





引言
下马看花-redo

伟大领袖毛主席在《在鲁迅艺术学院的讲话》中说过这样一段话:俗话说,走马看花不如驻马看花,驻马看花不如下马看花,我希望你们都要下马看花。是的,有时候技术学到一定阶段,很多细节知识确实需要我们 穷波讨源,细致的研究,今天和大家聊得是alert 日志中出现Private strand flush not complete提示,这提示背后的故事。
背景介绍


以下截图为简单的QQ沟通
初步了解DBA排错思路和现场问题情况

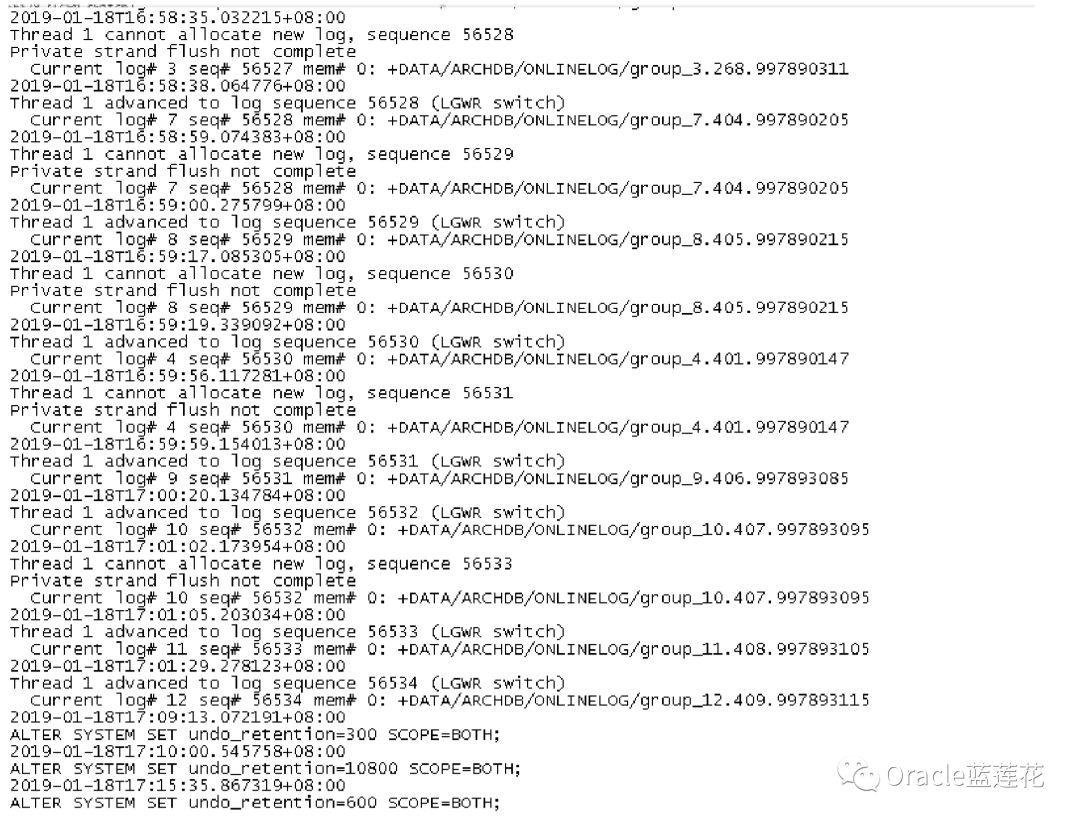
截图2为alert日志中具体的信息提示
截图3为前台应用给出的另一个报错信息
AWR报告信息提示:
 |

