




在我工作的地方,我们在横向扩展配置中使用MySQL来处理我们的数据库需求。
这意味着,您写入主服务器,但读取通常会转到复制树中更下方的副本数据库。
作为开发人员,许多不应涉及的附加要求使其比简单的“主和许多副本”配置更加复杂。但所有这一切的前提是:
- 总是有一个数据库的读副本非常接近您的应用程序,延迟明智;
- 周围总是有足够的数据副本,以便我们可以负担得起在未绑定的本地存储上运行我们的数据库。
我们数据库的本质是这样的,我们用足够的内存淹没了所有数据读取。当数据库涉及到读取时,它便是内存引擎。
我开玩笑说:
您也可以成为一名成功的数据库性能顾问:根据需要说“购买更多内存!”和“缺少索引”。添加“这将是昂贵的”,如果你为SAP或甲骨文工作。
但这是真的:读取对数据库来说真的很糟糕。以下是数据库工作负载在内存中不合适时的样子:
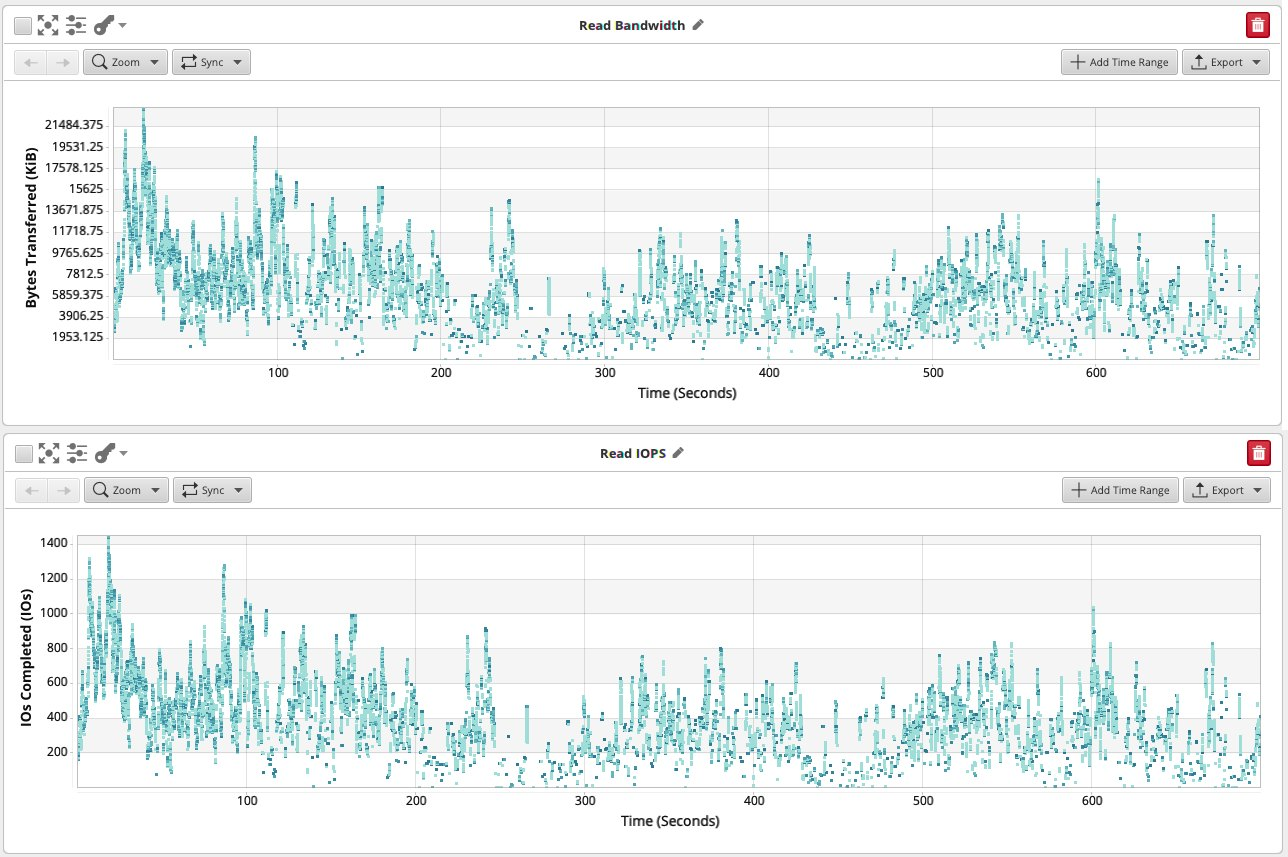
图形中数据来自 blktrace 记录的数据,由 Oakgate 进行工作台智能分析。
此处显示的工作负载太大,无法在提供的 InnoDB 缓冲池中设置其工作集。我们确实看到随着时间的推移,读取流不断,达到几MB /s和每秒约1000个IO操作(IOPS)的调谐。
如果此数据库具有更多内存,则读取操作将攻击内存中的缓存块,并最终从 RAM 提供。我们将在数据库层看到读取请求,但它们将从数据库的缓冲池中得到满足,并且不会命中磁盘,仅保留写入负载。
但是,写入不是更糟糕吗?
