决方案,主要解决 bigtable 不支持跨行(分布在多台 节点的多行)事务的历史遗留问题。Percolator 充分利用 BigTable 的行级事务来实现自己的分布式事 务,在保持 BigTable 的优点(良好的水平扩展能力、支持海量数据)的情况下,通过添加必要的辅助 服务,解决了 BigTable 只支持行级事务的弱点,实现了支持跨行跨表的分布式事务。Percolator 本质 上还是 2PC,但是对传统 2PC 做了优化。
【补充知识】
Bigtable 是 2005 年谷歌的论文:《Bigtable: A Distributed Storage System for Structured Data》中介绍的一种用于存储海量数 据的分布式存储系统,后来被 Hadoop 社区实现为 HBase。相关中文介绍见 https://www.biaodianfu.com/google-bigtable.html。
Percolator 的三大要素:
- 全局时序 TSO
因数据散落在多个节点,因此需要一个全局的时钟服务来标记事务的开始时间、结束时间以及事 务的先后顺序。
- Snapshot 隔离级别
通过隔离级别,控制多个事务并发的协议,如事务之间如何隔离。Percolator 中的隔离级别为 Snap-shot Isolation(快照隔离级别),即事务只能读取到其开始时,其他事务已提交的数据。
- 2PC 两阶段提交
通过 2PC 两阶段提交,保证分布式事务的原子性和一致性以及自动的回滚。
3.2.2. 快照隔离级别 (Snapshot Isolation)
事务只能看到早于它开始时刻(start_ts)之前,其他事务提交的修改,类似于 ISO 标准中定义的 可重复读(REPEATABLE READS)隔离级别。区别是可重复读的隔离级别中,可能出现 “幻读”,而快 照隔离级别中不会出现 “幻读”。如图4.5所示。事务T2开始时,事务T1还未提交。因此,事务T2无法看 到事务T1提交的修改;事务T3开始时,事务T1与T2均已提交。因此,事务T3可看到事务T1与T2提交的 修改。
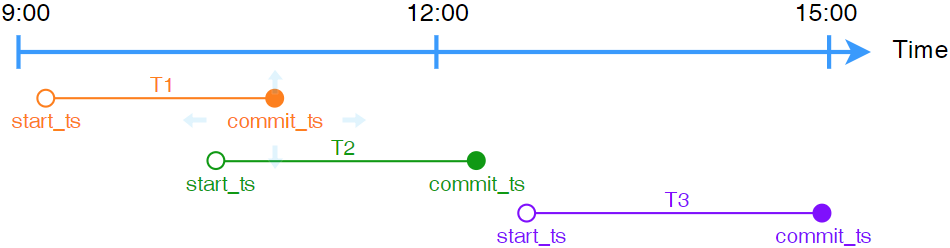
图 4.5 Snapshot Isolation
在 TiDB 的快照隔离级别中,如果事务采用了悲观锁模型,则事务在执行过程中,可以感知到其他 事务的锁信息,跟 MySQL 中的可重复读隔离级别类似。;如果事务采用了乐观锁模型,则事务在执行 过程中,感知不到其他事务的锁信息,认为所有修改的行都是无锁的。
