




为什么要用中间件
传统的模式是应用直接连接数据库进行访问。非常简单,但是随着业务量不断增加我们就会遇到问题:
单个表数据量太大,读写锁,插入操作重新建立索引效率变低
单个库数据量太大,一个库2T就是极限
单台服务器压力太大
读写速度遇到瓶颈,并发几百
为了解决上面我们需要水平扩展数据库。直接增加机器,将数据库放在不同的服务器上,在应用和数据库之间加个中间件路由,来解决上面的问题。
拆分方式:
垂直拆分。
水平拆分
按照规则划分,一般水平分库是在垂直分库之后的。比如每天处理的订单数量是海量的,可以按照一定的规则水平划分。需要解决的问题:数据路由、组装。
读写分离,对于时效性不高的数据,我们可以采用读写分离来缓解数据库压力。
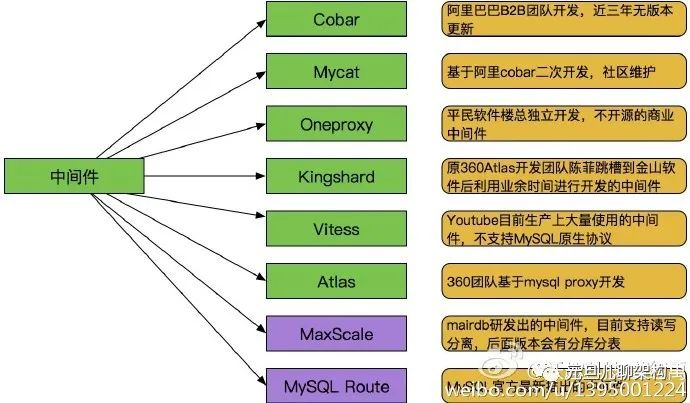
各类中间件对比
https://blog.csdn.net/w892824196/article/details/82660415
分布式数据库中间件对比总结
DBLE的原理
今天学习了DBLE,对这块中间件做下总结。
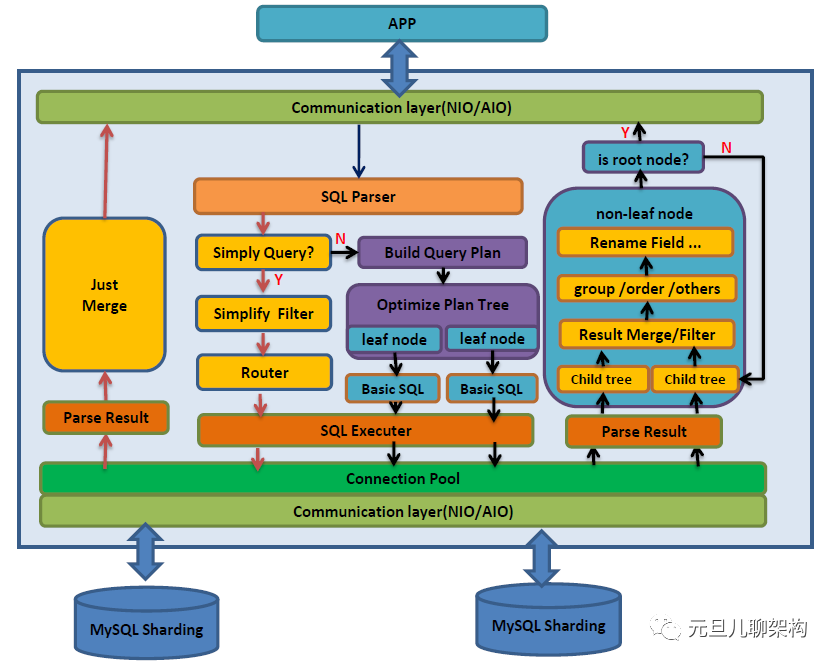
分布式数据库DBLE
https://blog.csdn.net/u010882691/article/details/82256955
DBLE的配置和使用
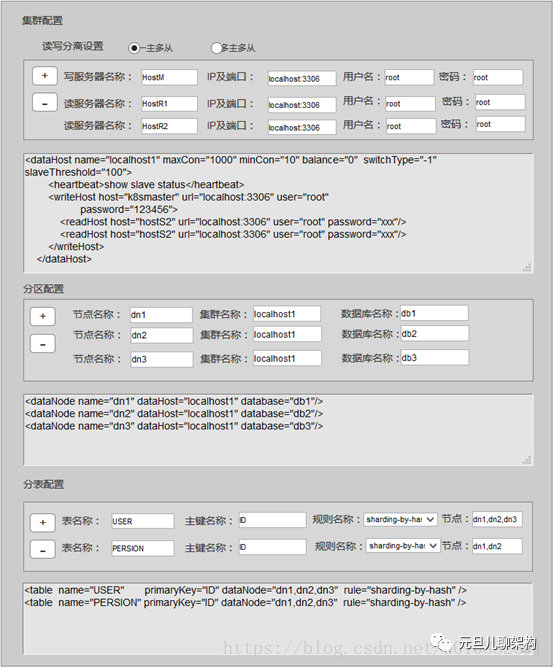
server.xml 配置和DBLE相关的许多参数,比如DBLE的服务端口(默认8066)和管理端口(默认9066)以及配置用户和针对不同用户对数据库的权限。
schema.xml是最主要的配置,里面包含库和表的定义。包含dataNode,dataHost,schema等标签
<dataNode name="dn1" dataHost="localhost1" database="db1"/><dataNode name="dn2" dataHost="localhost1" database="db2"/><dataNode name="dn3" dataHost="localhost1" database="db3"/><dataNode name="dn4" dataHost="localhost1" database="db4"/><dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" switchType="-1" slaveThreshold="100"><heartbeat>show slave status</heartbeat><!-- can have multi write hosts --><writeHost host="hostM1" url="localhost:3306" user="root"password="123456"><!-- can have multi read hosts --><readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx"/></writeHost><writeHost host="hostS1" url="localhost:3316" user="root"password="123456"/><!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> --></dataHost>
网上说有工具配置的,具体用到时可以找找。
表按拆分存储的形式分为
分片表:数据进行水平拆分的表,按规则分布在指定数据节点
全局表:在所有节点都存在全量的数据表
非分片表:存储在默认数据节点中的表。没配置的表都会落在默认数据节点,这些表叫做非分片表。
rule.xml主要关注分区规则的定义和分区算法的定义。分表算法大致分为以下几类:
sharding-by-enum:按照枚举方式,执行分表操作。
sharding-by-range:按照区间范围,执行分表操作。
sharding-by-hash:按照hash算法,执行分表操作。
sharding-by-hash2:按照hash算法,执行分表操作。
sharding-by-hash3:按照hash算法,执行分表操作。
sharding-by-mod:按照计算取模,执行分表操作。
sharding-by-hash-str:按照字符串hash算法,执行分表操作。