这是一个有趣的问题。
我们可以用缓存淹没读取,但我们不能淹没太多的写入。
它们最终必须转到磁盘,并且为了符合ACID标准,我们需要延迟CONCEPT,直到写入到达持久存储层。
根据我们的持久性要求,我们要求写入:
- 命中计算机本地持久性存储(磁盘、NVME 或电池备份缓存单元 (BBU));
- 至少击中第二台计算机;
- 或命中另一个可用区中的第二台计算机。
增加要求会引入更多的延迟,并且由于等待时间增加而降低我们的最大写入速率。
但是未缓存的读取情况更糟。
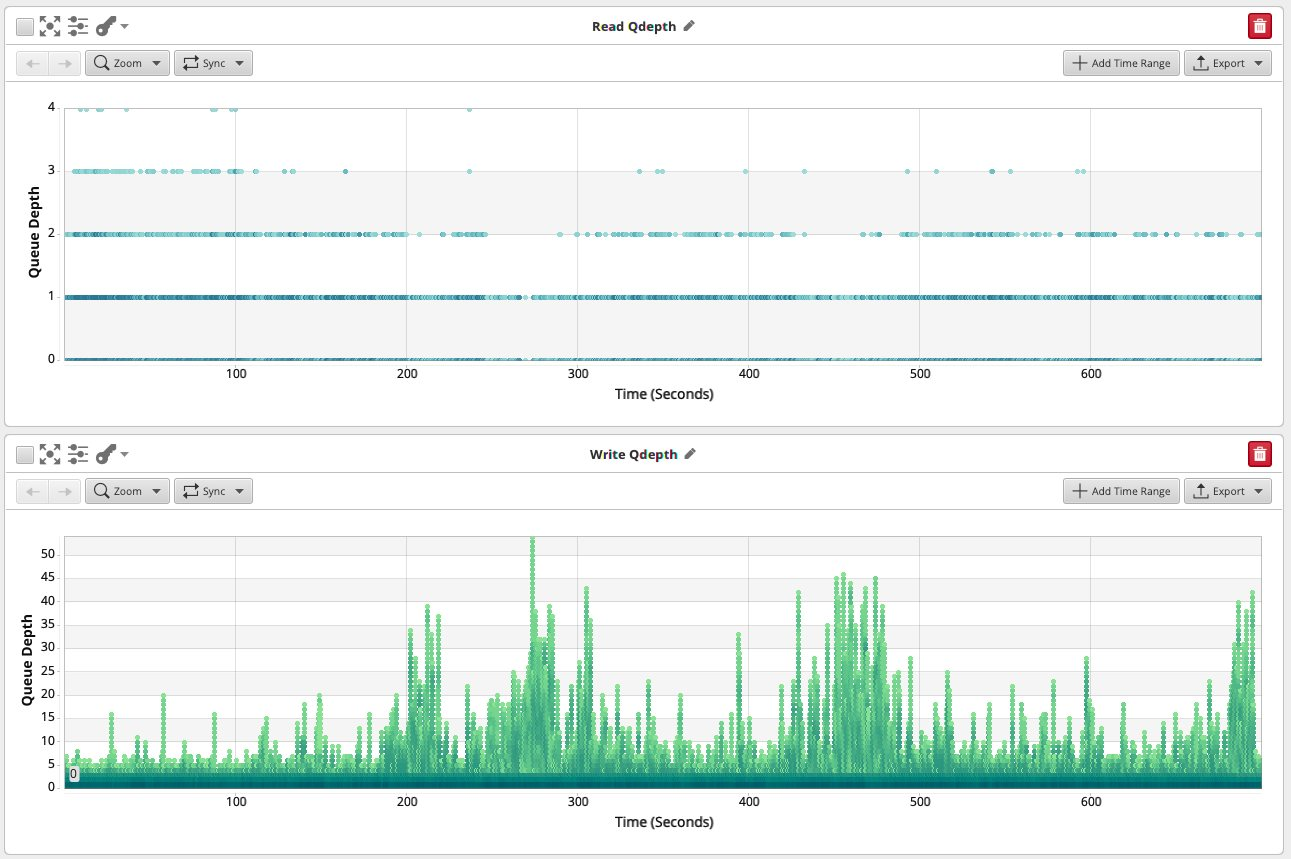
写入可以构建深度队列,但读取几乎不会发生。这是一个关键的观察结果。
当我们将写入发送到存储时,我们可以异步执行此操作:我们触发写入,当我们延迟提交并等待写入完成时,我们可以执行其他操作。这是可能的,因为这些其他写入 - 在很大程度上 - 与先前写入的结果无关,只要排序保证被搁置。写入是可以连续流动和排队的。
读取并不是在多个级别都存在。
数据库从索引中读取数据,索引主要是数据结构,如平衡树,具有较大的扇出。如果数据多于内存和合理索引,则索引的深度约为四层。假设没有缓存,您将需要大约四个媒体访问才能从根访问所需的数据。
为什么大约四层?
在树中,树的深度是扇出基数的记录数的对数。
对于每个级别的 10 亿条记录和 200 个扇出,您将获得 3.91 的树深。
更少的记录会使其更浅一些:宽度为200的100万条记录的深度为2.60。
较小的扇出会使其更深一些:扇出为20而不是200的100万条记录将为您提供4.61的深度(请记住,我们正在处理16 KB大小的页面,因此仅扇出20是非常小的)。
在实践中,我们数据库中的所有平衡树的深度约为4层,因为log(n)/log(扇出)实际上是一个值在4左右的常量。
大多数情况下,即使对于大数据,我们也可以完全缓存内部树,因此这归结为4个磁盘读取请求和一个实际的磁盘读取。但是:在这样的查找中,每次磁盘读取完全取决于上一个磁盘读取的结果。读取操作都按磁盘访问序列化。
这再次强调了内存在数据库操作中的重要性。“购买更多的内存,然后投入更多的内存”是一个非常明智的建议。
现在,我们实际上不只是从单个表中读取数据。我们经常将两张桌子联接在一起。在循环连接中,我们将两个表与以下形式的 SQL 连接:
SELECT a.somecolumn, b.someothercolumn
FROM a JOIN b
ON a.aid = b.aid
WHERE <some conditions>
这将从 a 中获取行,希望使用索引(请参阅上面的索引读取),然后在生成行时从a中获取行。它将使用 a.aid 发出的值并应用它们来查找 b 表中的 b.aid 行。
同样,在尚未完成 对 a 的读取之前,我们无法知道我们对 b 中的哪些行感兴趣。b 上的读取访问取决于结果,因此在 a 上完成(索引)读取。
这不是构建深度队列的好方法:在完成之前的读取之前,工作会停滞不前 - 除非我们提供足够的内存以使读取首先不会发生。
读取和写入在现实中是什么样子的?
