




对于一个复制层次结构,一个数据中心的查询延迟比其他地方大,但仅在高百分位。这会影响生产,并且流量正在从该数据中心转移以保护生产。
当 P50 和 P90 看起来正常,但 P99 和 P99.9 不正常时,数据库运行正常,只有一些查询运行缓慢。最初的猜测是“对于某些查询,计划已经改变,但仅限于该数据中心。”
但首先让我们看一下数据库大小和架构。
一个小型数据库
有问题的模式包含变更数据捕获过程的元数据,而且数量不多。
# du -sh * 0 coredumps 5.6G data 704M log 0 tmp # du -sh data/theschema 93M data/theschema复制
在内存中:

即使允许数据库增长到 71.8 G 的 VIRT(虚拟内存大小),mysqld 进程的 RES(驻留集大小)也只有 5.9 GB。
目前这是在裸机刀片上运行的,而且这些刀片不会比这更小。在虚拟机中,它可以小到 1/4 刀片 —— 但数据库实例具有固定的开销,并且变得更小几乎没有意义。
在任何情况下,这都会耗尽内存,即使托管在 iPhone 上也会如此。即使有错误的查询,也不能进行磁盘扫描。即使使用内存扫描,这么小的东西也不会耗尽 CPU 或在内存中扫描很长时间。这里肯定有什么东西闻起来很有趣。
[information_schema]> select table_name, table_rows from tables where table_schema = 'schemaregistry' order by table_rows desc; +--------------------+------------+ | TABLE_NAME | TABLE_ROWS | +--------------------+------------+ | table_01 | 14376 | | table_02 | 9510 | | table_03 | 3079 | | table_04 | 84 | | table_05 | 0 | | db_waypoint | 0 | +--------------------+------------+ 6 rows in set (0.00 sec)复制
扫描慢查询
我们用 performance_schema 直接使用来询问已经看到的缓慢查询的统计信息。
[performance_schema]> select -> user, -> event_name, -> count_star, -> avg_timer_wait/1000000000 as avg_ms -> from events_statements_summary_by_user_by_event_name -> where user = 'production_username' -> and event_name like 'statement/sql/%' and count_star > 0; +----------------------+-----------------------------+------------+--------+ | user | event_name | count_star | avg_ms | +----------------------+-----------------------------+------------+--------+ | production_username | statement/sql/select | 42121722 | 0.2913 | | production_username | statement/sql/set_option | 270284 | 0.0708 | | production_username | statement/sql/show_warnings | 67571 | 0.0498 | +----------------------+-----------------------------+------------+--------+ 3 rows in set (0.01 sec)复制
P_S不打算由人直接使用。这些表针对快速数据收集进行了优化。数据在读取期间没有锁定,因为收集速度不慢,时间以 PicoSeconds (1/10^12) 报告以避免写入时的任何 DIV 指令,并且缓冲区的大小有限,因此如果某些操作是垃圾邮件 P_S,数据会丢失,但是服务器不会减慢或丢失内存。
因此,我们除以 10^9 以获得平均语句运行时间,并且我们报告自服务器启动(或表截断)以来为任何语句收集的任何语句统计信息。事实证明,生产用户只运行了选择语句、设置语句和显示警告命令。
虽然平均值看起来不错,但最大值不是:
[performance_schema]> select -> event_name, -> count_star, -> avg_timer_wait/1000000000 as avg_ms, -> max_timer_wait/1000000000 as max_ms -> from events_statements_summary_by_user_by_event_name -> where user = 'production_username' -> and event_name like 'statement/sql/%' and count_star > 0; +-----------------------------+------------+--------+------------+ | event_name | count_star | avg_ms | max_ms | +-----------------------------+------------+--------+------------+ | statement/sql/select | 42121722 | 0.2913 | 14934.0024 | | statement/sql/set_option | 270284 | 0.0708 | 1.2732 | | statement/sql/show_warnings | 67571 | 0.0498 | 0.9574 | +-----------------------------+------------+--------+------------+ 3 rows in set (0.00 sec)复制
