




在这篇文章中,我们将分享如何使用Amazon Kinesis集成和Amazon DynamoDB Time to Live (TTL)特性来设计数据归档。归档旧数据有助于降低成本,并满足管理数据保留或删除策略的监管要求。用于DynamoDB的Amazon Kinesis数据流捕获DynamoDB表中的项目级修改,并将它们复制到一个Kinesis数据流。
DynamoDB TTL是免费提供的,可以用来定义何时从表中自动删除过期项。TTL消除了扫描表和删除不想保留的项的复杂性和成本。这为您节省了吞吐量和存储方面的资金。
解决方案概述
客户经常使用DynamoDB存储时间序列数据,如网页点击流数据或来自传感器和连接设备的物联网数据。许多客户希望将它们存档,而不是删除较老的、访问频率较低的项目。
该解决方案使用DynamoDB TTL自动从DynamoDB表中删除过期项,并使用Kinesis Streams捕获过期项。当新项目被添加到Kinesis流中时(也就是说,当TTL删除较旧的项目时),它们被发送到Amazon Kinesis Data Firehose交付流。kineesis Data Firehose提供了一个简单的、完全管理的解决方案,将数据加载到Amazon simple Storage Service (Amazon S3)中进行长期归档。
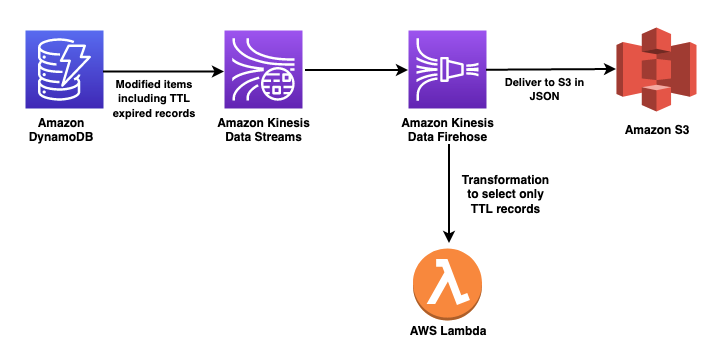
以下步骤是该解决方案的高级概述。上面的图1说明了这个过程。
-
使用将存储TTL时间戳的属性启用DynamoDB TTL。
-
为DynamoDB启用动态数据流。这将数据输入到一个Kinesis数据流中,以便进行进一步的归档处理。
-
连接Kinesis数据消防软管到Kinesis数据流使用:
-