了解我们的可用性数据库。他们持有酒店客房供应信息。此数据库在裸机、16C/32T、128 GB 内存和两个 SSD 上运行,控制器上带有电池备份缓存单元 (BBU)。

该框主要提供读取,最后一秒为4746,并且作为副本仅看到来自上游的写入。
该框当前保存了几 TB 的数据,每秒处理大约 6000 到 12000 个查询。
语句组合看起来像Java:大约50%的语句是 SELECT ,大部分 SET 语句表示JDBC驱动程序,其余的是DML和事务管理。
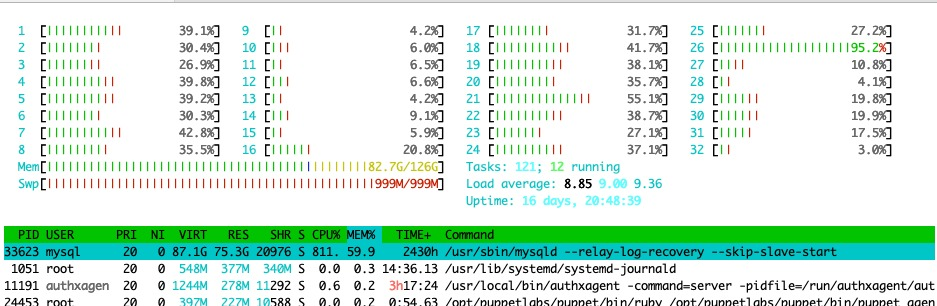
该箱子目前以9的负载运行,但现在是清晨,晚上我们有一个负载峰值。在负载为12时,如果我们丢失了一个可用区并且必须将发生故障的数据中心负载折叠到幸存的机器中,则它有足够的容量继续进行。
这种具有这种工作负载的硬件在负载为24时会变得令人不安的抖动。
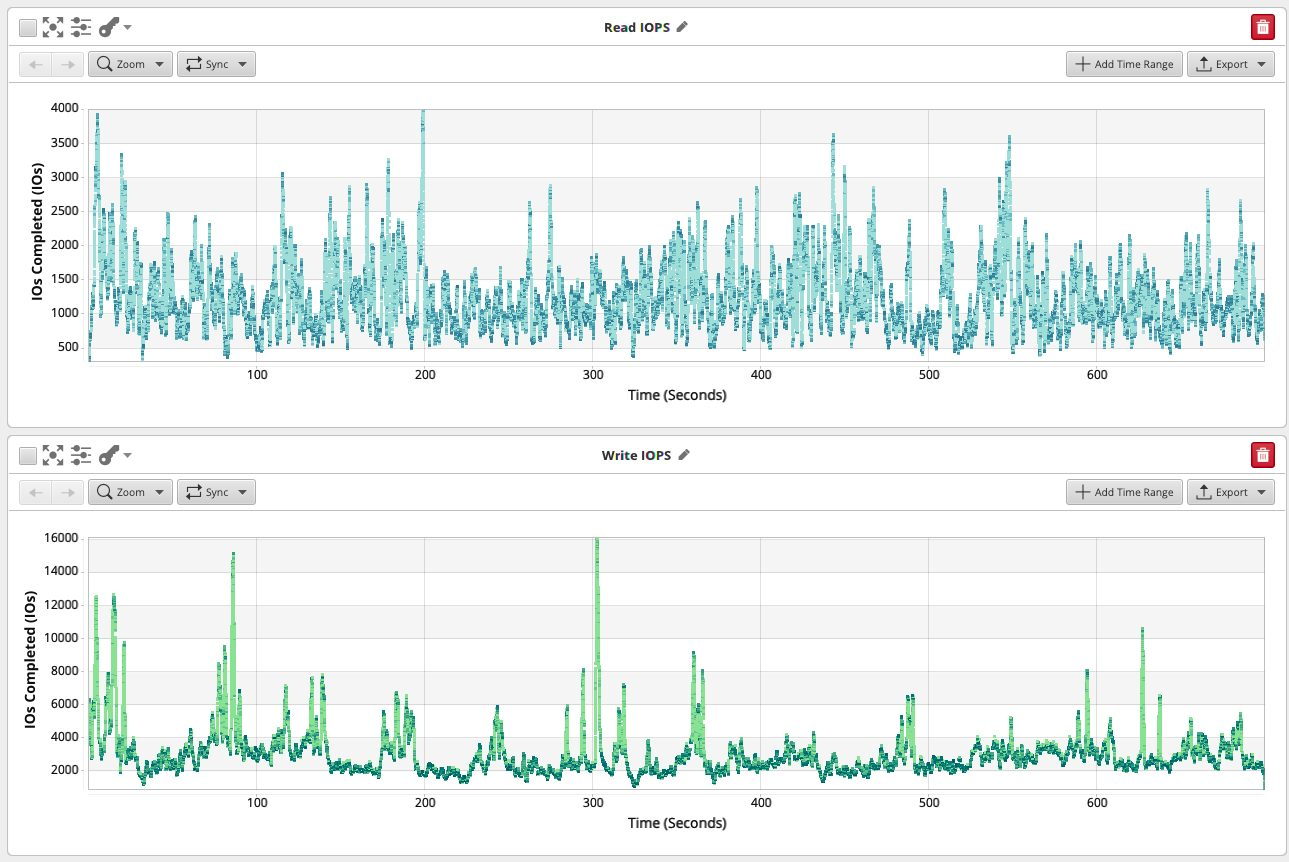
我们还观察到大约1000 ISH IOPS的可变读取负载,峰值达到4000。
这很有效。情况如何?
