





TroubleShooting :
解决Abort connections问题
问题说明:
通过CloudWatch日志组/aws/rds/cluster/wallet-mysql/errorwallet-mysql,关注到数据库后台报出大量通信错误和中断连接的情况。
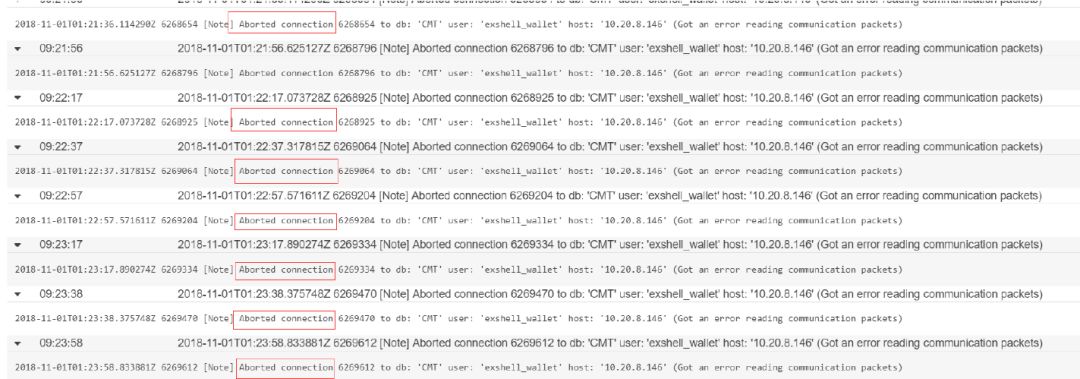

定位数据库后台系统参数:可以看到aborted clients会随着告警的增加而不断增加。
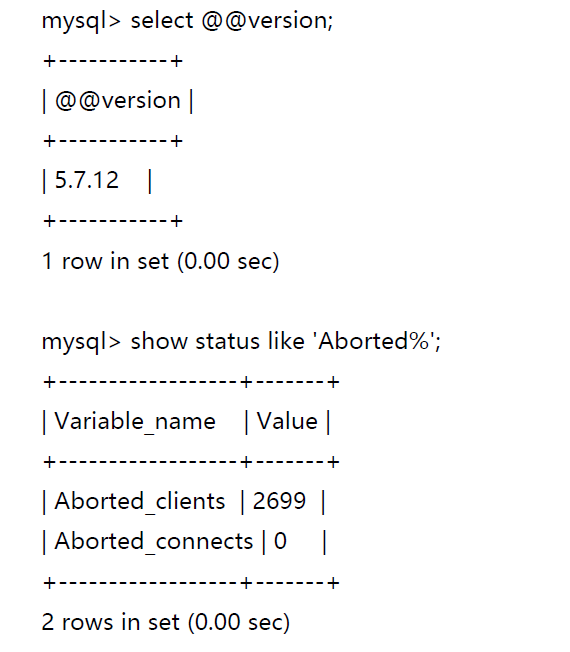

预测一下,下次可能发生该预警的时间:
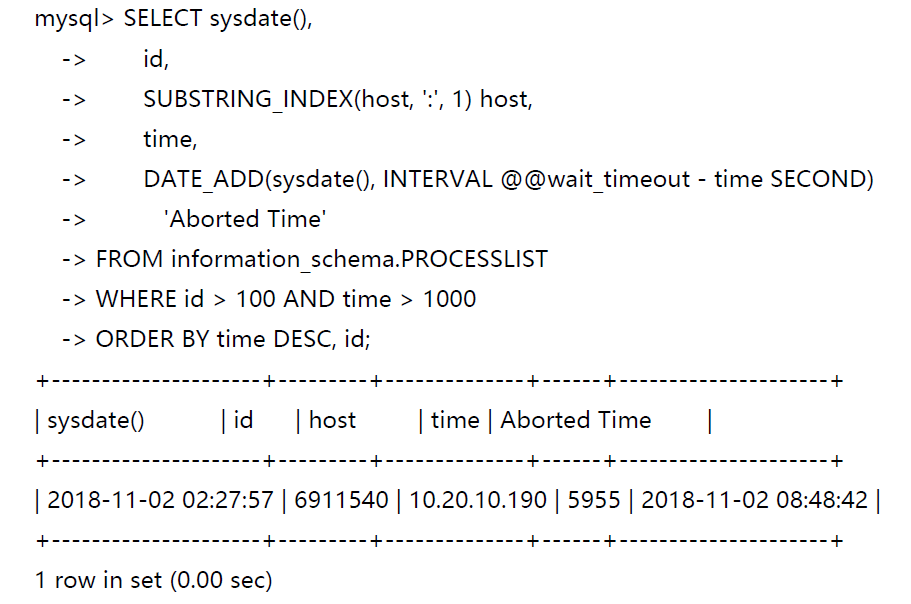

工作原理分析:

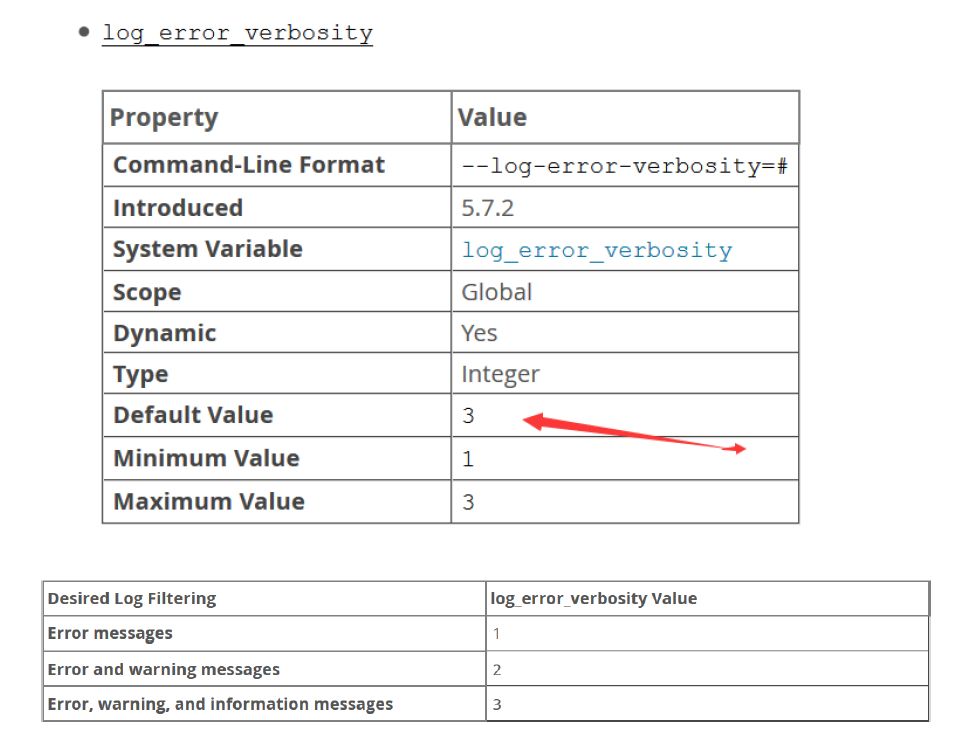
1)如果服务器将log_error_verbosity变量设置为3,可能会在错误日志中找到这样的消息。
2)参考mysql官网参数说明:在错误日志中写入错误、警告消息的服务器的冗长性。下表显示了允许的值。默认值是3。
3)如果客户端甚至无法连接,服务器将增加aborted_connections状态变量。不成功的连接尝试可能发生以下原因:
💛 客户机尝试访问数据库,但没有数据库的权限。
💛 客户端使用错误的密码。
💛 连接包不包含正确的信息。
💛 获取连接包需要的时间超过connect_timeout秒。

4) 如果客户端成功连接,但后来连接不正确或终止,服务器将增加Aborted_clients状态变量,并将中止的连接消息记录到错误日志中。
原因可以是以下任何一种:
💛 在退出之前,客户机程序没有调用mysql_close()。
💛 客户机休眠的时间超过了wait_timeout或interactive_timeout秒,而没有向服务器发出任何请求。
💛 客户端程序在数据传输过程中突然终止。
5)Aborted connections的其他可能性:
💛 max_allowed_packet变量值太小,或者查询需要的内存比为mysqld分配的要多。
💛 在Linux中使用以太网协议,包括半双工和全双工。一些Linux以太网驱动程序有这个
bug。应该通过在客户机和服务器机器之间使用FTP传输一个巨大的文件来测试这个bug。如果传输进入崩溃暂停崩溃。
暂停模式,那么就表示正在经历Linux双工综合症。将网卡和集线器/交换机的双工模式切换为全双工或半双工,并测试结果以确定最佳设置。
💛 线程库中导致读时中断的问题。
💛 严重的TCP / IP配置。
💛 有缺陷的以太网、集线器、交换机、电缆等等。只有通过替换硬件才能正确诊断。

解决办法:
1)使用netstat n| grep 3306。在time_wait中有很多连接。mysqld。日志收到一个错误,读取通信数据包被记录。参数/proc/sys/sys/net/ipv4/tcp_tw_reuse和/proc/sys/net/ipv4/tcp_tw_recycle改为1,问题解决了。
2)set global log_error_verbosity=2;将此参数的缺省值降低。

备注说明:
1)服务器参数设置可以参考如下文档连接:
https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html
2)错误日志参考如下文档连接:
https://dev.mysql.com/doc/refman/5.7/en/error-log.html
3)通用查询日志参考如下文档连接:
https://dev.mysql.com/doc/refman/5.7/en/query-log.html


点亮梦想,照亮平庸

