




2021年3月份一天,业务人员反应他们的核心业务SQL存在执行超时(执行时间大于1s)情况,SQL如下:
SELECT a.ACCT_BALANCE_ID AS ACCT_BALANCE_ID, a.BALANCE_TYPE_ID AS BALANCE_TYPE_ID, NVL(TO_CHAR(a.EFF_DATE, 'yyyymmddhh24miss'), '19980101000000') AS EFF_DATE, NVL(TO_CHAR(a.EXP_DATE, 'yyyymmddhh24miss'), '20481231235959') AS EXP_DATE, a.BALANCE AS BALANCE, a.RESERVE_BALANCE AS RESERVE_BALANCE, NVL(a.CYCLE_UPPER, 0) AS CYCLE_UPPER, NVL(a.CYCLE_LOWER, 0) AS CYCLE_LOWER, NVL(a.CYCLE_UPPER_TYPE, '0') AS CYCLE_UPPER_TYPE, NVL(a.CYCLE_LOWER_TYPE, '0') AS CYCLE_LOWER_TYPE, a.STATE AS STATE, TO_CHAR(a.STATE_DATE, 'yyyymmddhh24miss') AS STATE_DATE, a.ACCT_ID AS ACCT_ID, a.REGION_ID_ACCT AS REGION_ID_ACCT, a.USE_RULE_FLAG AS USE_RULE_FLAG, a.BALANCE_PRINT AS BALANCE_PRINT, a.BALANCE_INTEREST