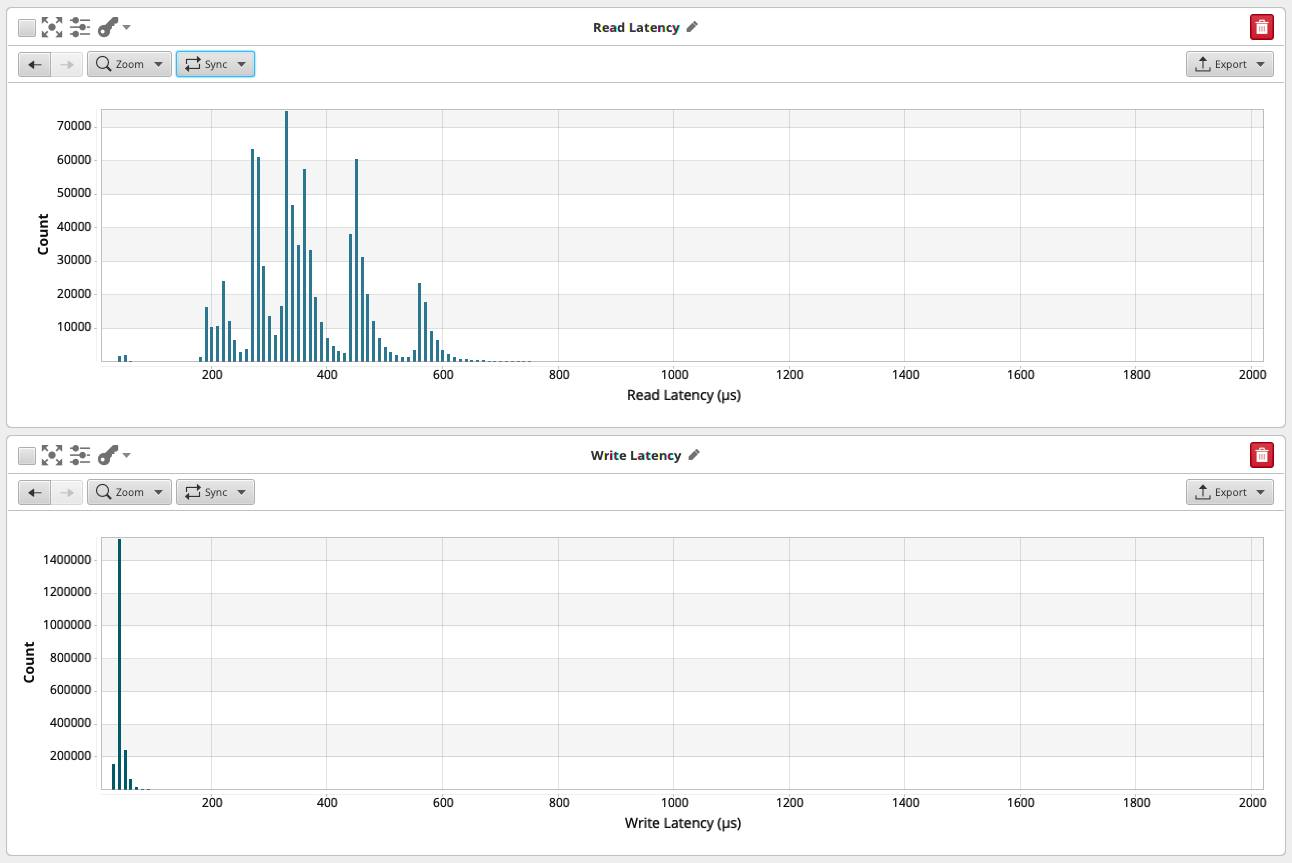
我们在μs尺度上观察读取和写入延迟,即10^-6,百万秒.
读取延迟是分层窗帘,峰值为 0.2 ms、0.26 ms、0.33 ms、0.45 ms 和 0.58 ms。我们可以在整个物体上绘制一个大的高斯曲线,峰值为0.33 ms。
写入延迟是…不存在的?
