前言

Oracle执行计划和SQL快慢息息相关,对数据库调优有着关键作用,了解执行计划的过程,对SQL优化有很大的帮助。 统计信息是为了让Oracle优化器了解数据的信息、数据量的分布情况,便于 CBO能够获得正确的执行计划。选择正确的执行计划,意味着Oracle对于不同的SQL使用更合理的访问路径,使得SQL有更好的性能。
01
ONE
什么是Oracle执行计划
SQL解析过程
一条SQL的执行过程是先进行语法解析(看语法是否正确),然后进行语义解析(查看对象是否存在、是否有对应权限),接着生成执行计划,最后是执行SQL语句,返回用户结果。
SQL解析分为硬解析和软解析。
当用户连接到数据库创建一个会话后,Oracle会分配给用户一个pga区,server process会去SGA的shared pool里的library cache找,有没有执行过相同的SQL,查看是否有相同的执行计划。
如果有则重用执行计划,根据执行计划去database buffer cache里找到匹配的数据。
如果没有,server process就会到数据文件中读到database buffer chache 再返给用户,这种情况则称之为软解析。
所以大家可以根据情况使用获取执行计划的不同方法。除以上两种方法以外,还有几种不同的方法,在此不一一列举。
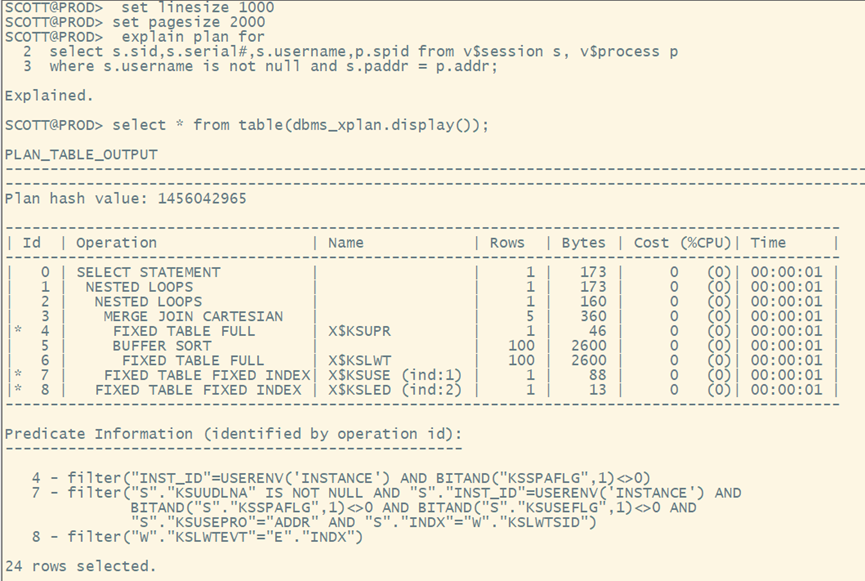
图中SQL行动解释如下:
SQL通过唯一索引检索到满足查询条件的列的ROWID, 这步为INDEX RANGE SCAN(索引唯一性扫描),然后通过查询的ROWID获取得到满足条件的行数据,这步为TABLE ACCESS BY INDEX ROWID。
缩进最多的最先执行,缩进相同时,上面的先执行,下面的后执行。
执行计划的执行顺序如下图所示:

02
TWO
统计信息是描述数据库中表、索引的大小、数据分布状况的信息。
比如表的行数、块数、平均每行的大小、索引字段的行数、不同值的大小等都属于统计信息。
Oracle CBO优化器根据这些统计信息,可以计算出不同访问路径下,各种执行计划的成本,最后选择出成本最小的计划。
统计信息在哪儿
统计信息都是存放在数据字典中,通过查找数据库中视图来获取统计信息,如DBA_TABLES、DBA_INDEXES、DBA_TAB_COLUMNS等视图。
这些视图中包含统计信息的收集情况(如DBA_TAB_COLUMNS的LAST_ANALYZED字段表示上次统计信息收集的时间,这个字段只有收集统计信息之后才有值,否则为空)。
如何收集统计信息
收集表的统计信息:
exec dbms_stats.gather_table_stats(ownname=>'SCOTT',tabname=> 'TEST', estimate_percent => 10,method_opt => 'for all indexed columns');
收集索引的统计信息:
exec dbms_stats.gather_index_stats(ownname=>'SCOTT',indname=> 'TEST', estimate_percent => 10);
收集表与索引的统计信息:
exec dbms_stats.gather_table_stats(ownname=>'SCOTT',tabname=> 'TEST', estimate_percent => 10,method_opt => 'for all indexed columns',cascade => true);
收集数据字典的统计信息:
exec dbms_stats.gather_dictionary_stats(estimate_percent=> 10,cascade=> true,granularity=>'all');
这里面有几个参数可以了解一下:
ownname:表的拥有者。
tabname:表名。
estimate_percent:采样行的百分比,设置过高速度会很慢,设置过低可能会不准确,如设置为null为全部分析。
degree:(可选参数)并行度,默认值为null。
cascace:是否收集索引,列统计信息,默认为false。