AS BALANCE_INTEREST, NVL(a.QUOTA_TYPE, '0') AS QUOTA_TYPE, a.OPER_SERIAL_NBR AS OPER_SERIAL_NBR, TO_CHAR(a.CREATE_DATE, 'yyyymmddhh24miss') AS CREATE_DATE, a.PARTITION_ID_ACCT AS PARTITION_ID_ACCT, NVL(a.CYCLE_USED, 0) AS CYCLE_USED FROM bj.BALANCE a WHERE 1 = 1 AND a.STATE < '2' AND '1' = :1 AND a.PARTITION_ID_ACCT = :2 AND a.ACCT_ID = :3ORDER BY a.ACCT_BALANCE_ID ASC复制
首先查看执行计划:很优秀
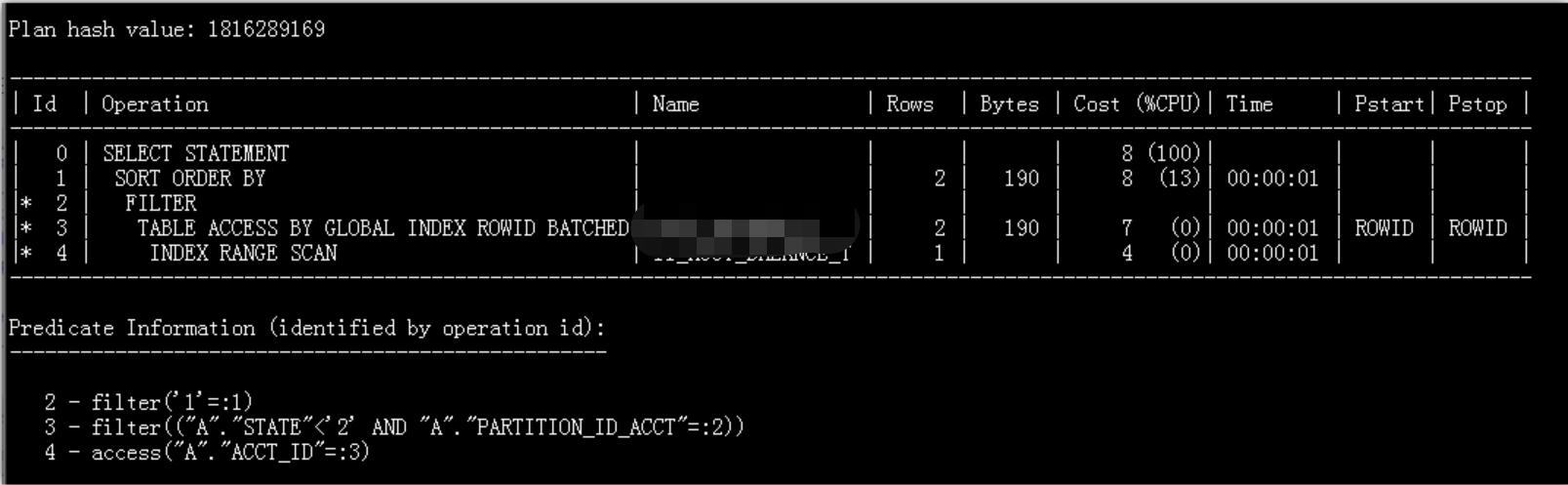
执行计划优秀,没有任何异常,我们再次查看SQL历史执行信息:平均执行时间:节点1 0.8ms,节点3 16ms 。
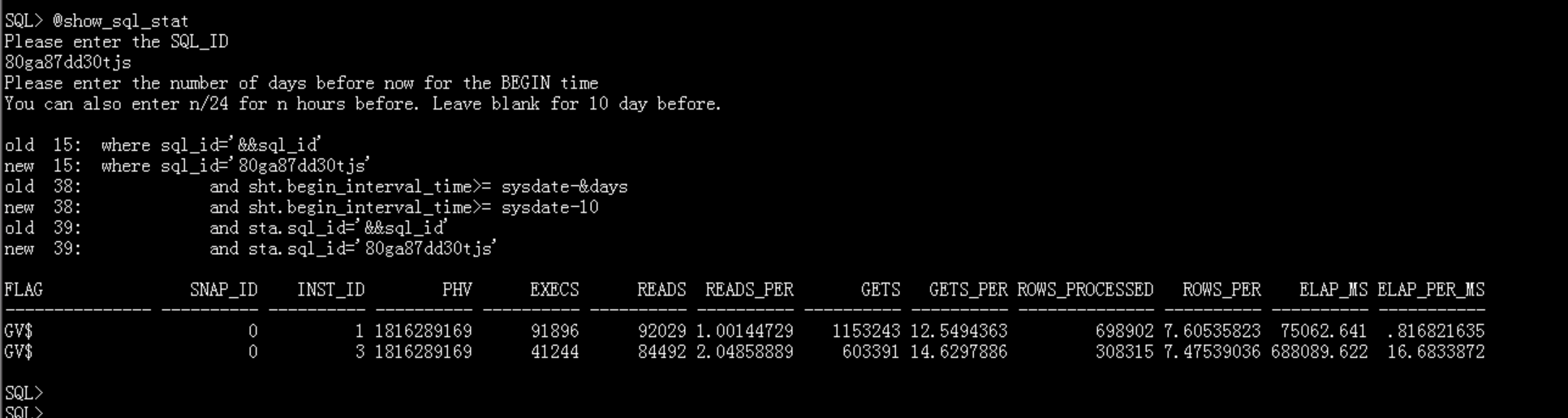
通过sql文本查询得到SQL ID 80ga87dd30tjs
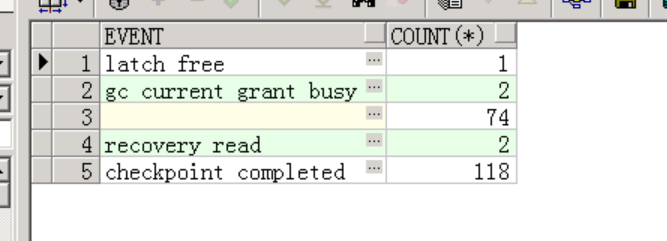
于是通过v$ash视图查询此SQL ID 超时问题严重的会话,根据sql_exec_id分组统计。找到捕获次数为11的会话(执行至少11s)。等待事件为“buffer busy waits”,说明要查询的块很忙。

