




Oracle数据倾斜导致的问题-无绑定变量
参考整理---<<恩墨年货-SQL与性能优化>>

数据倾斜即表中某个字段值不均匀,那么什么叫字段值不均匀呢?
如下t1表的object_id字段值就是严重的字段值不均匀,t1表有290020条数据,其中object_id值1到9每个值只有一条记录,object_id=10的值有290011条数据。
SQL> select object_id,count(1) from t1 group by object_id order by 1;
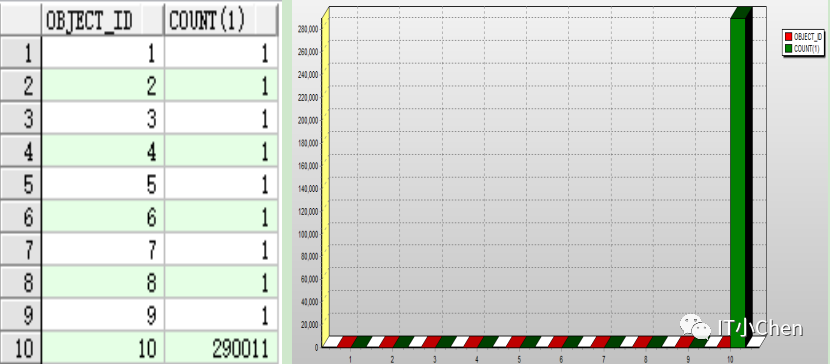
在这种情况下,当以object_id字段为过滤条件时,在某些场景下可能会出现性能问题。
场景一:未使用绑定变量
1 创建测试数据
SQL> select banner_full from v$version;
BANNER_FULL
--------------------------------------------------------------------------------
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 CJCPDB READ WRITE NO
SQL> conn cjc/cjc@cjcpdb
Connected
新建测试表 t1:
SQL> create table t1 as select * from dba_objects;
创建索引:
SQL> create index idx_t1_01 on t1(object_id);
增加数据:
SQL> insert into t1 select * from t1;
/
SQL> update t1 set object_id=rownum;
更新数据,使用数据分布不均匀:
SQL> update t1 set object_id=10 where object_id>10;
290010 rows updated.
SQL> commit;
Commit complete.
SQL> select object_id,count(1) from t1 group by object_id order by 1;
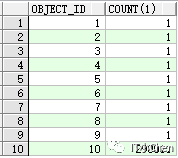
当数据分布不均匀的字段做为过滤条件或连接条件时,如果据分布不均匀的字段没有收集直方图可能会有问题,在没有收集直方图的情况下,这个字段的过滤性 DENSITY 都是等于1/NUM_DISTINCT;
2 对测试表t1进行统计信息收集
收集时指定不收集字段object_id的直方图:
begin
dbms_stats.gather_table_stats('CJC',
'T1',
method_opt => 'for columns object_id size 1',
cascade => true);
end;
3 查看T1表上Object_id列没有收集直方图信息
select table_name,
column_name,
histogram,
num_distinct,
density,
last_analyzed
from user_tab_col_statistics
where table_name = 'T1'
and column_name = 'OBJECT_ID';