因此,有一个 select 语句在没有超过 15k 行的表的数据库上运行了惊人的 14 秒。
Vividcortex 又名 SolarWinds DPM
我们将此层次结构加载到 Vividcortex,这是一个从数据库收集性能数据的监视器,并允许查看执行缓慢的特定查询。它还可以帮助确定可能的改进。
用于流媒体的 Vividcortex 库存。通常 Vividcortex 不会在所有实例上运行,而是在主副本和一个池化副本上运行。不过,我们希望在法兰克福有一个特定的池复制品,所以需要一个 6000 号的东西。
我们正常的 Vividcortex 载入会在主副本和一个池副本上安装探针,因为没有必要用来自所有生产机器的所有查询来压倒收集接口。一个样本就可以了。
但是,在这种情况下,我们希望在特定位置有一个副本:只有一个数据中心出现异常行为,因此我们希望在该位置再增加一台机器。这需要一些定制的木偶艺术,但它奏效了。但是,即便如此,我们也没有得到特别有趣的查询:

我们得到查询计数和平均延迟。但是从计数和平均值这个词我们已经可以看出这没有用:我们本来希望看到高百分位数。此外,这些查询都是无趣的。
现在,我们相信大多数查询都很好,只有一些大部分情况良好的查询实例花费了意想不到的时间。我们希望看到这些。
我们已经可以看到,这里 VividCortex 的默认视图没有帮助,快速浏览用户界面很快就会发现,这个工具对于我们的特定搜索可能不是最有用的。
我们回去P_S手工制作我们的东西。
掠夺P_S
让我们看看菜单上有什么:
[performance_schema]> show tables like '%statement%'; +----------------------------------------------------+ | Tables_in_performance_schema (%statement%) | +----------------------------------------------------+ | events_statements_current | | events_statements_histogram_by_digest | | events_statements_histogram_global | | events_statements_history | | events_statements_history_long | | events_statements_summary_by_account_by_event_name | | events_statements_summary_by_digest | | events_statements_summary_by_host_by_event_name | | events_statements_summary_by_program | | events_statements_summary_by_thread_by_event_name | | events_statements_summary_by_user_by_event_name | | events_statements_summary_global_by_event_name | | prepared_statements_instances | +----------------------------------------------------+ 13 rows in set (0.00 sec)复制
我不认识你,但events_statements_summary_by_digest我觉得很好吃。里边啥啊?
[performance_schema]> desc events_statements_summary_by_digest; +-----------------------------+-----------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-----------------------------+-----------------+------+-----+---------+-------+ | SCHEMA_NAME | varchar(64) | YES | MUL | NULL | | | DIGEST | varchar(64) | YES | | NULL | | | DIGEST_TEXT | longtext | YES | | NULL | | | COUNT_STAR | bigint unsigned | NO | | NULL | | | SUM_TIMER_WAIT | bigint unsigned | NO | | NULL | | | MIN_TIMER_WAIT | bigint unsigned | NO | | NULL | | | AVG_TIMER_WAIT | bigint unsigned | NO | | NULL | | | MAX_TIMER_WAIT | bigint unsigned | NO | | NULL | | | SUM_LOCK_TIME | bigint unsigned | NO | | NULL | | | SUM_ERRORS | bigint unsigned | NO | | NULL | | | SUM_WARNINGS | bigint unsigned | NO | | NULL | | | SUM_ROWS_AFFECTED | bigint unsigned | NO | | NULL | | | SUM_ROWS_SENT | bigint unsigned | NO | | NULL | | | SUM_ROWS_EXAMINED | bigint unsigned | NO | | NULL | | | SUM_CREATED_TMP_DISK_TABLES | bigint unsigned | NO | | NULL | | | SUM_CREATED_TMP_TABLES | bigint unsigned | NO | | NULL | | | SUM_SELECT_FULL_JOIN | bigint unsigned | NO | | NULL | | | SUM_SELECT_FULL_RANGE_JOIN | bigint unsigned | NO | | NULL | | | SUM_SELECT_RANGE | bigint unsigned | NO | | NULL | | | SUM_SELECT_RANGE_CHECK | bigint unsigned | NO | | NULL | | | SUM_SELECT_SCAN | bigint unsigned | NO | | NULL | | | SUM_SORT_MERGE_PASSES | bigint unsigned | NO | | NULL | | | SUM_SORT_RANGE | bigint unsigned | NO | | NULL | | | SUM_SORT_ROWS | bigint unsigned | NO | | NULL | | | SUM_SORT_SCAN | bigint unsigned | NO | | NULL | | | SUM_NO_INDEX_USED | bigint unsigned | NO | | NULL | | | SUM_NO_GOOD_INDEX_USED | bigint unsigned | NO | | NULL | | | SUM_CPU_TIME | bigint unsigned | NO | | NULL | | | COUNT_SECONDARY | bigint unsigned | NO | | NULL | | | FIRST_SEEN | timestamp(6) | NO | | NULL | | | LAST_SEEN | timestamp(6) | NO | | NULL | | | QUANTILE_95 | bigint unsigned | NO | | NULL | | | QUANTILE_99 | bigint unsigned | NO | | NULL | | | QUANTILE_999 | bigint unsigned | NO | | NULL | | | QUERY_SAMPLE_TEXT | longtext | YES | | NULL | | | QUERY_SAMPLE_SEEN | timestamp(6) | NO | | NULL | | | QUERY_SAMPLE_TIMER_WAIT | bigint unsigned | NO | | NULL | | +-----------------------------+-----------------+------+-----+---------+-------+ 37 rows in set (0.00 sec)复制
嗯?什么?P_S的结构
在这一点上,停下来建立一些关于P_S. P_S收集有关语句执行和服务器性能的数据。
[performance_schema]> show tables like 'setup%'; +---------------------------------------+ | Tables_in_performance_schema (setup%) | +---------------------------------------+ | setup_actors | | setup_consumers | | setup_instruments | | setup_objects | | setup_threads | +---------------------------------------+复制
服务器用于收集,数据源称为工具。
我们可以要求工具为某些监控用户、某些参与者收集或不收集数据。我们也可以要求仪器忽略某些表、模式或其他事物、某些对象。同样,对于某些线程也是如此。
收集的数据存储在预先分配的环形缓冲区中,或添加到某些聚合中。所有这些东西都是消费者。
配置通过上面的设置表进行,这些设置表设置了从仪器通过过滤维度到消费者的数据流。
事件数据收集发生在事件表中,在层次结构中,从事务到组成事务的单个语句,再到语句的执行阶段、阶段、等待(主要用于 IO 或锁)。这些东西嵌套,但不一定是 1:1 的——例如,一条语句可以包含等待或其他语句。