一个AWS Lambda函数,执行数据转换以选择TTL记录。
-
用于存储所选TTL记录的S3桶。
-
-
验证TTL处理的记录的过期和传输到S3桶。
先决条件
本文假设您已经有了一个DynamoDB表和该表上的一个属性,可以将其用作TTL的时间戳。
使用DynamoDB TTL
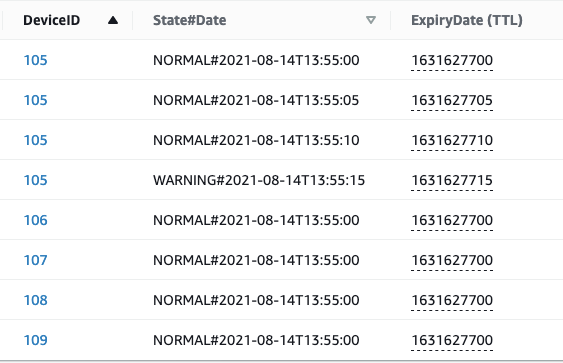
在这个解决方案中,假设您有一个DynamoDB表,它每5秒从IoT设备接收一个数据流。数据存储在一个DynamoDB表中,DeviceID作为分区键。排序键是状态和日期的组合,以支持必须返回在特定状态的时间范围内排序的项的访问模式。
插入项时,添加一个具有插入日期后一个月的纪元时间戳值的ExpiryDate属性。使用这个时间戳,当ExpiryDate时间戳在过去时,DynamoDB TTL从表中删除一个项。这种删除并不保证在时间戳过期时发生,但通常在48小时内完成。
在接下来的图2所示的示例中,我们在每个带有epoch格式时间戳的项目中都放入了一个ExpiryDate属性。在本例中,从插入数据开始的一个月。因此,当我们将此属性用于TTL时,这些项目将在一个月后到期。
配置DynamoDB TTL
-
在DynamoDB的AWS管理控制台中,从左侧导航窗格中选择表,然后选择要启用TTL的表。
-
在“DeviceLog日志管理系统”界面中,选择“附加设置”页签

-
向下滚动到Time to Live (TTL),并在右上角选择Enable

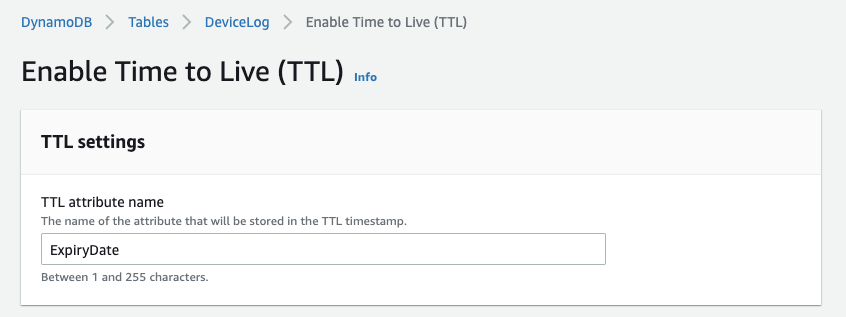
4.在“TTL属性名称”中,输入将存储在TTL时间戳中的属性名称
建立一个Kinesis数据流
DynamoDB的Kinesis数据流捕获表中的项目级更改,并将更改复制到一个Kinesis数据流中。