4 以object_id列为过滤条件,对比结果集相差悬殊的两次查询操作的执行计划
(1)查看结果集少的执行计划
object_id=1时结果集只有1条数据
SQL> set autotrace traceonly
SQL> set linesize 200
SQL> set timing on
SQL> select * from t1 where object_id=1;
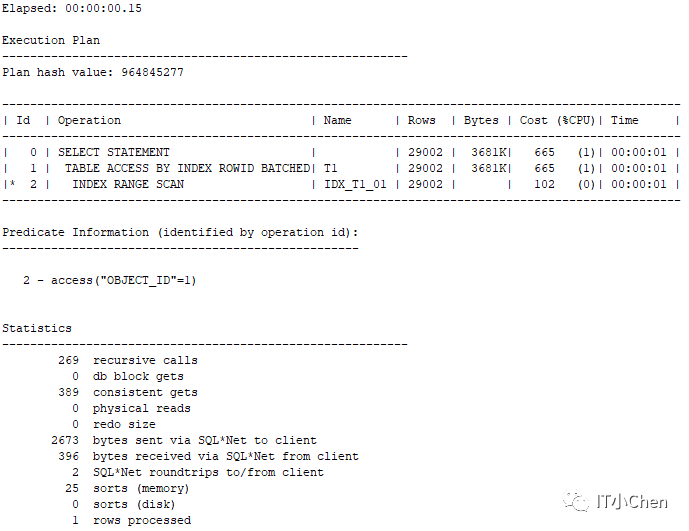
(2)查看结果集多的执行计划
object_id=10时结果集有290011条数据
SQL> select * from t1 where object_id=10;
290011 rows selected.
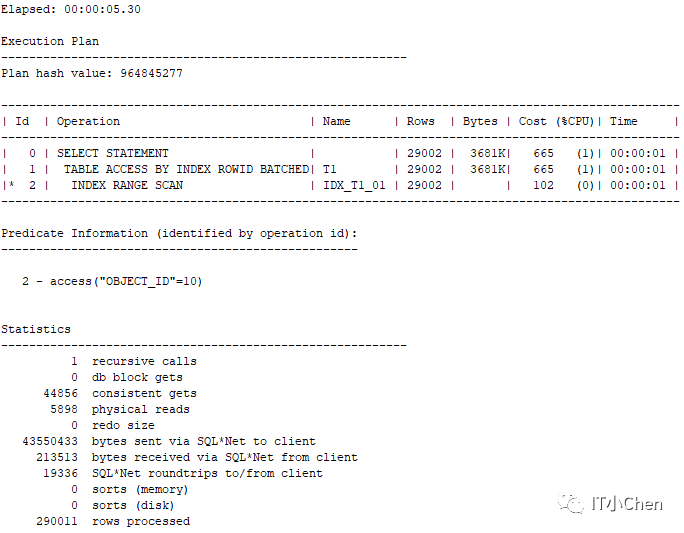
从上图可以看出,两条 SQL 的 PLAN_HASH_VALUE 是一样的,走了相同的执行计划。
select sql_text, sql_id, plan_hash_value
from v$sql
where sql_text like 'select * from t1 where object_id%';

SELECT SQL_ID,
PLAN_HASH_VALUE,
LPAD(' ', 4 * DEPTH) || OPERATION || OPTIONS OPERATION,
OBJECT_NAME,
CARDINALITY,
BYTES,
COST,
TIME
FROM V$SQL_PLAN
where PLAN_HASH_VALUE = '964845277';

显然在object_id=10时,结果集有290011条数据,占比总表99.99%的数据量,不适合走索引范围扫描,全表扫描会更高效些。
5 收集OBJECT_ID列直方图信息
在Oracle中直方图是一种对数据分布质量情况进行描述的工具。
它会按照某一列不同值出现数量多少,以及出现的频率高低来绘制数据的分布情况,以便能够指导优化器根据数据的分布做出正确的选择。正确的直方图,将会对优化器做出正确的选择发挥巨大的作用,使得SQL语句执行成本最低,从而提升性能。
--下面收集字段 OBJECT_ID 的直方图:
SQL>
begin
dbms_stats.gather_table_stats('CJC',
'T1',
method_opt => 'for columns object_id size auto',
cascade => true);
end;
查看直方图信息:
select table_name,
column_name,
histogram,
num_distinct,
density,
last_analyzed
from user_tab_col_statistics
where table_name = 'T1'
and column_name = 'OBJECT_ID';

select *
from user_tab_histograms
where table_name = 'T1'
and column_name = 'OBJECT_ID';

