




0. 准备知识
RDD(Resilient Distributed Datasets),直译为弹性分布式数据集,是spark中最核心的概念。RDD是对数据的虚拟抽象,本身不包含真实的数据。RDD详细描述可参考论文(http://people.csail.mit.edu/matei/papers/2012/nsdi_spark.pdf),这里不做过多介绍。
spark的计算流程:
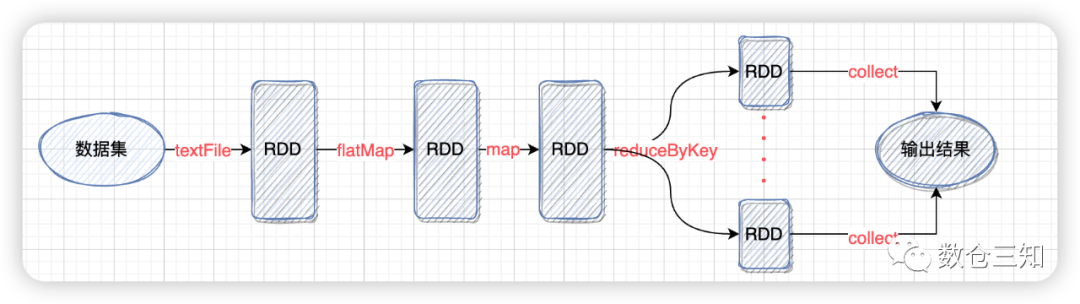
1. 数据集通过spark接口转换成RDD,例如:
textFile
,hadoopFile
,binaryFiles
等2. 根据业务逻辑,使用transform算子(
map
,filter
,flatMap
,union
,distinct
,reduceByKey
等)、action算子(reduce
,collect
,count
,first
,saveAsTextFile
等)将RDD组装成DAG(有向无环图)。可以简单理解是数据的加工计算链路。3. 调用action算子时,数据通过上述的DAG链路,计算结果后输出。
以最熟悉的word count为例,计算流程如图:
1. SparkPlan是什么
1.1 SparkPlan是什么
一条SQL经过parser转化成LogicalPlan(逻辑执行计划),LogicalPlan经过Analyzer、Optimizer解析、优化后,生成更适合计算的LogicalPlan。LogicalPlan简单理解为数据大概的(逻辑上的)计算过程(类比设计师设计的图纸),不能真正的运行,因为缺少必须的要素,如数据(RDD)以及具体的算子的执行算法等。SparkPlan就是要将计算缺少的要素具象化(工人根据图纸拆分成具体的操作流程)。
SparkPlan的继承关系:
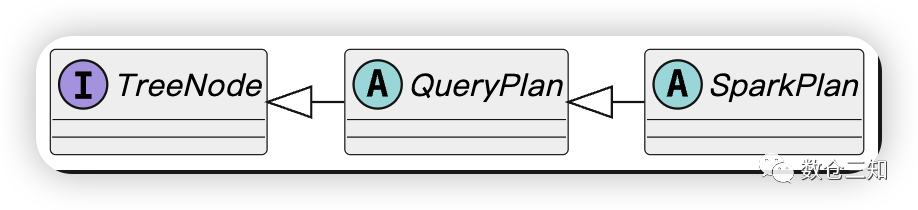
SparkPlan是一棵树,树的叶子节点(LeafExecNode
子类)的doExecute
,execute*
方法生成第一个RDD,非叶子节点(UnaryExecNode
,BinaryExecNode
)的doExecute
,execute*
方法表示了当前节点数据计算的算法(transform
算子),根节点表示计算结果的输出方式(action
算子)。
简而言之,SparkPlan就是可以交给spark框架执行的一棵树。
实际上通过
QueryExecution.createSparkPlan()
生成的SparkPlan还不能直接运行,还需要经过QueryExecution.prepareForExecution()
增加一些shuffle操作和内部行格式转换才能最终交给spark执行。但转换后还是SparkPlan类。
1.2 SparkPlan做了什么
想要了解SparkPlan到底做了什么,我们通过查看其方法就可以得到。SparkPlan类的主要方法有:
a. 计算相关
final def execute(): RDD[InternalRow]; // 最终委托给doExecute()方法
protected def doExecute(): RDD[InternalRow];
final def executeBroadcast[T](): broadcast.Broadcast[T]; // 最终委托给doExecuteBroadcast()方法
protected[sql] def doExecuteBroadcast[T](): broadcast.Broadcast[T];
final def executeColumnar(): RDD[ColumnarBatch]
protected def doExecuteColumnar(): RDD[ColumnarBatch]
b. 分区与排序
// 分区,输入数据与输出数据的分区情况,以此来判断是否要进行shuffle
def outputPartitioning: Partitioning
def requiredChildDistribution: Seq[Distribution]
// 排序相关,输入数据与输出数据的排序规则
def outputOrdering: Seq[SortOrder]
def requiredChildOrdering: Seq[Seq[SortOrder]]
c. 其他方法
// 运行计算指标信息,进行监控等