为了建立一个Kinesis数据流
-
返回到DynamoDB控制台中的表,选择DeviceLog表。
-
在“DeviceLog日志管理系统表属性”界面中,选择“导出和流”页签。
-
在Amazon kineesis数据流详细信息下,选择“启用”。
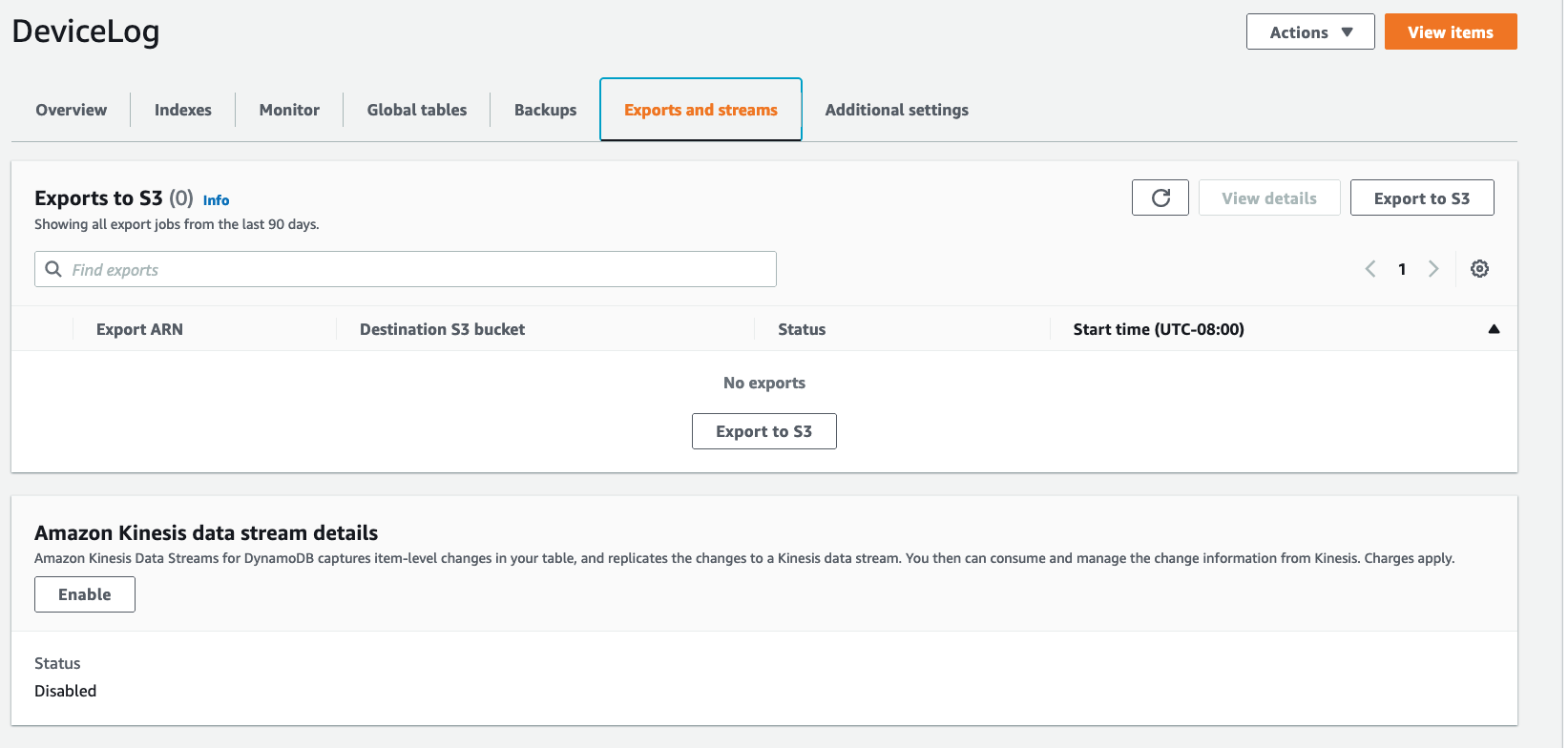
- 可以选择一个现有的Destination Kinesis数据流,也可以创建一个新的。对于本例,选择Create new创建一个新流,并将其命名为DevicelogDataStream。
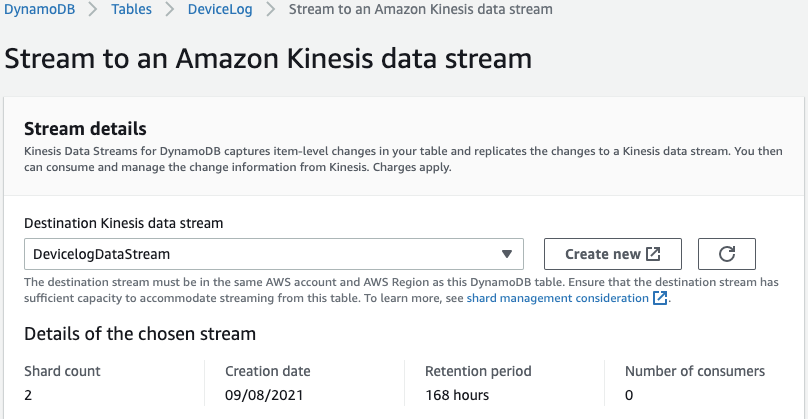
- 在“数据流配置”中,在“数据流容量”下,选择“按需”。这种容量模式不需要为流数据提供和管理容量。使用动态数据流按需自动扩展容量,以响应不同的数据流量。
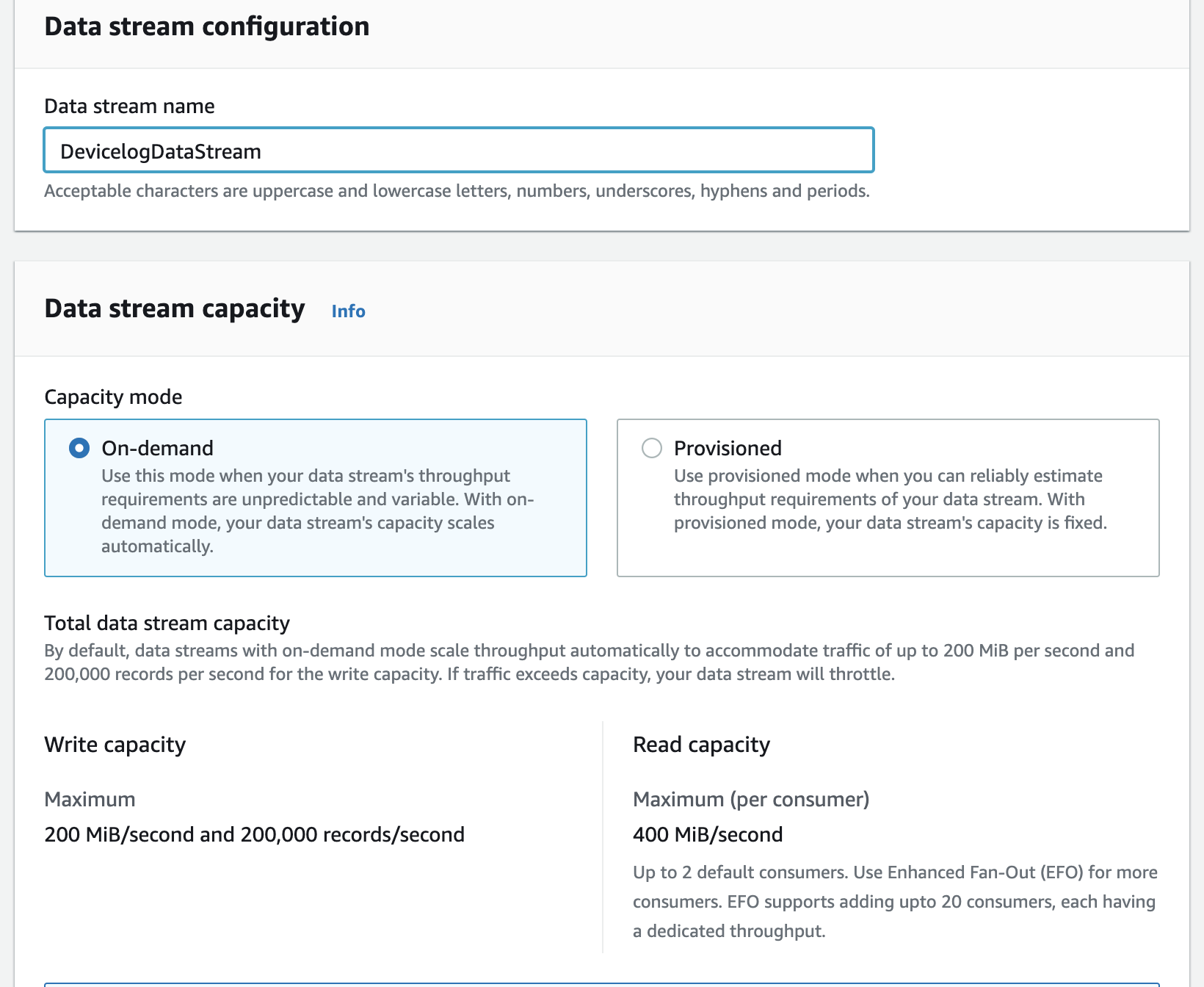
注意: 如果您希望在供应模式下使用Kinesis数据流,请确保目标流有足够的容量。如果没有足够的容量,从DynamoDB到Kinesis数据流的写入将被限制,进入流的数据的复制延迟将会增加。有关更多信息,请参见重新分片流。
创建Lambda函数来选择TTL记录
动态流将持续捕获项目,因为它们在DynamoDB中被修改,包括应用程序完成的项目更新。该解决方案使用Lambda函数只选择被DynamoDB TTL进程过期的项。过期后被TTL进程删除的项具有userIdentity属性。principalId:“dynamodb.amazonaws.com”。
来创建一个Lambda函数
-
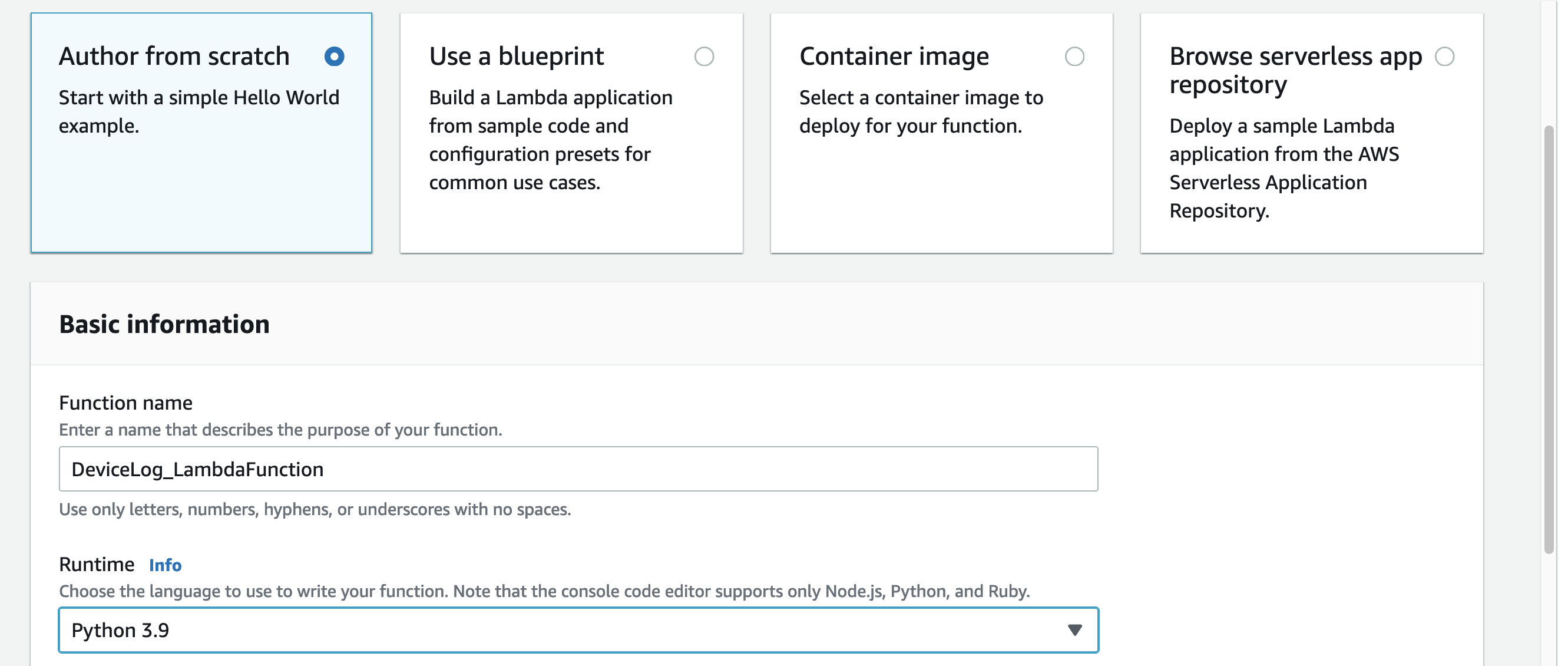