6 重新执行 SQL,查看执行计划
(1)结果集少的执行计划
SQL> select * from t1 where object_id=1;
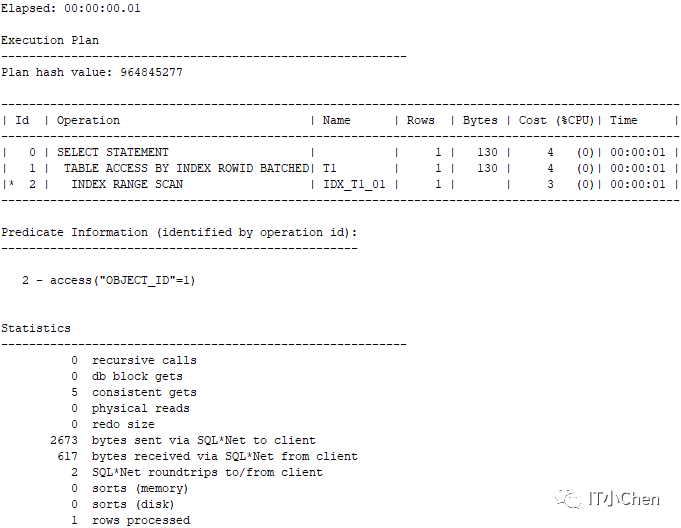
(2)结果集多的执行计划
SQL> select * from t1 where object_id=10;
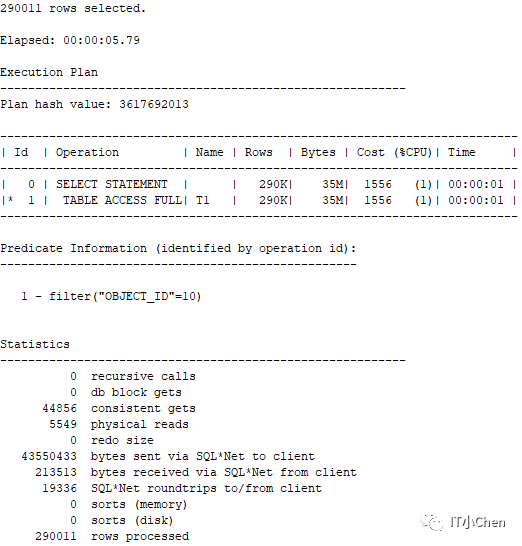
查看结果集多的SQL执行计划已经发生了变化,执行了更高效的全表扫描。
select sql_text, sql_id, plan_hash_value, address, hash_value
from v$sql
where sql_text like 'select * from t1 where object_id%';

注意:
有几种情况,在收集直方图后,执行计划不会马上变化
一:SQL的CURSOR没有失效,不会重新生成执行计划,可以通过如下方法让SQL的CURSOR失效。
(1)在收集统计信息时,指定参数 no_invalidate => false,使这两条 SQL的CURSOR失效,进行重新解析。
我们通过以下存储过程将这两个 CURSOR 清除,这样再执行就会重新解析了。
---填写ADDRESS和HASH_VALUE值
BEGIN
DBMS_SHARED_POOL.PURGE('000000006EBF2F78,589030732', 'C');
DBMS_SHARED_POOL.PURGE('000000006F2B3660,2332556305', 'C');
END;
(2)在收集统计时,加 no_invalidate => false 参数
begin
dbms_stats.gather_table_stats('CJC',
'T1',
method_opt => 'for columns object_id size 1',
cascade => true,
no_invalidate => false);
end;
(3)刷新整个share pool(生产环境谨慎使用)
alter system flush shared_pool;
(4)对这个表做 ddl 操作或授权或添加改变注释等。
例如:
comment on column CJC.T1.OBJECT_ID is 'PK_T1_OBJECT_ID';
comment on column CJC.T1.OBJECT_ID is '';
二:数据库 cursor_sharing 参数的值是否为 exact,如果参数的值为 force,相当于使用绑定变量,收集直方图后,执行计划可能没有变化,解决办法请参考下一节Oracle数据倾斜导致的问题-有绑定变量