3.2.3. 分布式时钟
快照隔离级别认为所有事务都需要一个开始时间戳(start_ts)与结束时间戳(commit_ts)。因此, 分布式授时是分布式事务的核心。常见的分布式授时方法如表所示:
| 授时方法 | 单点**/**多点 | 物理**/**混合 | 代表产品 |
|---|---|---|---|
| True Time | 多点授时 | 物理 | Spanner |
| HLC | 多点授时 | 混合 | CockroachDB |
| TSO | 单点授时 | 混合 | TiDB |
多点授时的特点是去中心化、支持全球化、延迟低;单点授时的特点是方法简单、误差小,但是存 在单点故障。
3.2.4. Percolator 流程
Percolator 分布式事务模型中包括三个核心组件:
- Client:客户端即事务协调器,负责协调事务的两阶段提交。在 TiDB 数据库中,事务协调器由 TiDB
Server 来承担;
-
TSO:全局授时器是 Percolator 分布式模型中的授时中心,在 TiDB 数据库中,由 PD 节点来承担;
-
Bigtable:存储在各节点上的数据。在 TiDB 数据库中,由 TiKV 节点来承担。
Percolator 在整个分布式事务的提交过程中,将事务的提交分成两个阶段:PreWrite 和 Commit。
3.2.4.1. PreWrite
BigTable 中的每行数据由三个列簇(Column Family, CF)存储,即 Data、Lock、Write。
-
Write:数据列簇,一个 “写事务” 最终被成功提交后,相应的数据部分是存储于 Write 列簇中的;
-
Data:临时数据列簇,MVCC 写过程中会将被修改的数据写入该列,视最终事务的结果是 commit (成功),还是 roll-backward、roll-forward 来决定如何解释 Data 列簇数据;
-
Lock:锁所在的列簇,某个事务在进行修改数据行时,会通过写入该列簇来锁住该行。在目前的实现下只要发现某行上存在锁(任意时刻的锁),即需要终止本事务。 Prewrite 阶段包含以下步骤:
Prewrite 阶段包含以下步骤:
-
事务在开始时,通过 Coordinator 向 TSO 获取一个开始时间戳 start_ts。
-