在Lambda控制台中,从左侧导航窗格中选择Dashboard,然后选择Create function。
-
从头开始选择Author。输入一个函数名,然后在Runtime下,选择Python 3.9
-
选择Code选项卡并将以下代码片段粘贴到lambda_function中。该函数选择被DynamoDB TTL进程过期的项。
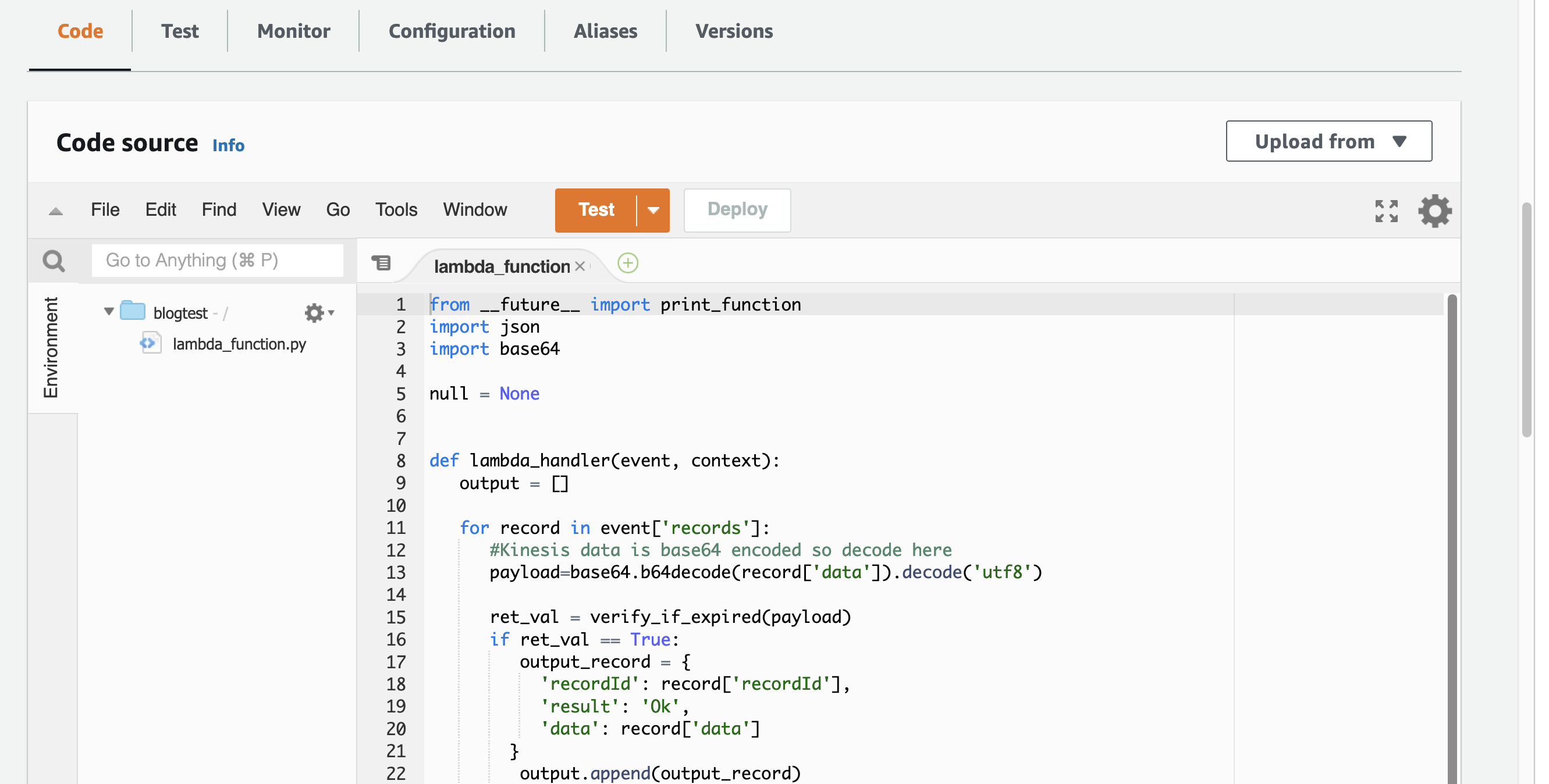
Lambda函数选择TTL记录:
from __future__ import print_function
import json
import base64
null = None
def lambda_handler(event, context):
output = []
for record in event['records']:
#Kinesis data is base64 encoded so decode here
payload=base64.b64decode(record['data']).decode('utf8')
ret_val = verify_if_expired(payload)
if ret_val == True:
output_record = {
'recordId': record['recordId'],
'result': 'Ok',
'data': record['data']
}
output.append(output_record)
else:
output_record = {
'recordId': record['recordId'],
'result': 'Dropped',
'data': null
}
output.append(output_record)
return {'records': output}
