





说明:学习了三周GBase 8a MPP Cluster相关知识,前段时间参加了孙云吉老师的GBase 8a MPP Cluster explain分布式执行计划相关的培训,个人知识有限,只记录下本人对GBase 8a MPP Cluster分布式执行计划浅显的理解(部分截图来自培训内容)。
一 多表连接操作
二 group by操作
三 优化案例举例
一 多表连接操作
1 静态hash join执行计划
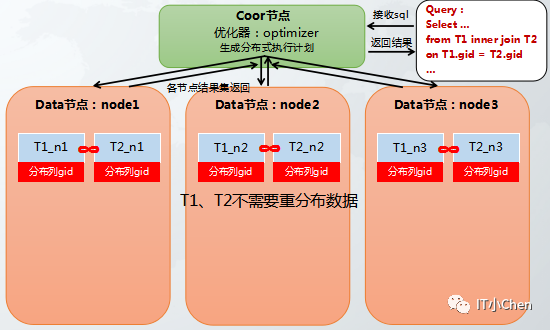
场景:两个hash分布表进行join,并且关联列是hash分布列。
理论上静态hash join是最优的,因为可以直接在各个节点上分别单独执行分布式join算子,不需要拉复制表或hash动态重分布。
但是当hash分布列数据分布严重不均时,既数据倾斜严重,大多数数据集中在某一节点上,效率也会有影响,因为分布式运算时长取决于最慢的节点。
举例说明:
create table t1 (aid int,gid int) distributed by ('gid');
create table t2 (bid int,gid int) distributed by ('gid');
insert into t1 values(1,100),(1,200),(2,100),(3,50),(2,20),(6,80),(9,10),(6,0),(3,12),(1,18),(9,1);
insert into t2 values(1,0),(300,12),(1,6),(20,50),(50,10),(1,80),(3,10),(9,15),(20,12),(13,18),(2,1);
gbase> explain select t1.aid,t2.bid from t1 inner join t2 on t1.gid=t2.gid and t1.gid=100;

2 分布表join复制表执行计划
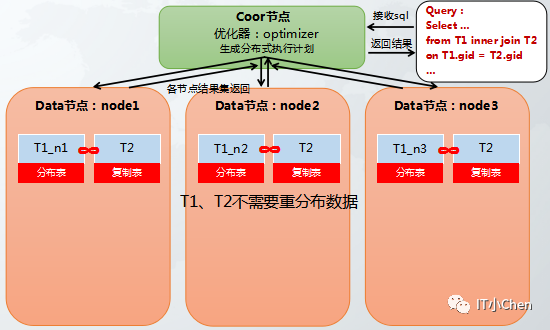
场景:随机分布表或HASH分布表和复制表进行关联。
也可以直接在各个节点上分别单独执行分布式join算子,不需要拉复制表或hash动态重分布。随机分布表和复制表进行关联时数据是被均匀打散到各个节点上的,效率较高。HASH分布表和复制表进行关联效率和hash分布列数据均匀程度有关。
举例说明:
create table t3(bid int,gid int) replicated;
insert into t3 select * from t2;
explain select t1.aid,t3.bid from t1 inner join t3 on t1.gid=t3.gid;

3 小表拉复制表join执行计划
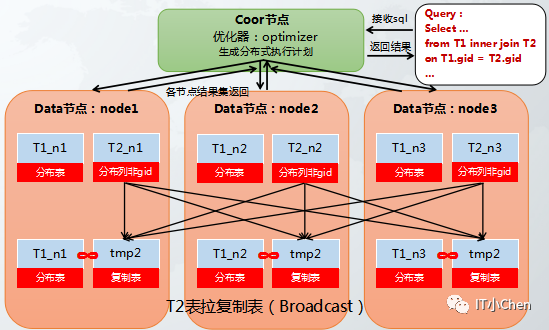
场景:t1,t2两个hash分布表进行关联,其中t2关联列不是hash分布列,当t2数据量较小时,可以基于t2表在各个节点上生成一个t2的复制表,然后t1和t2的复制表进行关联,既将执行计划变成分布表join复制表。
或者 t1随机分布表,t2 hash分布表或随机分布表,其中t2数据量很小,可以基于t2表在各个节点上生成一个t2的复制表,然后t1和t2的复制表进行关联,既将执行计划变成分布表join复制表。