当我们放大时,我们可以看到磁盘写入似乎以40 μs,0.04 ms的延迟发生。这与PCIe总线传输相吻合 - 256字节总线传输大约需要100 ns,40 μs适用于大约12 KB的总线时间,相比之下,16 KB是MySQL数据页面的大小。号码签出。
这是将 16 KB 的数据从 RAM 中的 MySQL 缓冲池传输到 HP SmartArray 控制器卡上价值 4 GB 的 BBU 缓存所需的时间,该缓存计为本地持久性。然后,控制器上的ARM CPU将接受所有这些写入,对它们进行排序,批处理它们并将它们写出到后台的SSD。
总而言之,效果非常好:该刀片的成本约为每台机器每月150欧元,保留间隔为5年。它将 1 TB 的逻辑数据存储在 1 TB 的物理磁盘空间中。而且它以惊人的低和稳定的延迟数字运行。
这在机器级别上不是多余的 - 我们正在使用其他数据库级技术来实现这一目标。使用复制,我们在其他计算机和其他数据中心上复制此计算机上的数据。这使我们能够利用冗余来增加容量,同时提高可用性。
这样做的代价也使我们能够完全消除额外的缓存层,例如memcached - 也消除了memcached使用带来的整个缓存不连贯错误,直到2012年,我们删除了memcached。
更改等式
将分布式存储引入等式从根本上改变了底层存储的属性。