事务将要修改的多行数据中的第一行设置为主行,并对其加锁。事务会先读取被修改行的Lock列,如果第一行已经有锁(如正被其他事务修改),即返回 “写写冲突” 报错。
-
事务给其他要修改的行各加上一把指向主行的 “锁”。事务会先读取其他行的 Lock 列,如果其他行 上已经有锁,也返回 “写写冲突” 报错,并清除主行上的锁。
-
当发现冲突并不存在之后,事务开始真正更新数据,将新的数据版本写入 Data 列,之后将该行对 应的 Lock 列也更新(即写入锁信息)。
3.2.4.2. Commit
Commit 阶段包含以下步骤:
-
事务通过 Coordinator 向 TSO 获取一个提交的时间戳 commit_ts。
-
事务提交主行修改,将新的数据版本写入 Write 列,并清除主行上的锁。一旦主行完成提交,即认为事务提交成功。
-
事务提交其它行的修改,将新的数据版本写入 Write 列,并清除其他行上指向主行的锁。
如果在主行 commit 前,客户端或服务器发生了 Crash。服务器恢复正常后,将整个事务 roll-back(回滚)。
如果其他行 commit 前,客户端或服务器发生了 Crash。服务器恢复正常后,会执行 roll-forward(前滚)将所有记录恢复以得到数据完整性,以保证在其他事务读操作的时,依然可以看到整个事务的 完整性。
3.2.5. Percolator 案例
以 “Bob 拥有 10 元,Joe 拥有 2 元,Bob 向 Joe 转账 7 元” 为例,讲解 Percolator 事务模型的事 务处理流程。其初始状态时(未转账前),数据在 BigTable 中的存储如图4.6所示(Bob 与 Joe 存储在 不同的节点中)。

图 4.6: BigTable 数据存储的初始状态
其中,各 CF(Column Family)如下:
-
Data CF 存储的是带版本号的数据,格式为 “版本号: 数值”。如 “5:10 元” 表示版本号为 5,数值为10 元。
-
Lock CF 存储的是锁信息。当事务修改数据行时,需要为数据行加锁,就会将锁信息写入 Lock CF中。
-
Write CF 存储的是写入版本,格式为 “版本号:Data CF 指针”。指针永远指向 Data CF 中最新版本的数据。如 “6: data@5”,其中 6 表示当前数据行最新版本号为 6,该版本号指向 Data CF 中版本号为 5 的数据。