那么到底t2数据量多小才适合拉复制表而不是选择动态重分布呢?有对应的参数进行限制。
举例说明:
create table t4 (aid int,gid int);
create table t5 (bid int,gid int);
insert into t4 values(1,100),(1,200),(2,100),(3,50),(2,20),(6,80),(9,10),(6,0),(3,12),(1,18),(9,1);
insert into t4 select * from t4;
insert into t4 select * from t4;
insert into t4 select * from t4;
insert into t4 select * from t4;
insert into t4 select * from t4;
insert into t5 values(1,0),(300,12),(1,6),(20,50),(50,10),(1,80),(3,10),(9,15),(20,12),(13,18),(2,1);
gbase> show variables like '%hash_redist_threshold_row%';
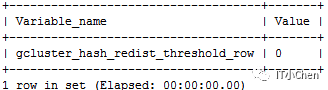
gbase> explain select t4.aid,t5.bid from t4 inner join t5 on t4.gid=t5.gid;
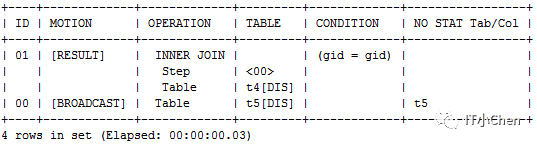
4 动态重分布hash join执行计划
场景:t1,t2两个hash分布表进行关联,其中t2关联列不是hash分布列,T2表按照关联列做hash重分布,再和T1表在各节点分布式join。
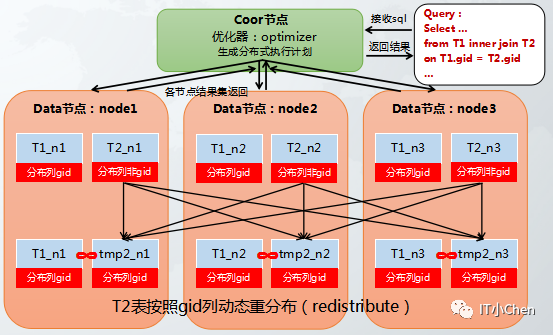
t1,t2两个hash分布表进行关联,其中关联列都不是t1,t2的hash分布列,T1表和T2表都按照gid做hash重分布,重分布后再分布式各节点执行join
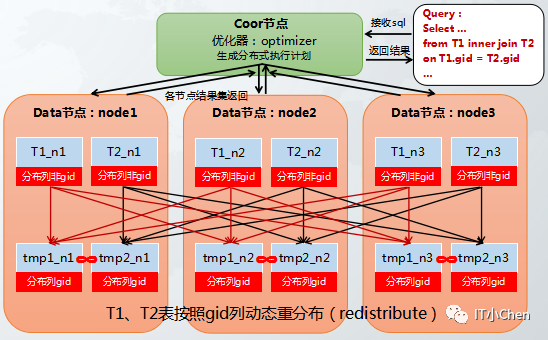
举例说明:
t6按照gid做hash重分布,在和t2表关联。
create table t6 (bid int,gid int) distributed by ('bid');
insert into t6 select * from t2;
gbase> explain select t1.aid,t6.bid from t1 inner join t6 on t1.gid=t6.gid;
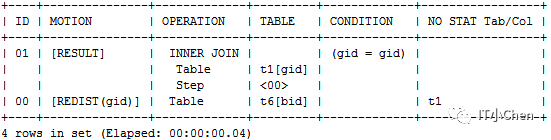
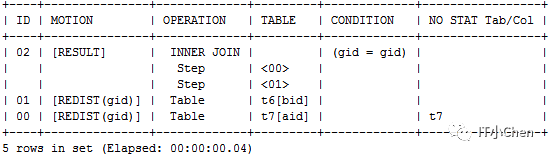
T6表和T7表都按照gid做hash重分布,重分布后再分布式各节点执行join
create table t7 (aid int,gid int) distributed by ('aid');
insert into t7 select * from t1;
gbase> explain select t7.aid,t6.bid from t7 inner join t6 on t7.gid=t6.gid;