查看统计信息收集情况(空为没有相关统计信息):

收集此表的统计信息:


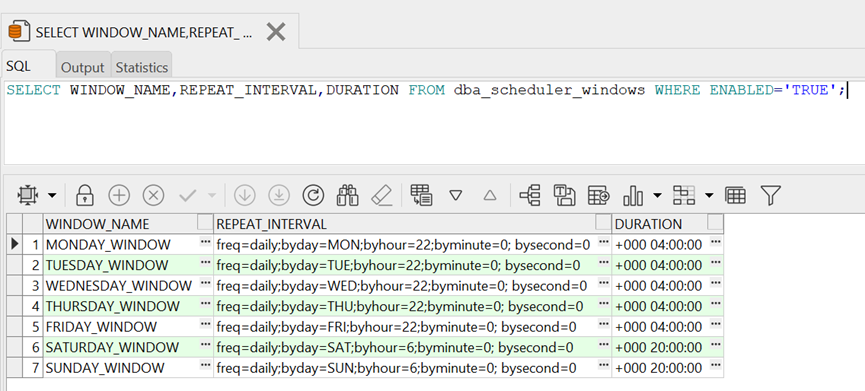
查看自动收集统计信息是否开启:
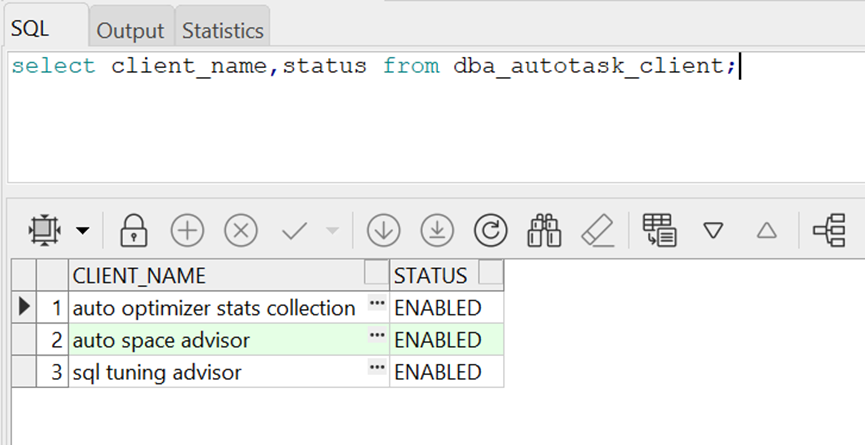
查看统计信息收集情况:
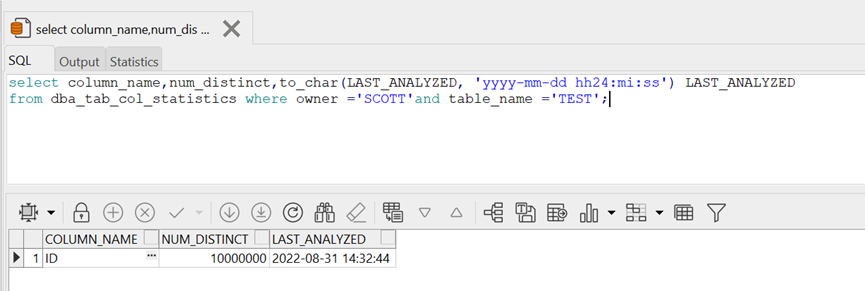
查看收集统计信息的具体时间:
以上是统计信息与执行计划的分享,希望可以帮助到大家。