def verify_if_expired(payload):
try:
parsed_json = json.loads(payload)
if str(parsed_json["eventName"]).upper() == "REMOVE":
if parsed_json["userIdentity"]["principalId"] == "dynamodb.amazonaws.com":
return True
except Exception as e:
print(e)
return False
复制建立一个运动数据消防软管传输流
动态数据Firehose将数据从流源加载到数据存储中。Data Firehose是一个完全受管理的服务,它自动伸缩以匹配您的数据吞吐量,不需要进行管理。Data Firehose还可以调用Lambda函数来转换、过滤、解压缩、转换和处理源数据记录。在这个解决方案中,流源是一个Kinesis数据流,目标目的地是一个S3桶。
设置数据消防软管交付流
-
在Data Firehose控制台中,从左侧导航窗格中选择交付流,然后选择创建交付流。
-
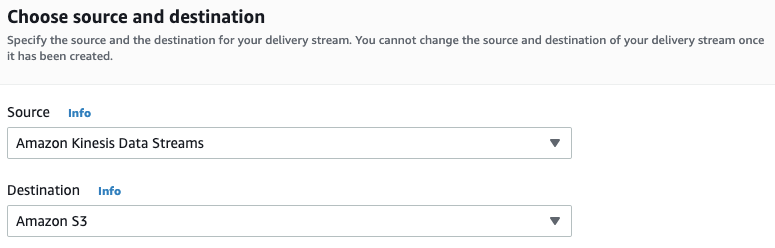
在“选择源和目标”页面的“源”下,选择Amazon kineesis数据流。在Destination下,选择Amazon S3。
-
选择您在上一步中创建的kineesis数据流DevicelogDataStream。
-
向下滚动到Transform和转换记录,并添加您在前一个过程中创建的Lambda函数,以只选择被DynamoDB TTL进程过期的项。
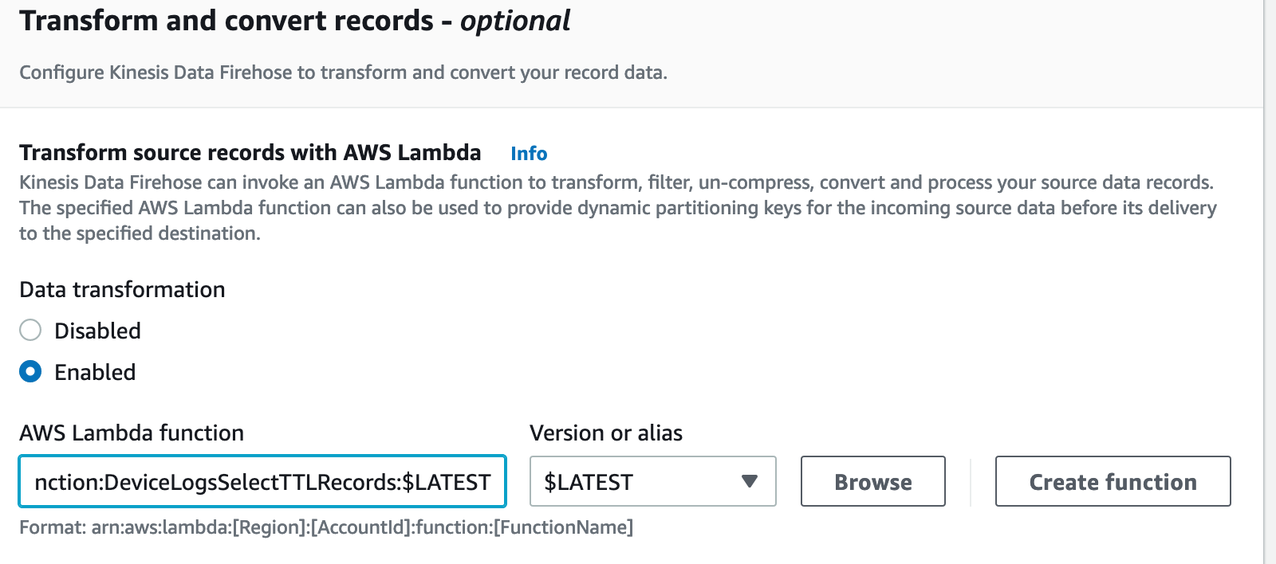
-