二 表group by操作几种场景
1 静态hash group by执行计划
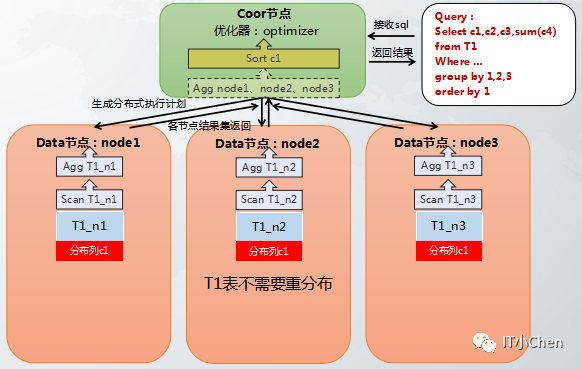
场景:hash分布表在执行group by操作时,分组的列中包含hash分布列,不需要动态重分布和二阶段group by,各个节点分布在本地进行group by后汇总结果集即可,效率最高。
举例说明:
gbase> create table t0 (c1 int,c2 varchar(10),c3 int,c4 int) distributed by ('c1');
gbase> insert into t0
values(1,'a',100,1),(2,'b',1,1),(100,'a',12,1),(1,'c',16,1),(3,'d',22,1),(4,'e',1,1),(1,'a',8,1),(200,'e',16,1),(200,'abc',12,1),(8,'x',12,1);
gbase> explain Select c1,c2,c3,sum(c4) from t0 where c3<100 group by 1,2,3;

2 动态重分布group by执行计划
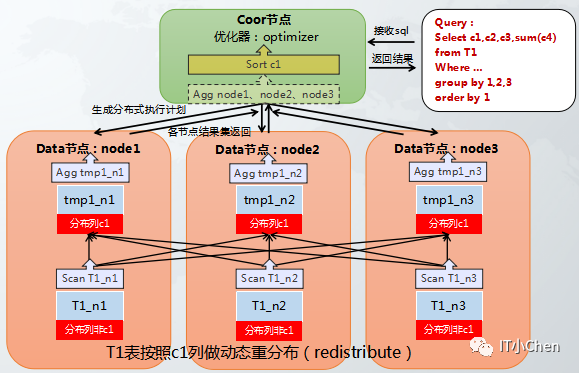
场景:hash分布表在执行group by操作时,分组的列中不包含hash分布列,需要动态重分布或二阶段group by,效率较低,具体执行动态重分布还是二阶段group by受参数gcluster_hash_redistribute_groupby_optimize控制。动态重分布是将group by后的第一列作为hash分布列,动态生成hash分布表,在进行group by操作。
举例说明:
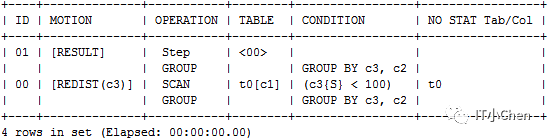
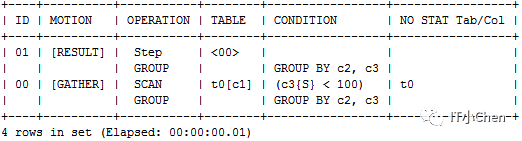
gbase> explain Select c2,c3,sum(c4) from t0 where c3<100 group by c2,c3;

gbase> explain Select c2,c3,sum(c4) from t0 where c3<100 group by c3,c2;
3 两阶段group by执行计划
场景:hash分布表在执行group by操作时,分组的列中不包含hash分布列,需要动态重分布或二阶段group by,效率较低,具体执行动态重分布还是二阶段group by受参数gcluster_hash_redistribute_groupby_optimize控制。在进行两阶段group by时,各个节点分别进行group by操作,将结果集汇总到集群层,在集群层在进行一次group by操作,汇总后结果集越大,性能越差。
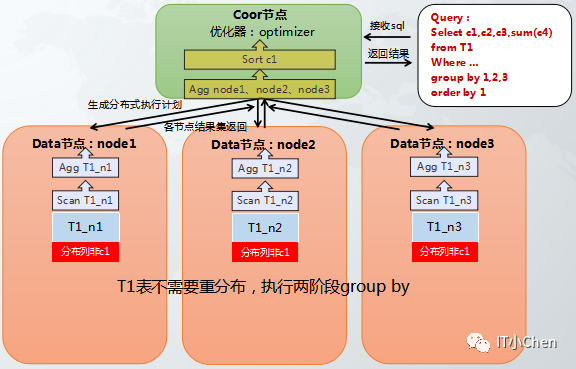
举例说明:
gbase> show variables like 'gcluster_hash_redistribute_groupby_optimize';
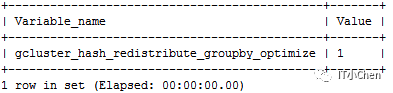