您的存储不再是机器本地的,并且由于超出本文范围的原因,它也总是被复制 - 通常使用n = 3的复制工厂。也就是说,数据库中的 1 TB 数据在磁盘上变为 3 TB 数据,在三台不同计算机中的每台计算机上每台计算机上为 1 TB。
遍历本地数据中心的数据中心大约需要 60 μs,加上将数据写入本地持久性存储的时间使得每个跃点需要 100 μs,0.1ms。多个副本和协调相加,最终结果是写入时间分布,此处测试的存储的最大时间为 0.9 毫秒。
读取延迟具有相同的形状,但略低 - 我们需要一个数据副本来读取它,而不是全部,所以我们在0.6ms左右出来。
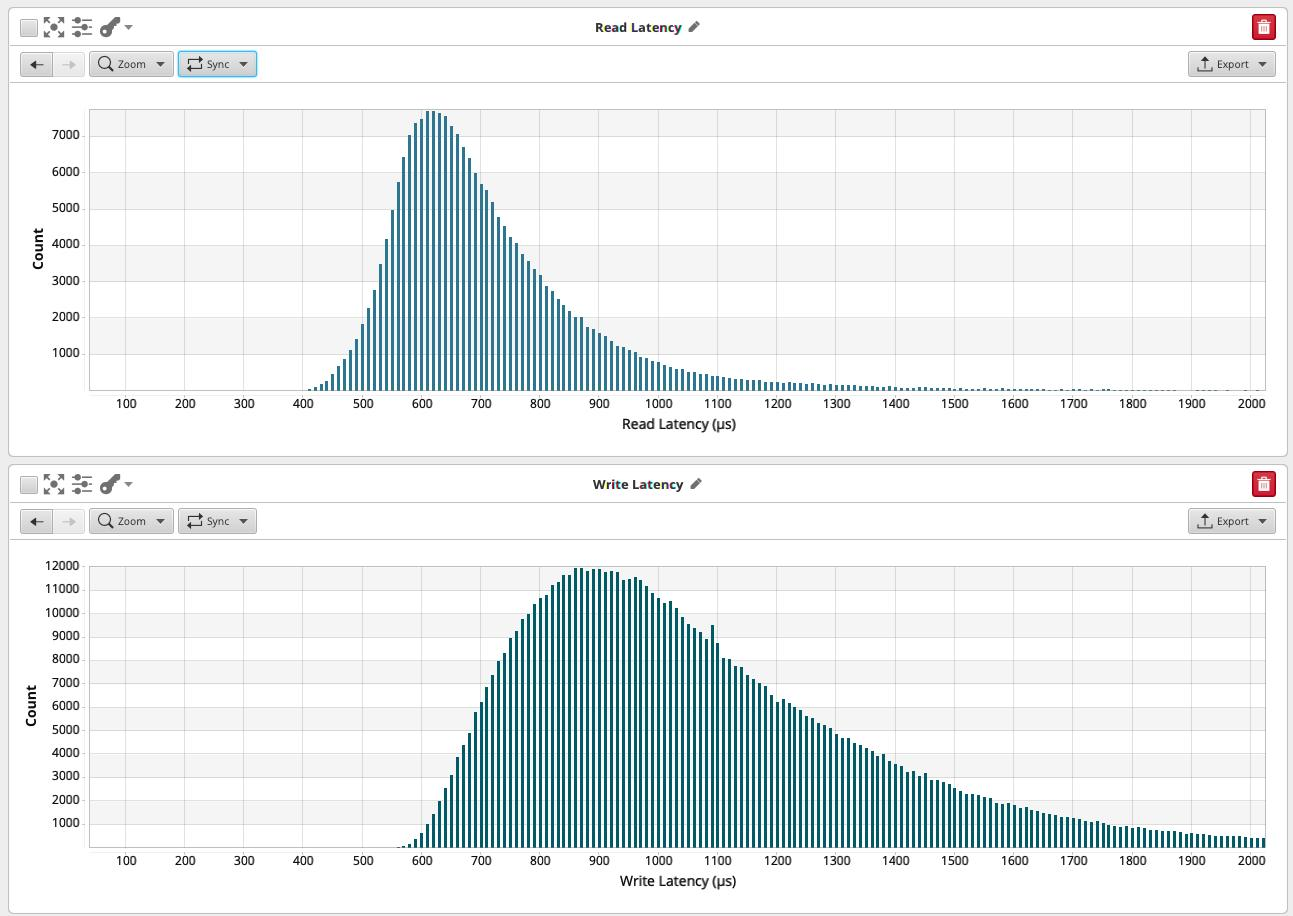
Ceph 存储的读取和写入延迟的延迟图为 r=0.6 毫秒,w=0.9 毫秒。对于Ceph来说,这是非常低的 - 2015年的Ceph集群约为5.0毫秒。
在此存储上运行具有可比较配置文件的数据库会对数据库行为造成很大变化:
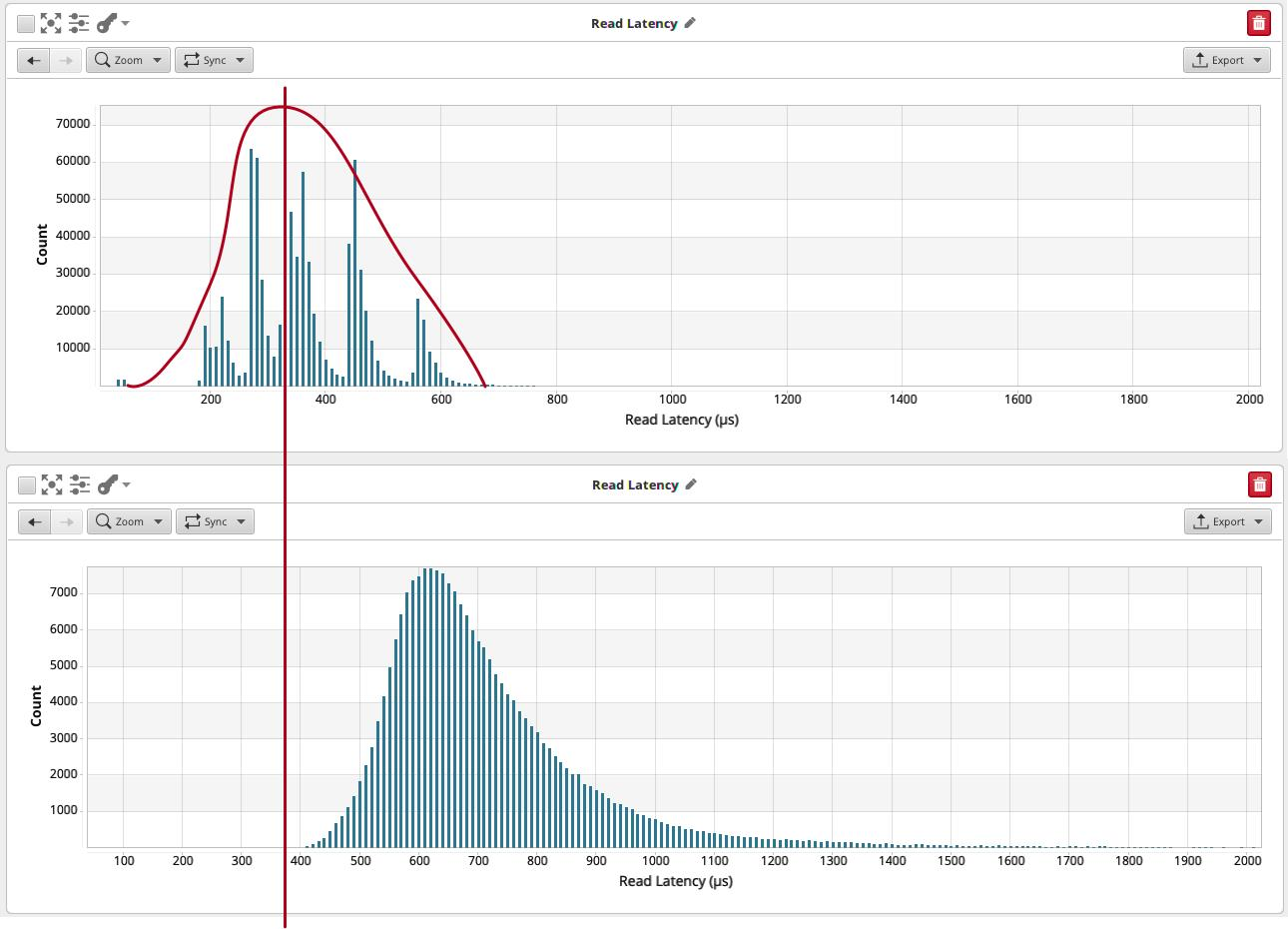
读取延迟比较:上图是本地计算机的图形,下面是 Ceph 卷上的可比工作负载。
我们有读取,读取延迟大约是本地SSD的两倍。我们已经讨论了读取如何不能很好地排队,因为以后读取的结果通常依赖于先前读取的结果。
这意味着对于相同数量的连接,我们将实例的读取容量降低了 2。