def metrics: Map[String, SQLMetric]
def resetMetrics(): Unit
def longMetric(name: String): SQLMetric
总结:SparkPlan的作用主要有3点,
1. 描述当前数据怎么进行计算(算法)
2. 描述当前数据上下游分区、排序情况,来判断是否进行shuffle与排序
3. 描述当前计划的指标与元数据
2. SparkPlan如何生成
2.1 生成入口
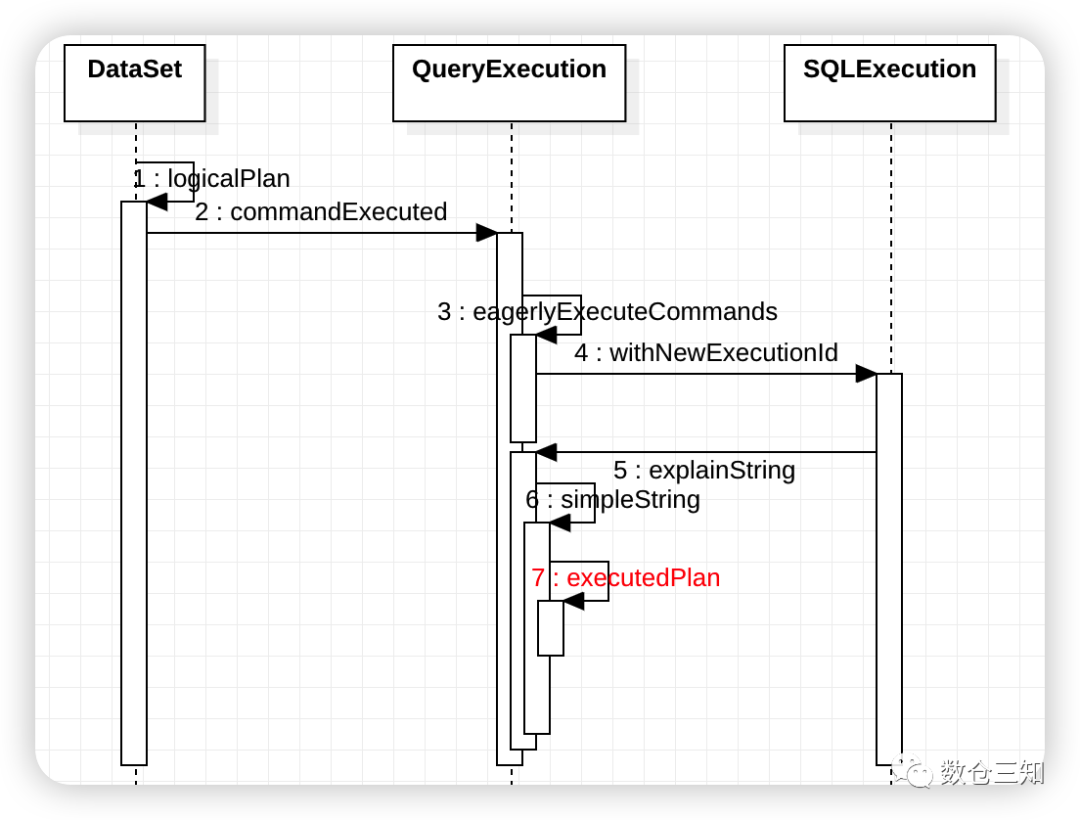
LogicalPlan生成SparkPlan是在QueryExecution#sparkPlan
属性懒加载时。不同类型的操作触发时机不同,分命令类和查询类。
命令类SQL/DSL(dataset 风格)在初始化Dataset的时候,执行Dataset.commandExecuted
属性初始化时触发sparkPlan初始化,具体流程如下图:
查询类SQL/DSL,SparkPlan初始化比较简单,在执行action操作的时候,调用DataSet的withAction
方法触发sparkPlan初始化。
// 查询类操作,DataSet.scala
private def withAction[U](name: String, qe: QueryExecution)(action: SparkPlan => U) = {
SQLExecution.withNewExecutionId(qe, Some(name)) {
QueryExecution.withInternalError(s"""The "$name" action failed.""") {
qe.executedPlan.resetMetrics() // 这里触发生成SparkPlan初始化
action(qe.executedPlan)
}
}
}
2.2 SparkPlan生成框架
SparkPlan的生成框架核心代码是在QueryPlanner.plan
方法。具体代码
def plan(plan: LogicalPlan): Iterator[PhysicalPlan] = {
val candidates = strategies.iterator.flatMap(_ (plan)) // 生成候选集
val plans = candidates.flatMap { candidate =>
val placeholders = collectPlaceholders(candidate)
if (placeholders.isEmpty) {
Iterator(candidate)
} else {
placeholders.iterator.foldLeft(Iterator(candidate)) {
case (candidatesWithPlaceholders, (placeholder, logicalPlan)) =>
val childPlans = this.plan(logicalPlan) // 递归自上而下生成候选集
candidatesWithPlaceholders.flatMap { candidateWithPlaceholders =>
childPlans.map { childPlan =>
candidateWithPlaceholders.transformUp {
case p if p.eq(placeholder) => childPlan // 自下而上进行替换
}
}
}
}
}
}
val pruned = prunePlans(plans)
assert(pruned.hasNext, s"No plan for $plan")
pruned
}
以select b,a from testdata2 where b<2
SQL为例,逐步分析生成SparkPlan过程。
先上结果,左边为优化后的LogicalPlan,右边为生成的SparkPlan。(添加Exec为了进行区分,实际上是没有)
+- Project [b#4, a#3] | Project(Exec) [b#4, a#3]
+- Filter (b#4 < 2) | +- Filter(Exec) (b#4 < 2)
+- SerializeFromObject [...] | +- SerializeFromObject(Exec) [...]