如图所示,当用户读取数据时,首先通过 Bob 的 Write CF 读取到 “6:data @5” 得知,当前最新时 间点(即版本号为 6),Bob 拥有的钱数(data @5)是指向 Bob 的 data CF 中版本号为 5 的值,即 10元(5:10 元);通过 Joe 的 Write CF 读取到 “6:data @5” 得知,当前最新时间点(即版本号为 6),Joe拥有的钱数(data @5)是指向 Joe 的 Data CF 中版本号为 5 的值,即 2 元(5:2 元)
3.2.5.1. PreWrite 阶段
该转账事务的案例中,需要修改多行(即 Bob 和 Joe 两行数据)数据(如图4.7所示)。
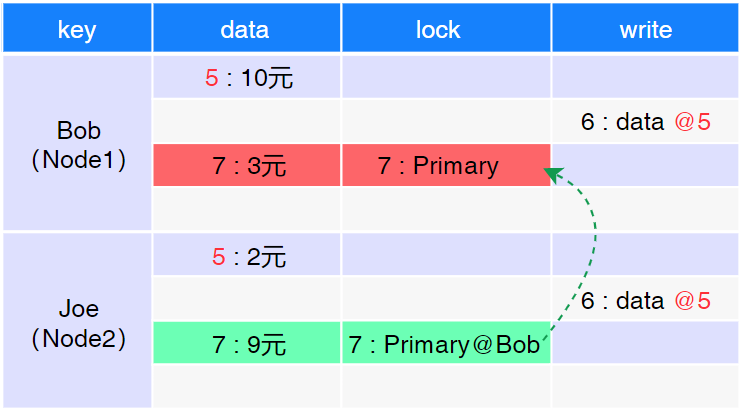
图4.7: PreWrite 阶段
首先,选取 Bob 为主行,执行数据修改。为 Bob 行加主锁(即 “7:Primary”),并写入至 Lock CF;将 修改后(10-7=3 元)的数据(“7:3 元”)写入 Data CF。然后,执行其他行修改,为 Joe 行加锁(“7:Primary @Bob”),该锁指向 Bob 的主锁;并将 Joe 修改后(2+7=9 元)的数据(“7:9 元”)写入 Data CF 中。
此时,若其他事务要修改 Bob 或 Joe 数据,会读取到 Bob 的主锁信息,从而进入阻塞状态,等 待 Bob 主锁的释放。
【注意】
事务要修改 Joe 数据时,可通过 Joe 锁信息(“7:Primary @Bob”)中的锁指向,找到 Bob 中的主锁。
3.2.5.2. Commit 阶段
当所有数据行都完成 PreWrite 阶段后,事务进入 Commit 提交阶段(如图4.8所示)。
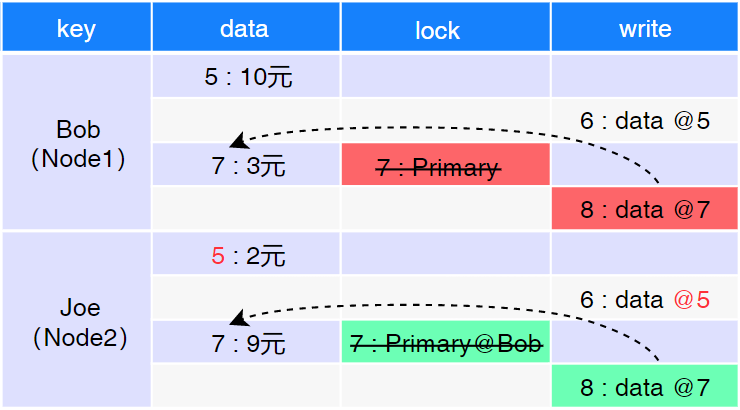
图 4.8: Commit 阶段
首先,清除主行 Bob 的锁信息 “7:Primary”,将提交信息 “8:data@7”(表示 Bob 数据最新版本号为 8,指向 Data CF 中版本号 7)写入 Bob 的 Write CF 中,主行提交完毕;然后,同理提交其他行(Joe), 清除 Joe 的锁信息 “7:Primary @Bob”,将提交信息 “8:data@7” 写入到 Joe 的 Write CF 中。