我们可以,按工程和货币成本的顺序增加
- 添加内存以淬灭增加的缓冲池中的读取
- 将框添加到池中,但需要额外实例
- 添加连接并使用多个并行任务查询数据库,尝试将我们的工作负载设计得更加并行
对于要测试的层次结构,发生了第二件事:我们增加了实例数量,以便在读取延迟恶化的情况下处理查询负载。我们应该尝试第一件事:使用具有更多内存的实例来使磁盘访问消失。
对于写入,情况完全改变了:
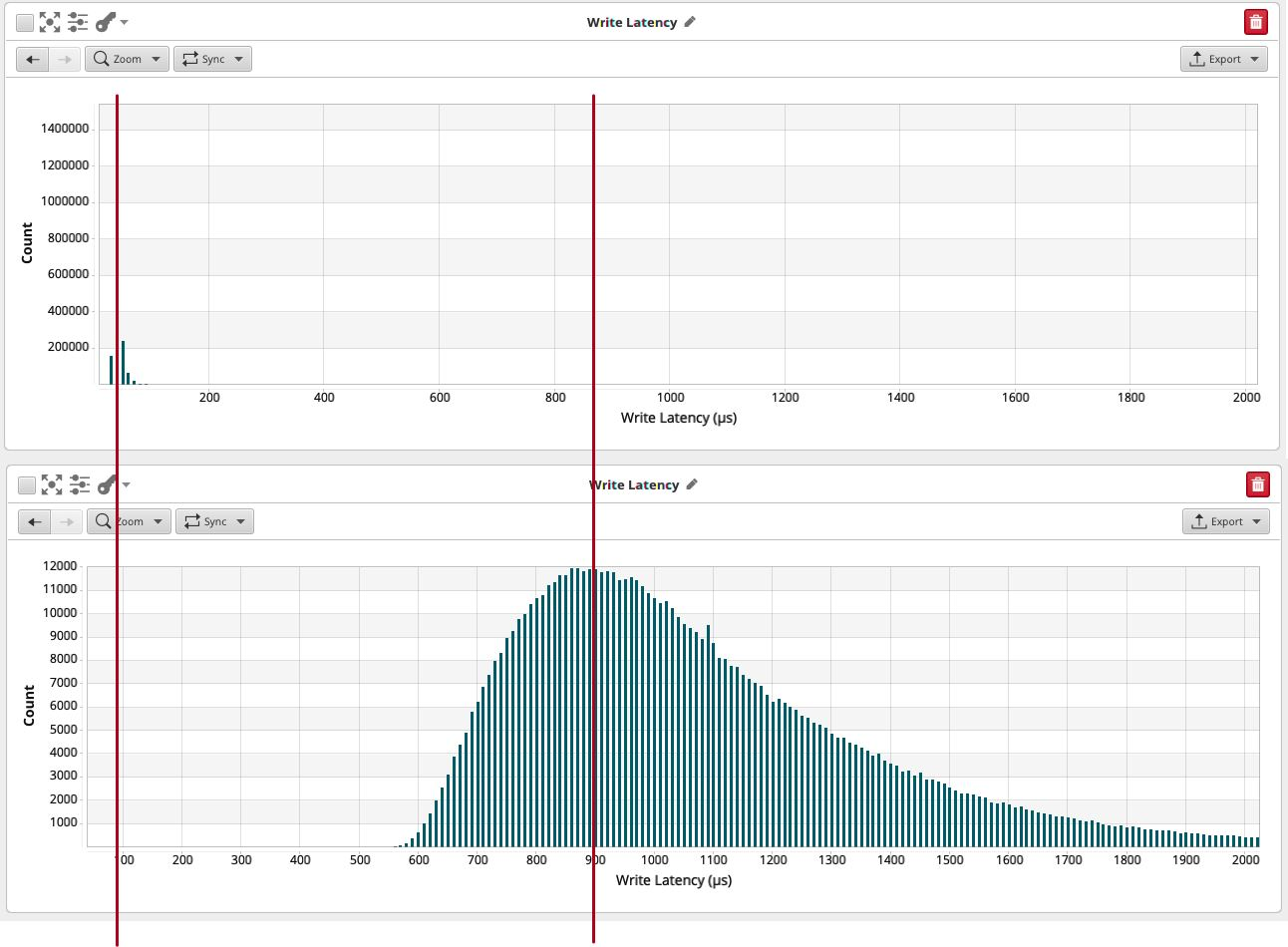
写入延迟比较:上图是来自本地存储计算机的图形,低于 Ceph 卷上的可比工作负载。
写入现在需要 0.9 毫秒,而不是 0.04 毫秒。
此外,虽然写入延迟直方图是很好的高斯形状,但它确实具有相当大的基宽:0.9 ms实际上是另一侧从0.6 ms到1.6 ms的曲线的基数。
很好地写入队列,并且此处的存储在基准测试中的并行负载下表现非常好。如此多的并行写入应该可以很好地工作:每次写入需要0.9毫秒,但您可以同时执行其中的许多写入。
遗憾的是,事务性工作负荷没有这种形状。并行复制受制于许多有关重新排序的约束,并且还受制于实现细节所产生的限制。
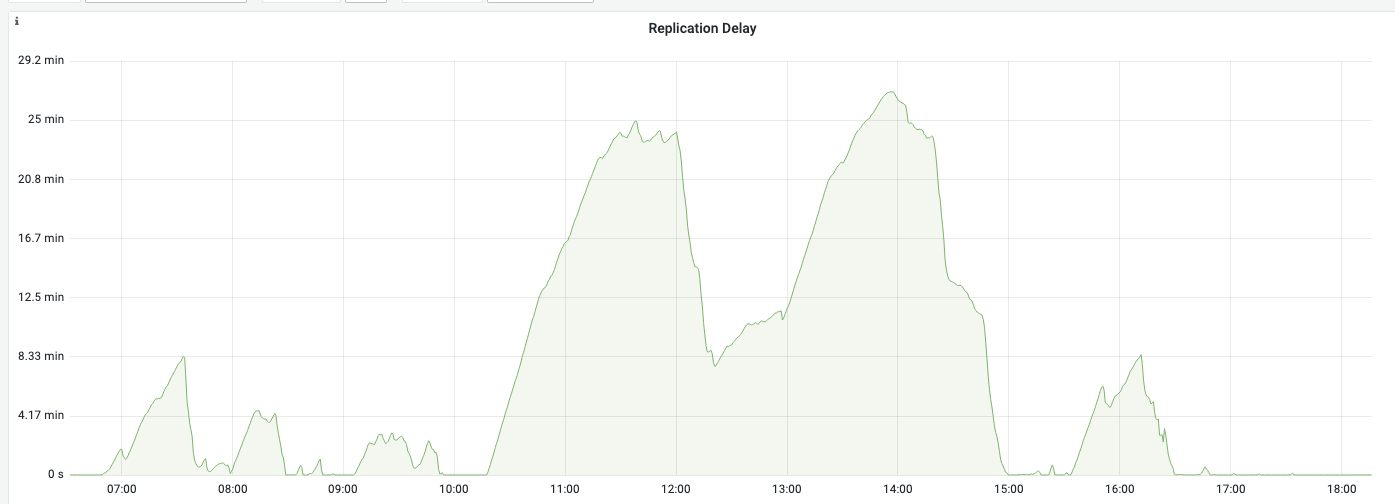
随时间变化的复制延迟:尽管并行复制处于活动状态,但实例仍无法跟上写入负载。只有小心的写入调制才能使副本不会延迟更多。