+- ExternalRDD [obj#2] | +- Scan(ExternalRDDScanExec)[obj#2]
先停下来思考下,如果这个执行框架是自己实现,该怎么样做呢?
spark中通过两个特殊的节点ReturnAnswer
和PlanLater
(占位符)实现替换逻辑。上述SQL转换过程如图(分析递归调用栈):
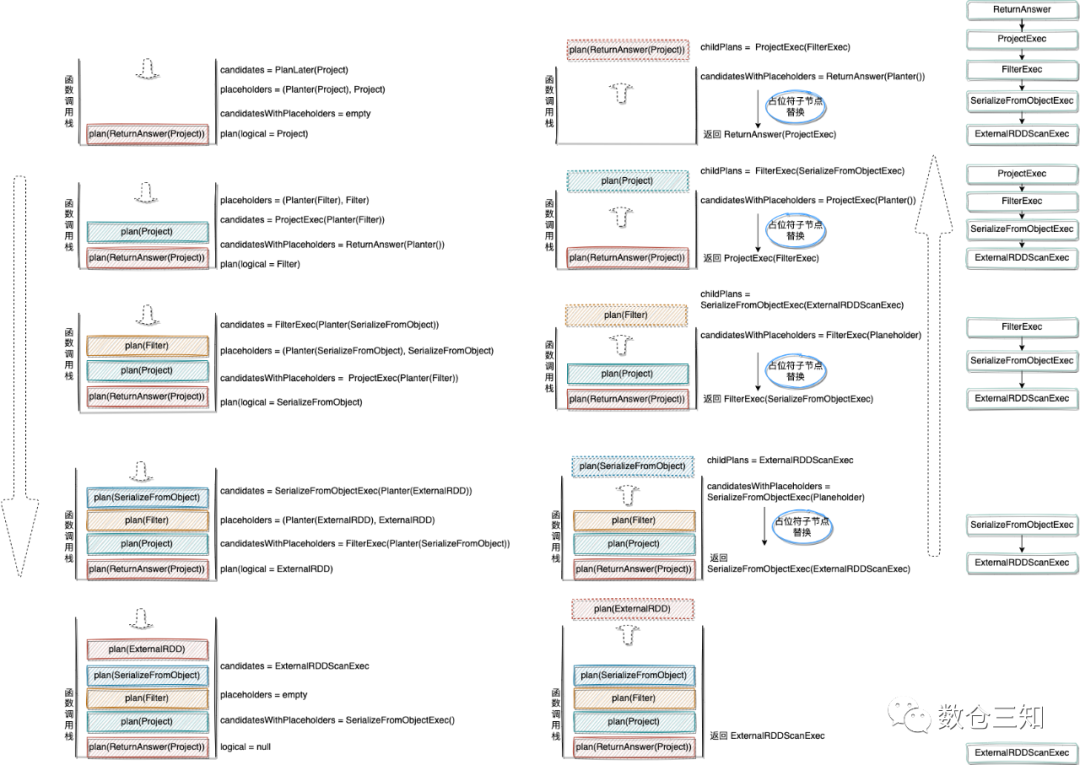
生成框架总结:自上而下生成SparkPlan,自下而上进行组装成树。
3. 小结
3.1 LogicalPlan生成SparkPlan
LogicalPlan生成SparkPlan本质上是由一棵树转换成另一棵树,自上而下通过strategies策略将当前LogicalPlan节点转换成SparkPlan,然后自下而上替换Planeholder(占位符)组装SparkPlan树。
LogicalPlan生成SparkPlan目的是补充计算要素,最终能够在框架中进行执行。
3.2 小知识点
1. scala的flatMap不是立即触发function逻辑,而是在调用其他方法(如:next,hasNext等)触发具体function逻辑执行
2. strategies包含的策略中
SpecialLimits
策略唯一处理ReturnAnswer
节点。3.
ReturnAnswer
节点是特殊的SparkPlan,表示根节点。
