




Dinosaurs还没有灭绝。当今许多顶级企业要么已经迁移到云计算,要么正在迁移过程中。作为其IT组织的一部分,通常拥有一个或多个大型关系数据库管理系统(RDBMS),它们是业务的核心。这些巨大的Dinosaurs通常是所有公司数据中最关键的任务,绝不会灭绝,但也可以作为完全迁移到云的锚。无论采用何种云策略,这些单片数据库对生态系统都至关重要,应该成为迁移策略的一部分,才能取得成功。
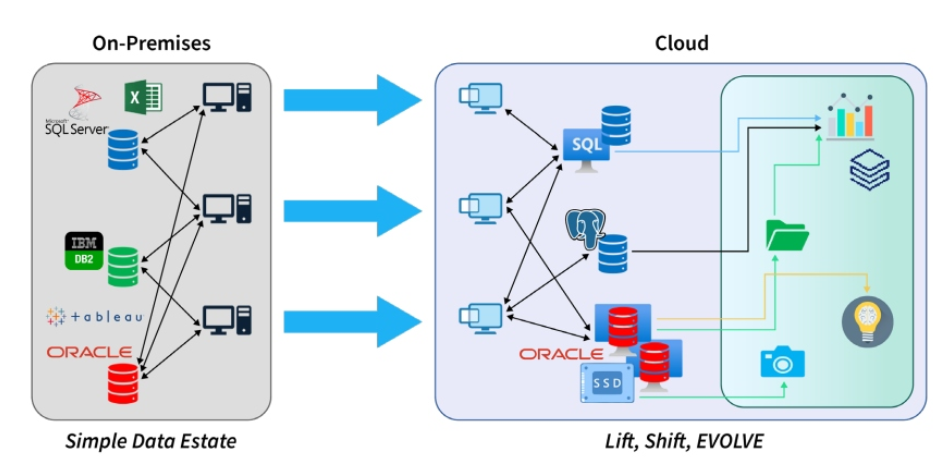
一个常见的错误是当团队试图分离连接到大型关系数据库的应用程序或较小的系统时,如图1所示。为了成功,关系数据库和所有连接的资源(无论它们是应用程序、辅助数据库、web服务器等)必须作为一个整体迁移。此外,这种成功需要一种策略,将大量关系数据、多个服务器、软件安装、作业和网络配置迁移为数据生态系统的一部分。
在经历了所有这些复杂性之后,网络是最后一个瓶颈,并且将是作为这项艰巨工作的一部分要克服的最大挑战之一。
大型关系数据库对云迁移的影响
历史上,关系系统至少有两层——关系数据库和应用程序或访问层。在更复杂的设计中,他们有多个应用程序服务器层、管理FTP访问的服务器、ETL/ELT、web服务器、中间件和相应的数据库,这些数据库要么提供给主关系系统,要么从主关系系统提供。一些平台(如Oracle)是围绕模式构建的,这导致了一个历史上规模较大的数据库,除非作为一个整体来考虑,否则很难迁移。
关系型Dinosaur的二分法
关系数据库Dinosaur的自然寿命是不断增长的,与较小的租赁体系结构相比,基于模式设计的RDBMS,每个数据库可以拥有TB甚至PB的数据。根据数据与其他系统的互连性,数据库大小可以创建自己的重力,将系统拉近源,以提供最佳用户体验。在云计算中,企业云覆盖的大量房地产进一步扩大了这种吸引力。
数据重力将把应用程序、连接的数据状态和资源拉向最大的数据体,通常是拥有关键业务数据的遗留关系数据库。
随着更多数据在应用程序和数据库之间传输到更大的关系系统(通过ETL/ELT处理或数据库链接),需要将所有涉及的系统紧密连接到更大关系体,以消除延迟。本质上,这就是数据重力。
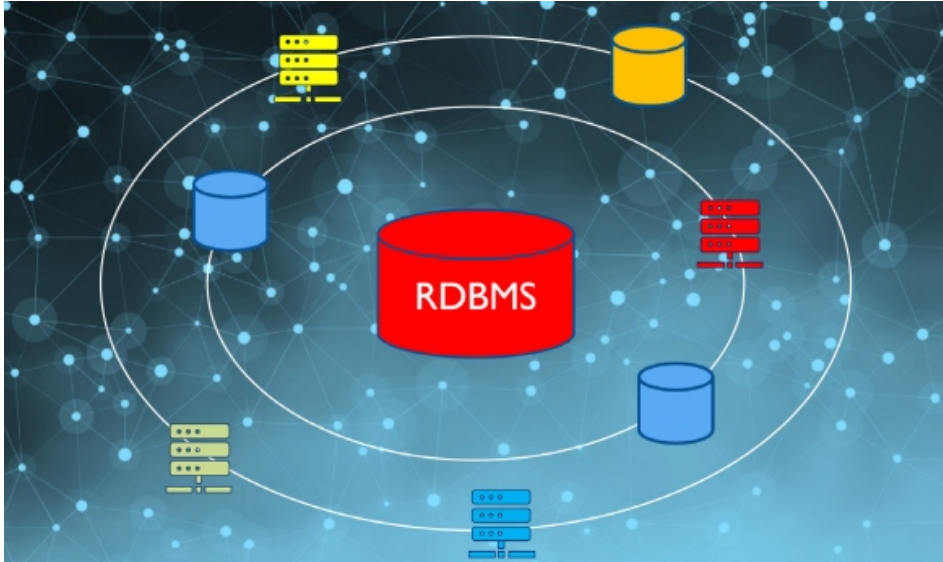
在为云构建RDBMS时,必须考虑数据重力。不仅对于基础设施的选择,甚至对于服务,云解决方案必须了解应用程序和数据库连接,以便部署它们以获得最佳性能。设计从最大的系统开始,然后辐射到最小的组件/服务,确保最具影响力的系统获得架构设计成功所需的关注。
云端全有或全无
当客户迁移到云时,他们可能已经尝试了一些迁移的系统,然后决定认真地将所有内容迁移到云。考虑到这一点,我们的目标是不在本地保留任何内容,这需要了解古老的关系系统以及将它们迁移到云的要求。