向下滚动到Destination settings并选择一个目标S3桶。这是Data Firehose交付流将导出到的位置。
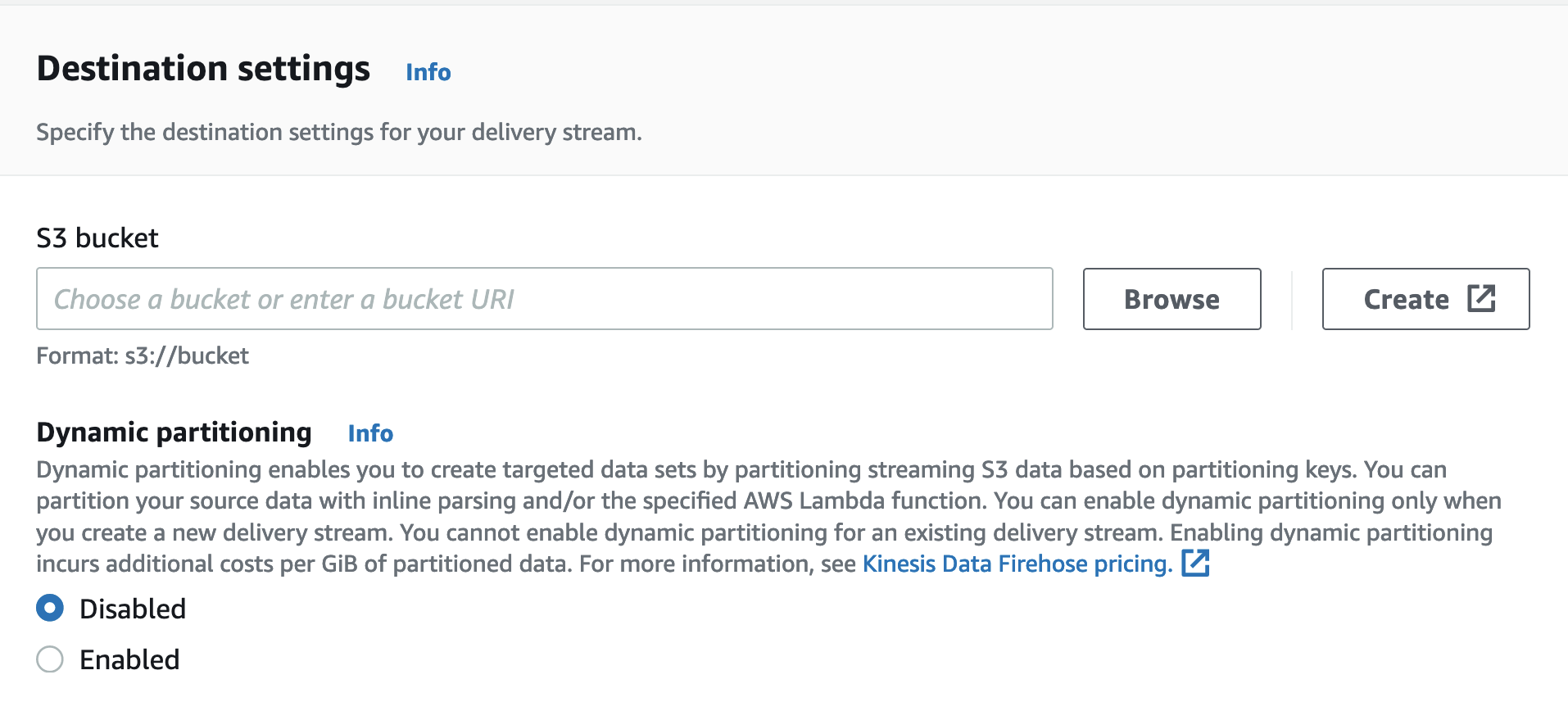
验证TTL记录过期和发送到S3桶
当表上启用TTL时,您可以通过查看TimeToLiveDeletedItemCount CloudWatch度量来验证记录是否如预期的那样被删除。
验证TTL记录过期
-
转到DynamoDB控制台,从左侧导航窗格中选择Tables,然后选择要验证的表。
-
选择Monitor选项卡以查看表的CloudWatch指标。
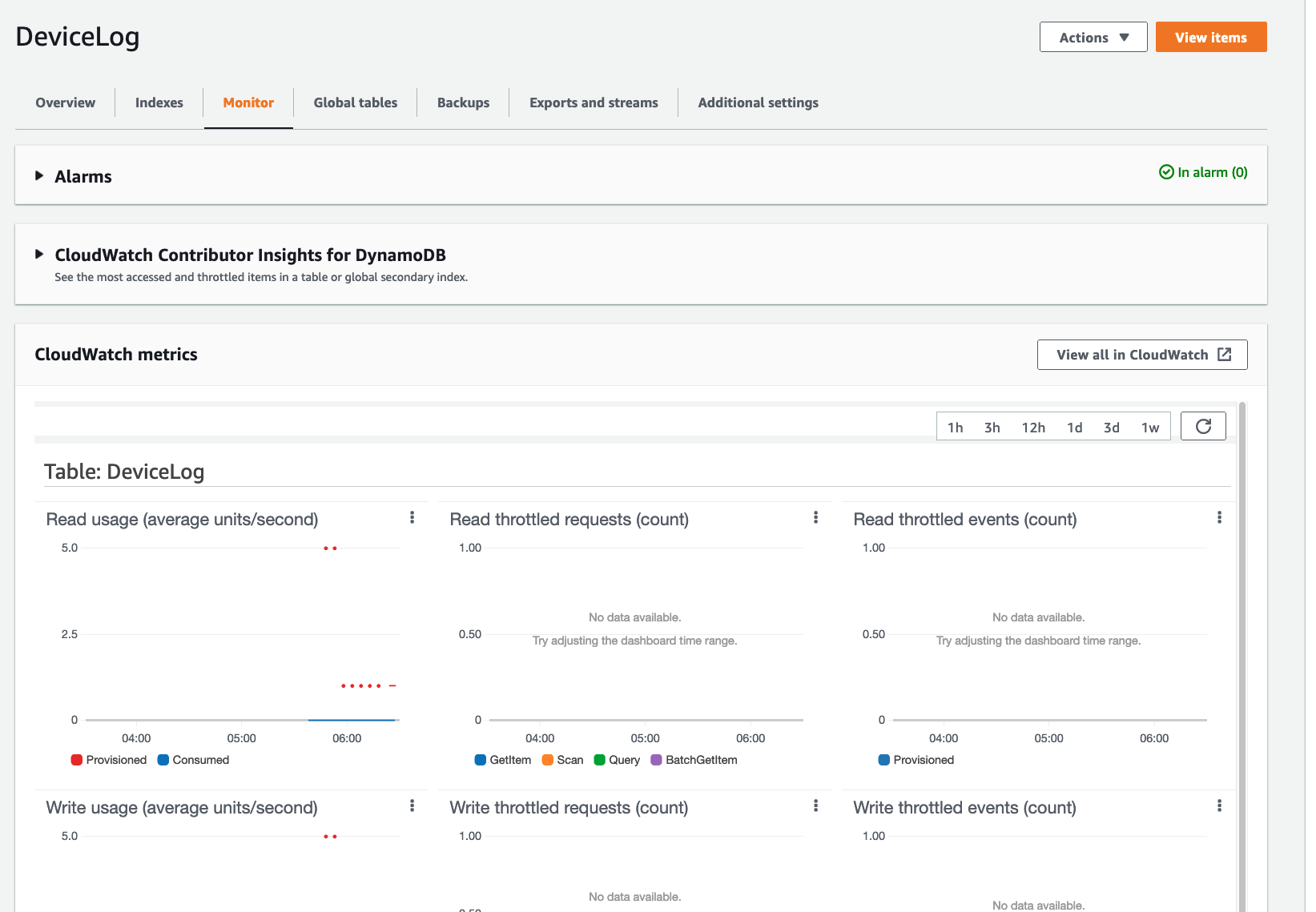
-
向下滚动Monitor选项卡,查看表的CloudWatch指标。CloudWatch的指标每分钟都会根据DynamoDB TTL删除的项的数量进行更新。
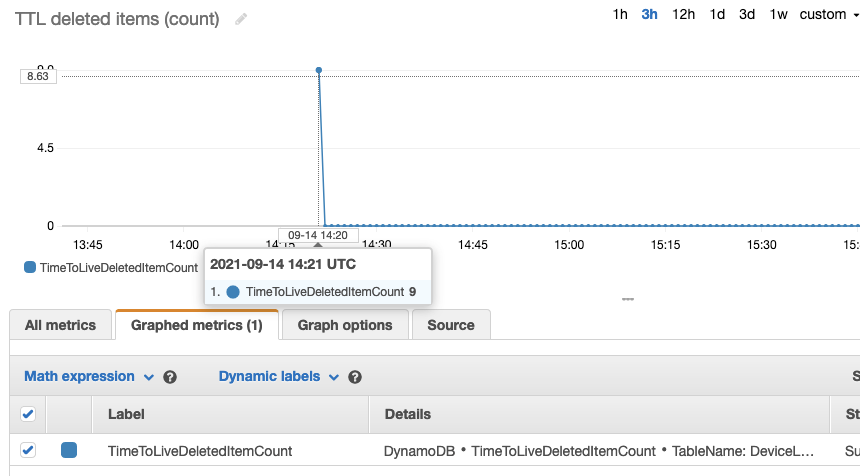
现在您看到了TTL删除在TimeToLiveDeletedItemCount度量中,您可以检查工作流是否按预期的方式归档项目。换句话说,您可以验证TTL项被放入到Kinesis流中,转发到Firehose交付流,批处理到对象中,并存储在S3桶中。
验证项目是否被交付到S3桶
-
打开Amazon Kinesis控制台,从左侧导航窗格中选择交付流,然后选择您的Kinesis Data Firehose交付流。
-
选择“监控”选项卡。您应该开始看到数据和记录流入。
-
作为监视Firehose交付流的一部分,转到Kinesis Firehose控制台并选择您的交付流。
-
选择Monitoring选项卡并查找DeliveryToS3。记录指标。
-
向下滚动Monitoring选项卡,查看该流的CloudWatch指标。