如果在对主行(Bob)执行 Commit 时,节点 node1 宕机,则节点 node1 重启后,直接将 PreWrite 阶段对 Data CF 的修改和插入到 Lock CF 中的锁信息进行回滚即可。
如果在对其他行(Joe)执行 Commit 时,节点 node2 宕机。则节点 node2 重启后,当有事务读 取 Joe 的数据时,通过 Joe 的锁指向(“7:Primary@Bob”)找到该事务的主锁(“7:Primary”),发现该 主锁已清除(说明该事务已提交,而节点 node2 丢失了提交信息)。于是,节点 node2 清除 Joe 的锁 信息,将丢失的提交信息(“8:data@7”)写入 Joe 的 Write CF 中,此过程称为 “roll-farword(前滚)”。
通过以上的 Percolator 事务处理流程,可知其存在如下优点和缺点:
-
优点:实现简单、基于单行的事务基础上,实现了跨行事务、去中心化的锁管理。
-
缺点:需要管理中心化的版本号、网络交互较多。
3.3. TiDB 数据库事务的实现与优化
3.3.1. TiDB 数据库事务实现
TiDB 数据库中事务的实现以 Percolator 分布式事务模型为基础,并对其进行了优化。
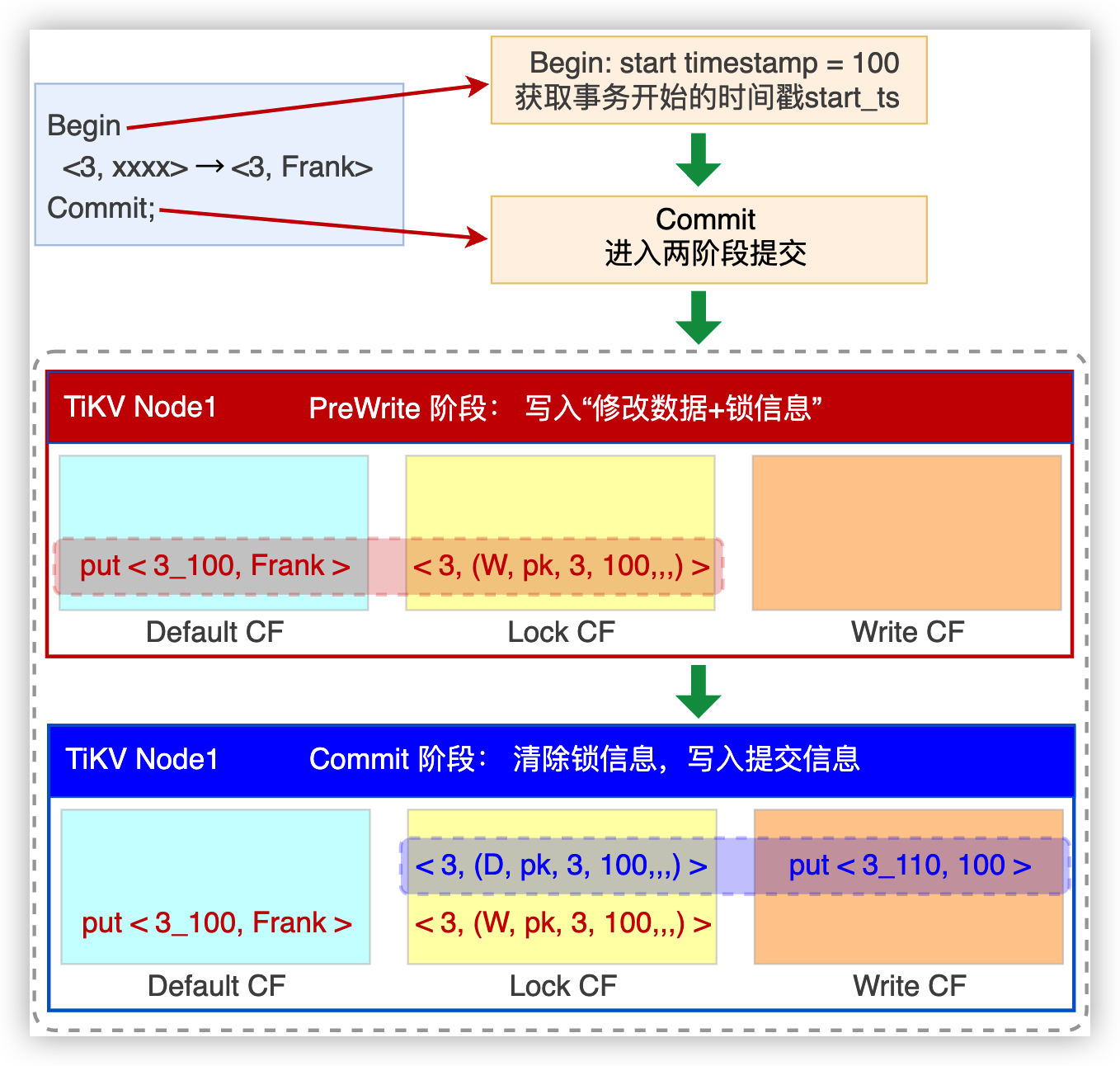
图 4.9: TiDB 数据库中的本地事务
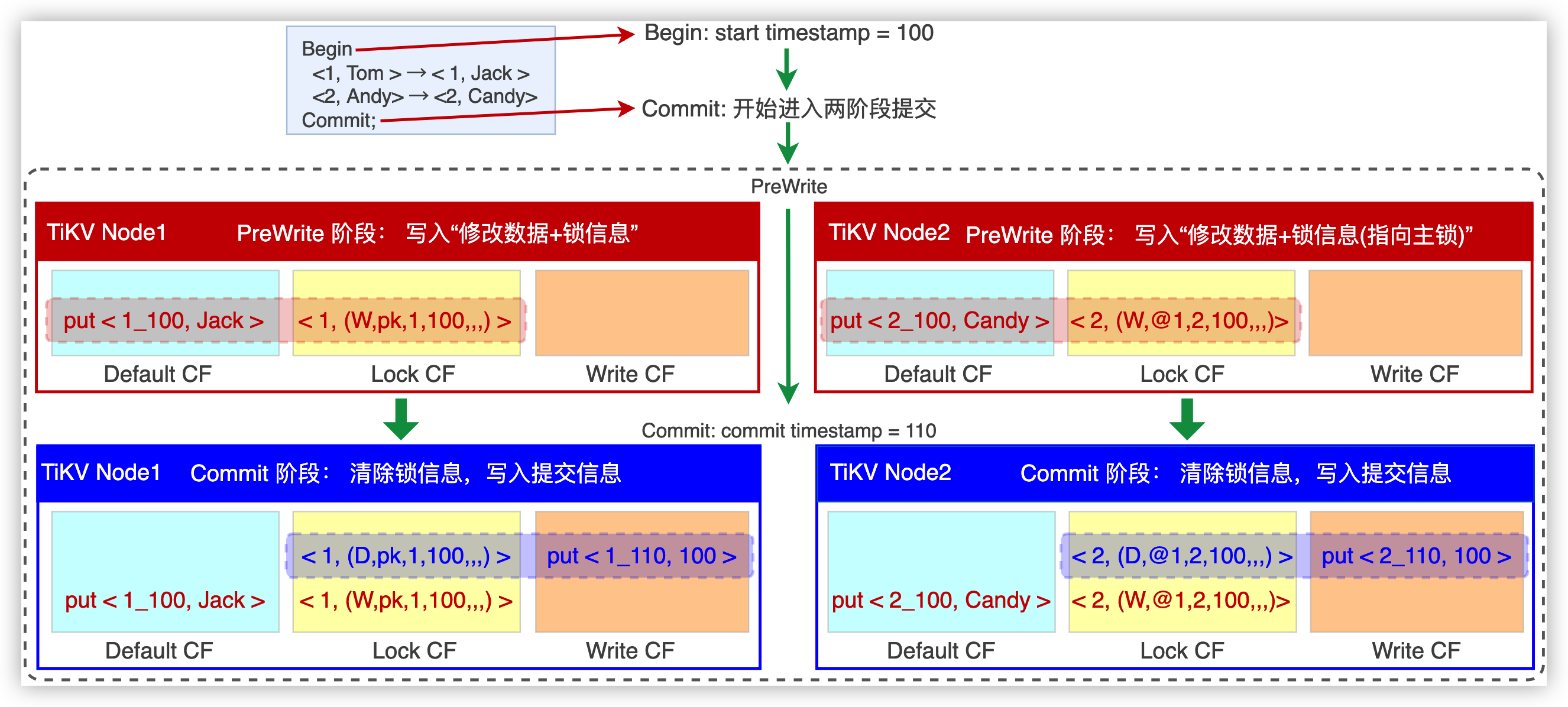
图 4.10: TiDB 数据库中的分布式事务
PreWrite 版本检查,事务开始时用自己的 start_ts 与 Write CF 中最近一次提交记录的 commit_ts 对比。若 start_ts > commit_ts,说明数据未被其他事务修改,则当前事务继续;若 start_ts < commit_ts, 说明数据已被其他事务修改,则当前事务回滚。
3.3.2. TiDB 数据库的锁
transaction_isolation read-committed、REPEATABLE-read tidb_txn_mode optimisti(c 乐观锁)pessimistic(悲观锁)对并发高,冲突较少的场景,可使用乐观锁;对冲突较敏感的场景,可用悲观锁。
3.3.3. 写偏斜(write skew)
REPEATABLE-read 可重复读、snapshot isolation 隔离级别可能出现写偏斜。 select * from table for update 开启当前读,来避免写偏斜。
