




一、概述
当我们处理较大的数据量的时候,我们下意识的就使用for循环遍历去处理数据,但是这样并不能很好的应用我们设备的cpu资源,速度会很慢,在jdk 1.7,引入了fork/join,我们使用fork/join可以有效提升计算速度。在jdk 1.8,引入了并行流,我们使用并行流处理数据,计算速度进一步得到了大幅度的提升。
二、面试:简述并行流
-
fork/join
【什么是fork/join】
ForkJoin出现在JDK1.7,它的作用简单来说就是
并行执行任务,通过把大任务拆分为小任务的思想,在计算大数量时,提高效率【作用】
并行执行任务,提高效率
更能充分的利用到cpu性能(各个CPU的利用率基本保持一致)【流程原理】
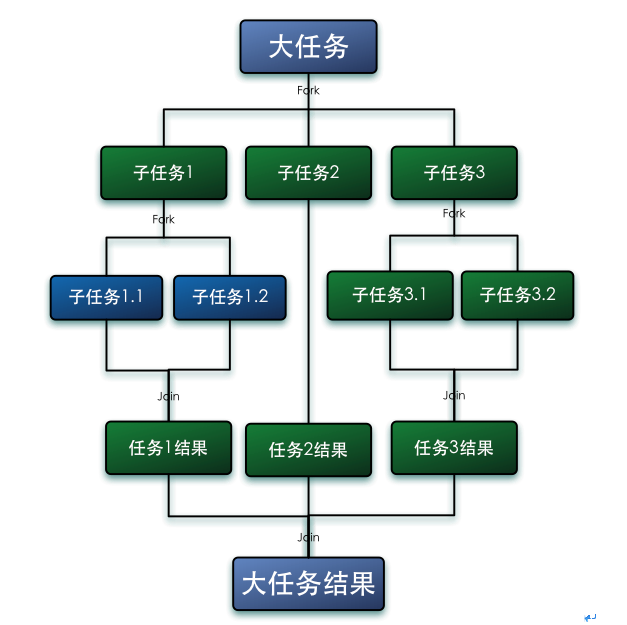
第一步:Fork(将任务拆分为多个子任务「
双端队列」,分别调用多个CPU去处理)第二步:Join(将多个子任务结果合并成最终结果)
【特点】
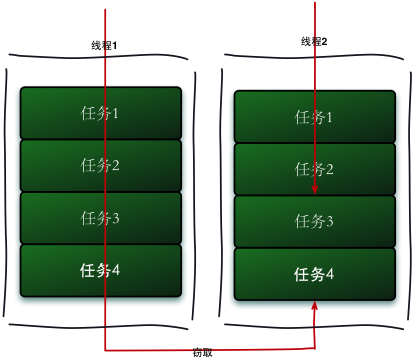
工作窃取机制:子任务都是维护的双端队列,某一线程执行完后,会帮助别的线程执行后续的任务(假设子任务A执行一半时,子任务B已经执行完毕了,B会窃取一些A的任务,来帮助A执行未完成的任务。而给A窃取B提供保证的就是
双端队列,每个子任务都是个双端队列)
-
fork/join与并行流的区别
fork/join是jdb 1.7提供的,并行流是jdk 1.8提供的,并行流是基于fork/join原理实现的
-
多线程与并行流的区别
【多线程】当一个线程阻塞,会造成别的线程执行完后,处于空闲状态
【并行流】某一线程执行完后,会帮助别的线程执行任务
计算密集型使用并行流,并行流比多线程更能充分利用CPU,但是IO密集型操作的并行流效率不高 -
并行流使用注意
1、使用.parallelStream()之后,在接下来的管道中做任何业务逻辑都需要确保线程安全
2、有i/o操作的一定不要使用并行流,有线程休眠的也一定不要使用并行流,因为所有使用并行流parallerStream的地方都是使用同一个Fork-Join线程池,而线程池线程数默认仅为cpu的核心数,如果线程都去用来跑IO密集型的,会造成全局jvm进程中使用parallerStream的地方全部阻塞
三、处理10亿数据
3.1、Fork/Join自定义类
Fork/Join需要自定义类,继承RecursiveTask/RecursiveAction,重写compute()方法,实现Fork和Join的逻辑
public class ForkJoinDemo extends RecursiveTask<Long> {
/**
* 累加起始值
*/
private final Long start;
/**
* 累加结束值
*/
private final Long end;
public ForkJoinDemo(Long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// 该值用来确定最小子任务,当递归拆分还剩10000时,不再拆分,否则无限拆分会报AQS / 栈溢出StackOverflowError
long temp = 10000L;
if (end - start < temp) {
long sum = 0L;
for (Long i = start; i <= end ; i++) {
sum += i;
}
return sum;
} else {
// 中间值,递归拆分
long middle = (start + end) / 2;
// fork:将任务拆分并压入线程队列
ForkJoinDemo task1 = new ForkJoinDemo(start, middle);
ForkJoinDemo task2 = new ForkJoinDemo(middle + 1, end);
/*
* 方式一:
* task1.fork();
* task2.fork();
* return task2.join() + task1.join();
*
* 方式二:
* invokeAll(task1, task2);
* return task1.join() + task2.join();
*
* 方式三:
* task1.fork();
* return task2.compute() + task1.join();
*/
invokeAll(task1, task2);
// join:结果合并
return task1.join() + task2.join();
}