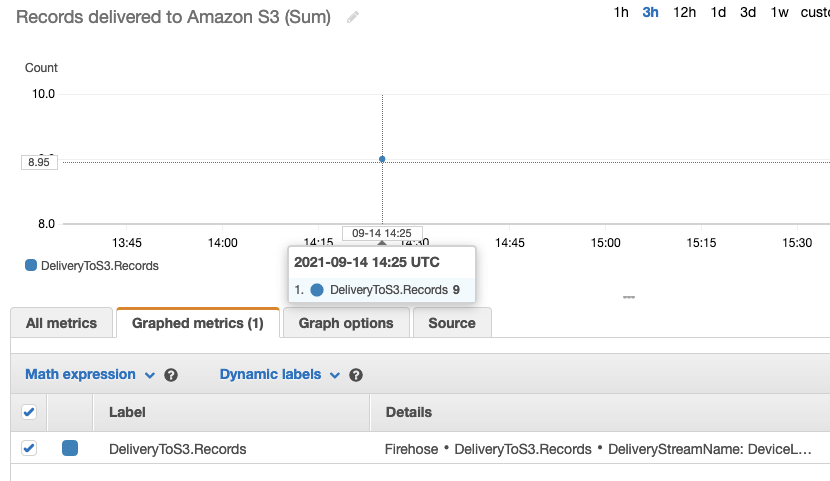
-
转到Amazon S3控制台,从左侧导航窗格中选择Buckets,然后选择目标S3 bucket。
-
大约15分钟后,您应该会看到对象被以年/月/日/小时的格式写入文件夹。
DynamoDB流和运动学数据流
您可以使用Amazon DynamoDB Streams和AWS Lambda设计一个类似的归档策略,例如使用AWS Lambda和Amazon Kinesis Firehose使用DynamoDB Time to Live (TTL)自动将项目归档到S3中所描述的策略。在决定存档策略时,要考虑动态数据流和DynamoDB流在功能上的差异。其中的一些区别是:
-
DynamoDB Streams数据保持24小时。如果您需要更长时间的数据保留,kineesis Data Streams提供7天的扩展数据保留和多达365天的长期数据保留。
-
DynamoDB Streams允许最多两个进程同时从一个流碎片读取。Kinesis数据流允许最多五个进程同时从同一个分片读取数据。无论您使用DynamoDB流还是kineesis数据流,每个碎片都提供每秒最多2 MB的数据输出,而不管从一个碎片并行访问数据的进程的数量。当数据消费者使用增强型扇出时,每个碎片为每个消费者提供每秒最多2m的数据输出。
-
Kinesis数据流让您访问其他Kinesis服务,如亚马逊Kinesis数据Firehose和亚马逊Kinesis数据分析。您可以使用Kinesis服务构建应用程序来驱动实时仪表板、生成警报、实现动态定价和广告,并执行复杂的数据分析,例如应用机器学习算法。
-