gbase> set gcluster_hash_redistribute_groupby_optimize=0;
gbase> explain Select c2,c3,sum(c4) from t0 where c3<100 group by c2,c3;
三 优化案例举例
原SQL:
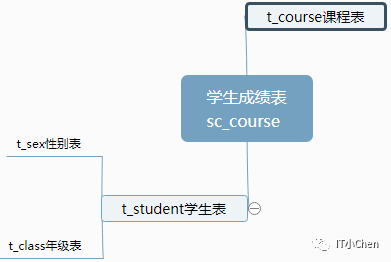
gbase> select distinct a.class_name,b.sno,b.sname
-> from t_class a,t_student b,t_sex c,sc_course d
-> where a.class_id = b.class_id
-> and c.sex_id = b.sex_id
-> and b.sno = d.sno
-> and d.grade < 60;
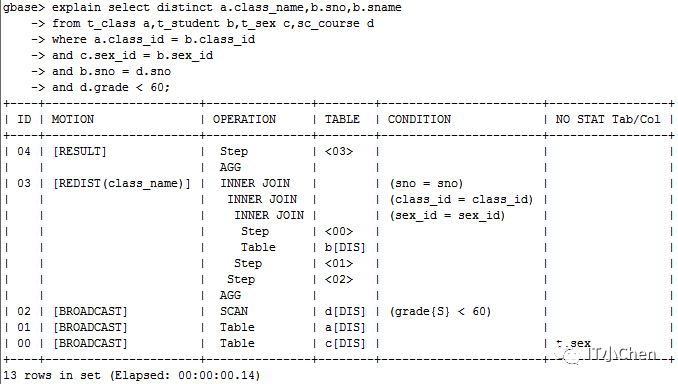
通过执行计划可知:
1 t_sex拉复制表
2 t_class拉复制表
3 sc_course通过grade条件过滤后拉复制表
4 t_student随机分布表和t_sex复制表通过sex_id=sex_id进行关联
5 上一步结果集和t_class复制表通过glass_id进行关联
6 上一步结果集和sc_course复制表进行关联通过sno进行关联
7 上一步结果集合根据class_name列进行动态重分布(因为有distinct操作)
8 上一步结果集合并返回给客户端
优化:
当前存在的问题:
上述所有表都属于随机分布表,在多表关联时,数据库自动将t_sex、t_class、过滤后的sc_course拉复制表,和t_student随机分布表进行关联,其中sc_course即使通过条件过滤后数据量还是比较大,拉复制表的代价很大。
解决方案:
t_sex、t_class表数据量很小,由随机分布表改成复制表。
sc_course和t_student数据量较大,由随机分布表改成HASH分布表,分布列为关联列。
优化后:
gbase> select distinct a.class_name,b.sno,b.sname from t_class01 a,t_student01 b,t_sex01 c,sc_course01 d where a.class_id = b.class_id and c.sex_id = b.sex_id and b.sno = d.sno and d.grade < 60;
SQL执行时间由1.03秒优化到0.09秒
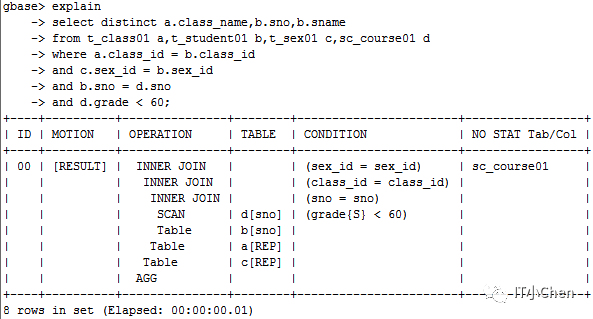
1 sc_course01表为hash分布表,sno为hash列,通过grade<60条件过滤扫描。
2 t_student01表为hash分布表,sno为hash列,全表扫描。
3 sc_course01和t_student01通过sno列进行关联。
4 上一步结果集和t_class01表通过class_id进行关联。
5 上一步结果集和t_sex01表通过sex_id进行关联。
6 合并结果集,返回到客户端。
更多数据库相关学习资料,可以查看我的ITPUB博客,网名chenoracle:
http://blog.itpub.net/29785807/