sharding-by-date:按照日期,执行分表操作。
sharding-by-pattern:按照分片字段值进行模运算,执行分表操作。
sharding-by-string-jump:按照计算概率分布的方式,执行分表操作。
为了以后扩容方便,我们尽量要预分配。预估未来数据增长情况,提前分配,比如目前2台数据库机器就满足业务需要,未来三到五年可能会增加到8台。提前将数据分成8张表,一台建四个表。以后迁移时就可以整表迁移。
DBLE使用限制及优化
大家可以到DBLE官网查看【https://opensource.actionsky.com/dble/】里面介绍的很详细。下面罗列写不支持的语句。
DDL:不支持针对database的操作语句,包括alter database、drop database。create database 在管理端口支持,流量端口遇到会判断schema已经配置后返回ok,否则报错。不支持create table时的一些table option,如DATA DIRECTORY、ALGORITHM等,table option在alter table时也不能修改不支持ALTER TABLE ... LOCK ...不支持ALTER TABLE ... ORDER BY ...不支持create table ... like ...和create table ... select ...库名、表名不可修改,拆分字段的名称和类型都不可以变更不支持外键关联不支持临时表不支持分布式级别的存储过程和自定义函数不支持触发器DML:对于INSERT... VALUES(expr),不支持expr中含有子查询不支持INSERT DELAYED...不支持INSERT... SELECT...不支持不包含拆分字段的INSERT语句不支持HANDLER语句不支持UPDATE多张表不支持修改拆分字段的值不支持DELETE ... ORDER BY ... LIMIT ...不支持DELETE多张表不支持DELETE/UPDATE ...LIMIT路由到一个分片表的多个节点不支持DO语句查询:不支持select ... use/ignore index ...不支持select ... group by ... with rollup不支持select ... for update | lock in share mode 正确语义不支持select ... into outfile ...不支持Row Subqueries不支持select ... union [all] select ... order by ...,可写成(select ...) union [all] (select ...) order by ...不支持session变量赋值与查询,如set @rowid=0;select @rowid:=@rowid+1,id from user;管理语句:不支持用户管理及权限管理语句不支持表维护语句,包括ANALYZE/CHECK/CHECKSUM/OPTIMIZE/REPAIR TABLE不支持INSTALL/UNINSTALL PLUGIN语句不支持BINLOG语句不支持CACHE INDEX/ LOAD INDEX INTO CACHE语句不支持除FLUSH TABLES [WITH READ LOCK]以外的其他FLUSH语句,FLUSH TABLE也仅语法支持无实际意义不支持RESET语句不支持大部分的运维SHOW语句,如SHOW PROFILES、SHOW ERRORS等
根据上面的限制,我们应该明白,为了以后使用方便大家在日常开发中要养成良好的习惯,尽量不要过度使用数据库的功能,尽可以将逻辑放在应用程序实现,避免使用触发器和存储过程等数据库特有的功能,导致以后数据库迁移和水平拆分增加庞大的工作量和风险。
再说说技术选型关注几个点:
社区是否活跃,比如DBLE社区活跃,不像mycat,mycat社区不活跃,不再追踪mycat的bug。这是很多市面选择软件考虑的很重要因素。
源码是否开源,是否容易维护和修复BUG。之前看过rabbitMQ是erlang语言开发,国内这样的人才较少,如果社区不活跃,项目要不断承担较大风险遇到BUG无法解决的尴尬局面。
对开发者要求低,容易上手,如果限制太多,也不利于项目的开发和维护。
TPS多少。响应时间等是否能满足我们的业务场景。比如某些MQ会有丢消息的情况,我们的业务是否能容忍这样情况发生。都是要考虑的方面。
没有完美的产品,只有适合的才是最好的。