kineesis Data Streams不像DynamoDB Streams那样提供严格的项目级排序保证。在kineesis数据流记录中使用approximate ecreationdatetime对具有相同主键的项进行排序,或者跨多个键对项进行排序。近似值ecreationdatetime是由DynamoDB在更新时创建的,精确到最近的毫秒。
DynamoDB Standard-IA表类
在re: invention 2021中,DynamoDB宣布了标准罕见访问(DynamoDB Standard- ia)表类。与现有的DynamoDB标准表相比,这个用于DynamoDB的新表类降低了60%的存储成本,并提供相同的性能、持久性和可伸缩性。
如果您想在存储负载大的工作负载中保持对不经常访问的数据的快速访问,那么DynamoDB Standard-IA是一个很好的解决方案。如果您的用例需要归档数据,并且可以从将数据存储在S3数据湖中获益,那么您可以将TTL与动态数据流或TTL与DynamoDB流结合使用。
结论
在这篇文章中,我们介绍了如何使用动态数据流将数据从DynamoDB表归档到Amazon S3。基于TTL的归档消除了扫描表和删除不希望保留的项的复杂性和成本,从而在预置吞吐量和存储方面节省了资金。
原文标题:Archive data from Amazon DynamoDB to Amazon S3 using TTL and Amazon Kinesis integration
原文作者:Bhupesh Sharma and Veerendra Nayak
原文地址:https://aws.amazon.com/cn/blogs/database/archive-data-from-amazon-dynamodb-to-amazon-s3-using-ttl-and-amazon-kinesis-integration/