trickle-to-the-cloud最显著的缺点之一是,以前较小的云迁移项目可能会跨多个云转移各种工作负载,如果系统之间存在数据交互,则会导致发现多云依赖关系。网络成为我们的最后一个瓶颈,没有人发现如何克服它。使用对等网络和加速联网关闭数据中心位置可能有助于消除一些延迟,但如图3所示,在开发新的联网技术之前,这一挑战将继续存在。多云解决方案可以在云提供商之间提供数据的一些好处,但它们的性能永远不会像单个云解决方案那样。

克服跨云延迟问题的第一个目标是确定每天、每周等环境之间移动所需的数据。第二个目标应该围绕开发人员如何在本地执行工作并为云开发优化工作,尽可能消除多余的数据。始终选择简化在网络上拉取或推送数据时可能创建的任何其他IO。
应对所有跨云数据处理进行全面测试,以确保其能够满足业务需求,并且即使随着时间的推移,数据可能会增长,也可以接受。
基础架构即服务与平台或软件即服务
在调查云迁移后,平台即服务(PaaS)和软件即服务(SaaS)被反复宣传为所有本地技术的有吸引力的选项。用户听到他们可能能够在支持基础设施和平台上花费更少的钱,很激动,但他们忘记了他们想要转移到云计算的关系环境中已经积累了多少技术债务。
为什么大型RDBMS对Iaas的限制如此频繁?
一旦PaaS和SaaS明显要求用户放弃许多定制和功能,用户就会重新考虑基础设施即服务(IaaS)。这是由于多种因素的综合作用造成的,但大多数挑战都是围绕系统内置多年的复杂性和SaaS/PaaS产品缺乏特性而产生的。在决定云中可用的选项与移动到云中的数据状态时,请遵循以下简单的指导原则:
SaaS:
-
您正在进行一个新建项目
-
数据库层不需要自定义代码
-
该系统具有应用程序驱动开发和简单的数据存储需求
-
您使用的是较小的用户群和简单的恢复点目标(RPO)/恢复时间目标(RTO)
PaaS:
-
你正在进行一个项目
-
vCPU、内存和IO的资源使用很容易满足PaaS的限制
-
管理基础架构的IT资源很少,或者希望消除这一需求
-
数据库层实现的高级功能或自定义选项较少
IaaS:
-
您正在使用大型、TB PB级的关系系统
-
您需要与本地应用程序相同或相似的体系结构
-
您对资源有独特的需求—IO、vCPU和/或内存
-
您的工作负载要求非常高,RPO/RTO和开发需求非常复杂
如果需要使用IaaS,那么重要的是要认识到云供应商可以为一系列难以置信的工作负载提供解决方案,而关系工作负载是独特的,需要正确的IaaS解决方案来满足需求。
如何构建RDBMS迁移策略
迁移具有挑战性,做好准备是成功的最佳行动方案。具有多层系统的关系数据库,无论您使用的是过时的客户机/服务器体系结构还是大型机解决方案,都需要进行规划以确保成功。虽然每个项目都是独特的,但有些方面是普遍的,如果作为计划的一部分得到满足,将有助于确保成功的迁移。通用列表通常包括:
-
数据库大小和复杂性
-
数据负载和连接的生态系统
-
应用程序、作业、web和其他服务器
-
网络延迟
RDBMS中必须确定哪些重要指标?