}
}
复制关于性能问题
使用上述代码中提供的三种方式(推荐使用第二种),第一种里面
return task2.join() + task1.join(); 和 return task1.join() + task2.join();
是不一样的,return task1.join() + task2.join();效率较低,注意顺序。
Java的Fork/Join任务,你写对了吗?
注意,在使用Fork/Join时遇到的如下两个问题
1、java.util.concurrent.ExecutionException:java.lang.StackOverflowError。
【原因】因为ForkJoin不会对堆栈进行控制,编写代码时注意方法递归不能超过jvm的内存,如果必要需要调整jvm的内存:在Eclipse中JDK的配置中加上 -XX:MaxDirectMemorySize=128(默认是64M)。改为128后不报栈溢出,但是报下一个错。
2、java.lang.NoClassDefFoundError: Could not initialize class java.util.concurrent.locks.AbstractQueuedSynchronizer$Node。
【原因】子任务的处理长度不平衡。我们需要对原来的长度进行计算处理。
复制3.2、3种方式处理数据
使用For循环、Fork/Join、并行流来实现10亿数据的累加
public class CalculationDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Long startValue = 0L;
Long endValue = 10_0000_0000L;
test1(startValue, endValue); // 4236ms
test2(startValue, endValue); // 2410
test3(startValue, endValue); // 380ms
}
/**
* For循环
*/
public static void test1(Long startValue, Long endValue){
long sum = 0L;
long startTime = System.currentTimeMillis();
for (Long i = startValue; i <= endValue ; i++) {
sum += i;
}
long endTime = System.currentTimeMillis();
System.out.println("sum=" + sum + " 时间: " + (endTime - startTime));
}
/**
* 使用Fork/Join(jdk 1.7)
*/
public static void test2(Long startValue, Long endValue) throws ExecutionException, InterruptedException {
long startTime = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Long> task = new ForkJoinDemo(startValue, endValue);
//提交任务
ForkJoinTask<Long> submit = forkJoinPool.submit(task);
Long sum = submit.get();
long endTime = System.currentTimeMillis();
System.out.println("sum="+ sum + "时间: " + (endTime - startTime));
}
/**
* 使用并行流(jdk 1.8)
*/
public static void test3(Long startValue, Long endValue){
long startTime = System.currentTimeMillis();
long sum = LongStream.rangeClosed(startValue, endValue).parallel().reduce(0, Long::sum);
long endTime = System.currentTimeMillis();
System.out.println("sum=" + sum + "时间: " + (endTime - startTime));
}
}
复制可以看到并行流相较于普通的for循环,效率提升了10倍不止!