继续跟踪阻塞源session 对应的event 为 checkpoint completed ,说明我的读操作,正在等待CHK 完成(Checkpoint做的事情之一是触发DBWr把buffer cache中的dirty cache写入磁盘。另外就是把最近的系统的SCN更新到datafile header和control file)。
继续查询堵塞checkpoint completed session的会话,对应的event 是 “control file parallel write” 。
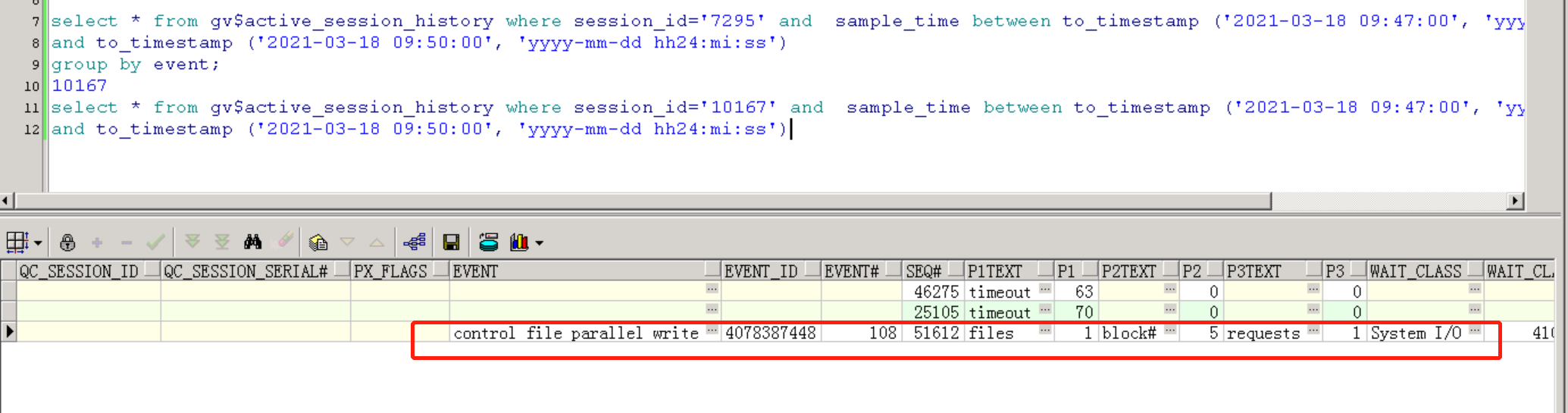
为了进一步加强我们的判断,于是取了ASH HTML报告看下:
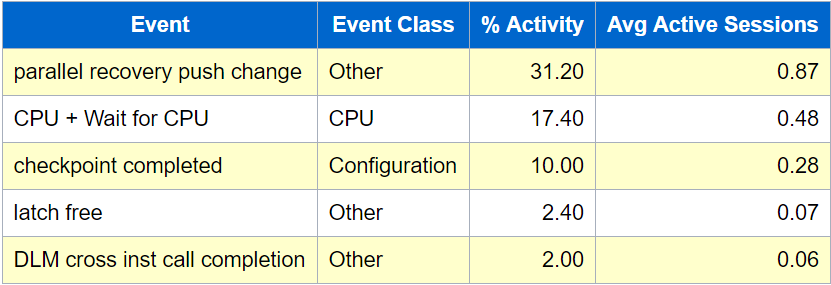
在SQL超时严重时间段,ADG在执行 并行恢复操作,也就是实时redo应用。
综合以上信息,得出结论:写堵塞了读。
虽然我们常说Oracle的读不阻塞写,写不阻塞读。但在一些极端情况下,写是会阻塞读的。我怀疑是主库在同期有大量的DML操作(经过查询主库确实存在大量DML),其日志同步到备库后,由于相关业务SQL(查询)的执行,需要对相关块访问并加共享锁。但如果目标数据块正在写(写的过程中,该块不允许被修改,写完磁盘后,需要标记该块为干净的块,这些动作,都需要对块加排它锁),就会出现阻塞,就会出现写阻塞了读的情况。也就是备库的刷新写入操作影响select操作。
解决办法:由于MRP进程在节点3启动,所以上面节点3的avg time远远高于节点1。为了规避这种情况,我们让业务查询操作都连接节点1,就完美规避了这个缺陷,业务查询不再报超时。
评论

 0 点赞
0 点赞 1 1
1 1