root@streamingdb-6001 [performance_schema]> show tables like 'event%current'; +----------------------------------------------+ | Tables_in_performance_schema (event%current) | +----------------------------------------------+ | events_stages_current | | events_statements_current | | events_transactions_current | | events_waits_current | +----------------------------------------------+ 4 rows in set (0.00 sec)复制
对于这些事件中的每一个,我们有 _current, _history, _history_long表。例如,events_statements_current 包括每个活动连接的一个条目,events_statements_history 包括每个活动连接的最后几条语句,以及 events_statements_history_long 包括所有连接的最后几千条语句。
还有其他集合,关于服务器的其他方面,以及更通用的语句聚合,摘要。
查询和查询摘要
为了能够聚合语句,有语句的概念digest_text,最终是digest从摘要文本生成的哈希数。
因此,诸如
select id from atable where id in ( 1, 2, 3) seLect id FROM atable where id IN (92929, 29292, 17654, 363562);复制
应该被认为在一个聚合中是等效的。这是通过从解析树中解析语句来完成的,这消除了关键字中的所有间距和字母大小写差异。在此期间,所有常量和常量列表分别被替换为?或’?’。
上述两个语句的摘要文本变为
select id from atable where id in ( ? )复制
然后可以通过在摘要文本上运行哈希函数来生成摘要。
缺点是无法用EXPLAIN命令解释摘要,因此我们需要确保还保留有代表性的可解释版本的查询。
获取一些数据
在我们的例子中,events_statements_summary_by_digest这正是我们想要的。所以我们截断集合,稍等片刻,然后询问。结果是不可能的:
[performance_schema]> truncate events_statements_summary_by_digest; ... [performance_schema]> select -> count_star, avg_timer_wait/1000000000 as avg_ms, -> QUANTILE_95/1000000000 as q95_ms, -> first_seen, -> last_seen, -> query_sample_text -> from events_statements_summary_by_digest -> where schema_name = 'schemaregistry' -> and QUANTILE_95/1000000000 > 0.1 -> order by QUANTILE_95/1000000000 asc \G *************************** 1. row *************************** count_star: 21 avg_ms: 0.0782 q95_ms: 0.1202 first_seen: 2022-09-19 14:35:28.885824 last_seen: 2022-09-19 14:38:06.110111 query_sample_text: SELECT @@session.autocommit *************************** 2. row *************************** count_star: 21 avg_ms: 0.0902 q95_ms: 0.1514 first_seen: 2022-09-19 14:35:28.886215 last_seen: 2022-09-19 14:38:06.110382 query_sample_text: SET sql_mode='STRICT_ALL_TABLES,NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES'复制
所以我们有完整的内部配置命令,有时执行时间超过 0.1 毫秒。我们还有其他一些简单查询的实例,有时运行需要 14 秒,比平均速度快 1000 倍甚至更多。
接着…
是的,就我的挖掘而言,当一位同事插话时,指着我所在机器的机器仪表板。
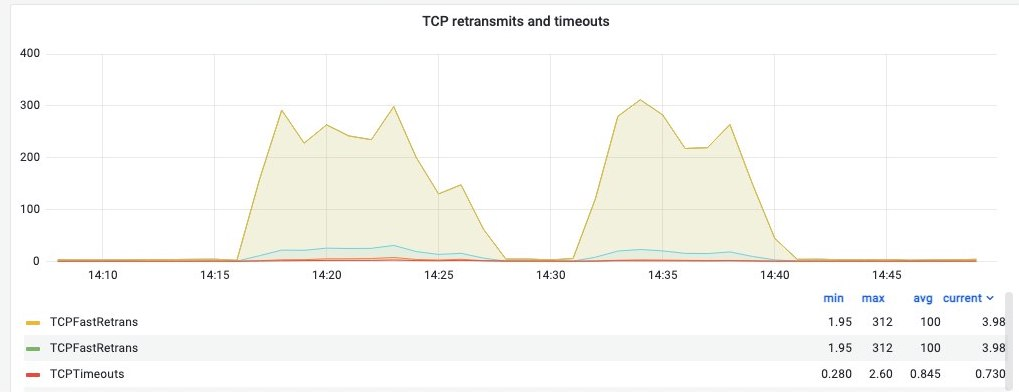
病态的网络接口肯定会影响系统性能。
该数据中心位置的池化副本中的其中一台机器显示出大量的网络重传,并且该机器可能需要数据中心运营工程师的一些关爱。
我们通过将盒子移除并重新添加到池中进行了一些实验,果然:一旦被测系统在池中,延迟就不再值得生产。
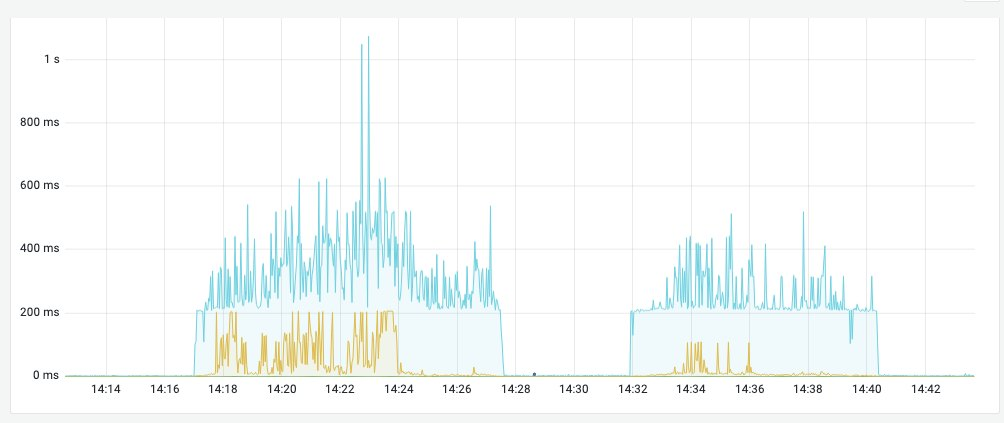
标题栏中的图像:在副本池中使用和不使用损坏框的最终用户体验。一个坏盒子会破坏所有用户的体验。
因此,根本原因不是某个查询执行不良的实例,而是所有查询在池的一个盒子上的一个位置执行不良。平均查询延迟,甚至 P90 看起来都不错,但 P99 和 P99.9 就完蛋了。
该盒子已从池中移除,并已安排更换。破损的盒子将获得一张 DCOE 罚单。
原文标题:MySQL: Sometimes it is not the database
原文作者:KRISTIAN K?HNTOPP
原文地址:https://blog.koehntopp.info/2022/09/sometimes19/-it-is-not-the-database.html