这甚至不是一个高写入负载:这里显示的语句组合甚至没有触及1000个插入/秒的障碍。
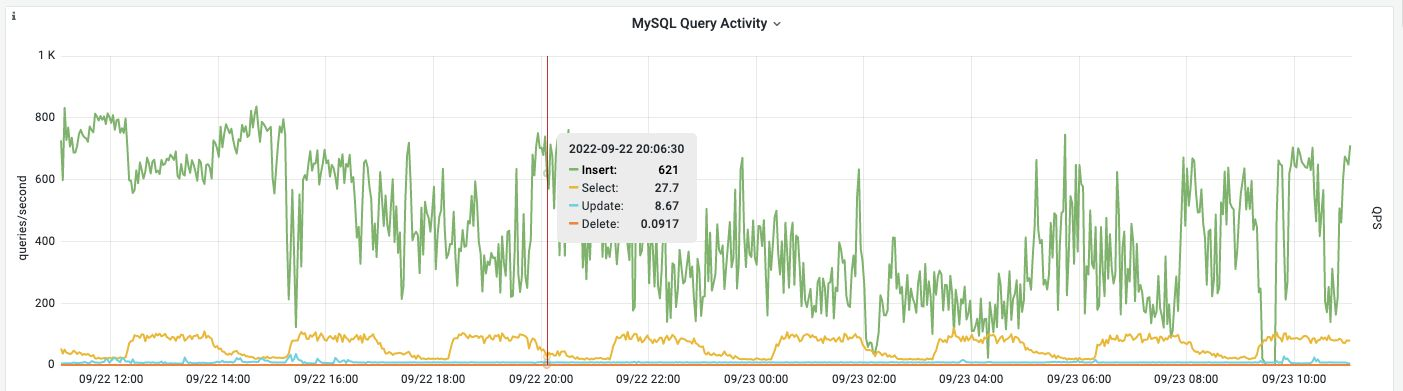
然而,存储统计数据绝对是毁灭性的:
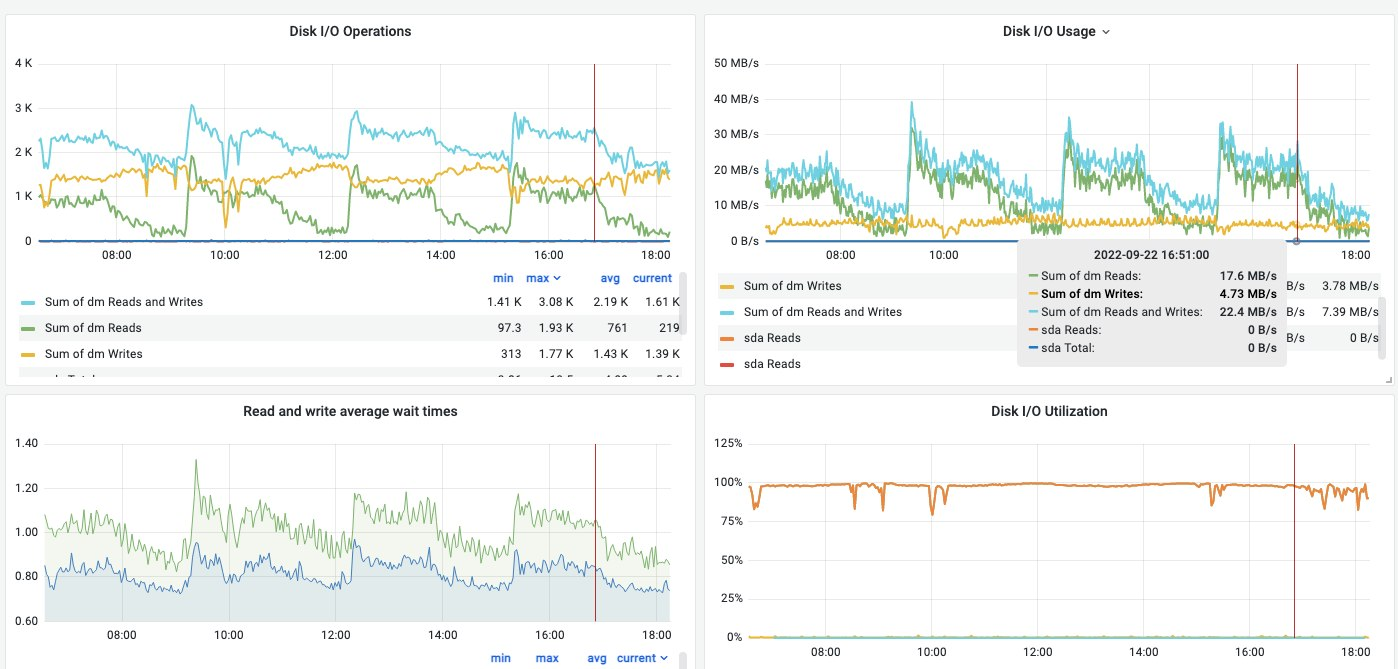
我们看到卷上每秒有超过1000次读取和1000次写入,考虑到我们上面看到的延迟,这是很好的,但没有parallism。我们看到的 I/O 适用于 22 MB/s 的聚合 I/O,并导致磁盘 I/O 完全饱和。
没有简单的方法可以解决这个问题,除了对应用程序进行深入的更改以使其以不同的方式编写。但是,我们并不想把应用程序业务部门开发人员的时间花在“围绕我们选择的存储解决方案的复杂性编写代码”上,而不是“解决业务问题”上。
在虚拟化环境中使用本地存储的建议仍然有效,因为它的性能更好,并且不提供我们没有用处的存储级冗余,因为复制在数据库级别提供了容量和冗余。
原文标题:MySQL: Local and distributed storage
原文作者: KRISTIAN KÖHNTOPP
原文地址:https://blog.koehntopp.info/2022/09/27/mysql-local-and-distributed-storage.html