大多数关系工作负载都占用大量资源,换句话说,它们对基础架构的要求比其他工作负载更高。但是,尽管我们可能非常关注CPU和内存,但关系工作负载,尤其是Oracle这样的工作负载,可能需要高IO存储解决方案。
大多数IO存储和基准将主要关注请求(IOP);然而,请求的大小可能会有所不同,这会使这些值受到市场营销利益的影响。根据我的经验,建议减少对IOP的关注,并确保所选解决方案(无论是围绕虚拟机还是存储IO限制)能够处理每秒兆字节(吞吐量)。
创建RDBMS复杂性的层次
随着云中服务、高可用性和备份的变化,围绕存储和解决方案的所有决策都必须关注RPO和RTO。还应考虑可能与RPO/RTO不同的任何所需客户正常运行时间SLA,因为服务可以捆绑到作为体系结构一部分选择的存储解决方案中。
确保所有架构决策都基于云架构应如何针对推荐实践进行设计,而不仅仅是复制客户在其本地架构中构建的内容。这是云中常见的错误,造成漏洞和冗余。
一个好的起点是解除和转移关系数据库工作负载,这将消除内置于现有本地硬件中的任何基础设施债务。如果不考虑这个硬件,所有的重点都放在关系工作负载上,那么可以根据需要设计一个新的体系结构。
冲洗并重复至成功
由于大多数数据生态系统不仅需要迁移主数据库和连接的系统,而且还需要复制非生产拷贝,因此构建一个可以简化、自动化并作为DevOps实践的一部分进行部署的框架非常重要。每次在没有框架的情况下按顺序执行所涉及的所有操作将非常耗时,并且容易出错。
构建框架
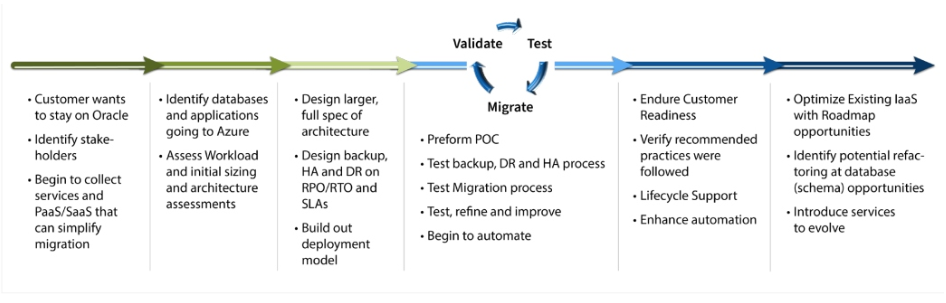
构建云迁移框架首先要记录将关系系统部署到云端所需的内容。开始的大纲可以类似于图4所示的高级示例,并且可以构建为完成迁移项目计划。
一旦构建完成,请使用工具和脚本将其尽可能自动化,同时包含足够的灵活性,以便在未来的许多系统和体系结构中重用。
确保脚本语言和工具可以像云迁移那样扩展,并验证它们可以管理基础设施、关系系统和数据。随着问题的出现和解决,将其记录下来,并确保这些问题不会在未来重复出现,从而使效率成为云迁移策略的一部分。
结论
大型关系数据库被视为第一个从技术领域消失的数据库,就像一颗瞄准Dinosaurs的小行星,然而,这些古老的系统往往是许多云迁移的中心点。一旦迁移到云端,可能会提出多个项目来现代化和消除这些Dinosaurs,但更常见的情况是,它们的骨骼成为新应用程序策略的基础,数据驻留在与本地相同的关系系统中。由于资源有限、缺乏投资回报率或现代化的工作量,现代化往往消除了改变系统的紧迫性。
随着企业继续向云端转移,由于这些关系系统在数据产业中仍扮演着重要角色,因此有必要采取建议的做法,将大型RDBMS作为这些数据中心和数据产业的一部分进行移动。
原文标题:Migrate RDBMS Dinosaurs to the Cloud
原文作者:Kellyn Gorman
原文链接:https://dzone.com/articles/migrate-rdbms-dinosaurs-to-the-cloud