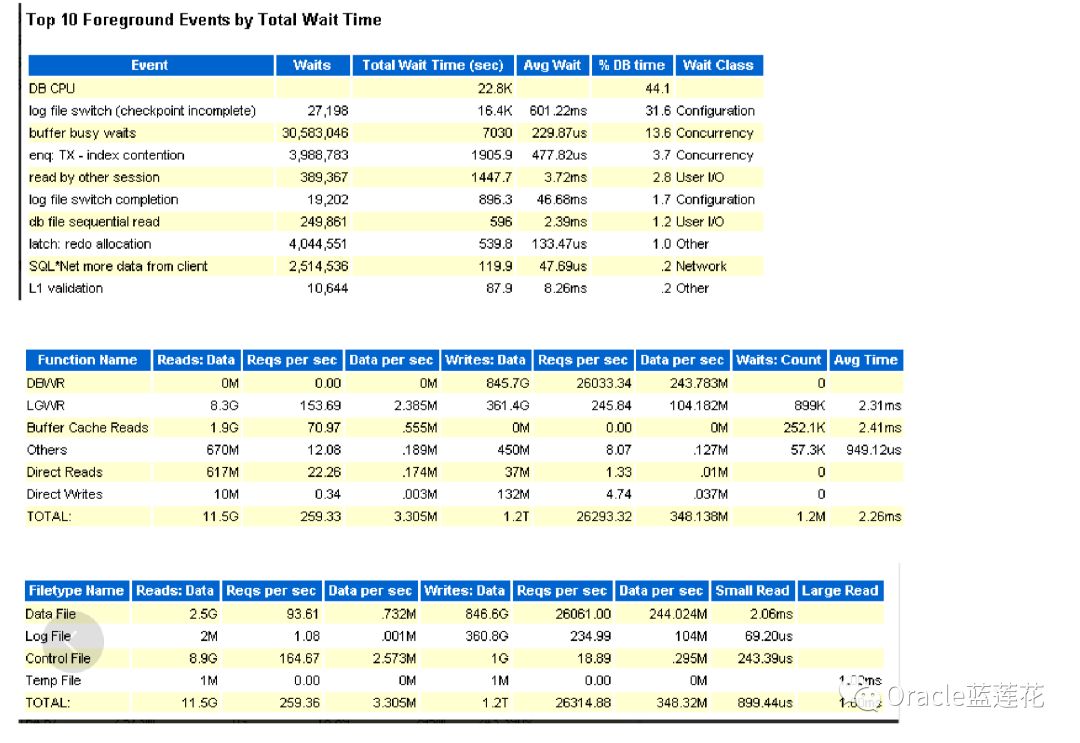
1.对于log file switch (checkpoint incomplete)等待事件,容易误导DBA的排查思路,awr报告里该等待事件平均等待 601.22毫秒,占用当前dbtime 31%,同时db cpu占用dbtime的比例达到41%。这里我们不妨分析这个等待事件产生的成因,log file switch (checkpoint incomplete)指的是当redo需要向下一组redo group切换的时候,发现下组日志是active活动状态的,简单的说就是下组日志中对应的一些buffer cache中的脏块压根没有写入到数据文件中,因此必须等待这些dirty block被flush完毕 后,才可以复用下一组redo group
2.既然是把dirty block flush到datafile,那么自然是dbwn的工作,实际我们需要更多关注的是dbwn这个进程的写io负载情 况,那么awr里有8.3g的控制文件io负载是为什么,其实是DBW本身的io问题导致 LGWR不断查询control 文件获取redo 状态,获 取状态最根本的目的就是想知道究竟redo切换是否成功,所以后台产生大量控制文件io操作。
3.在以前的文章中我们分享过log file sync等待事件,写redo很慢,从而导致gc buffer busy acquire release 等待事件,其 实这个就比较方便定位,只要我们做了addm,可以看到诸如如下的提示:Waits on event “log file sync” were the cause of significant database wait on “gc buffer busy” when releasing a data block. Waits on event“log file sync” in this instance can cause global cache contention on remote instances,那么基本可以确认gc buffer busy的源头是log file sync(虽然本质上不是),那么优先解决log file sync的问题。
|
oracle 9i时代,企业业务数据还没井喷,无论是事务还是日志生成量都相对较少,那个年代没有所谓大数据的概念,基本都 维持在一次变更,一条数据,一次内存分配即可完成的状态,随着企业业务数据激增,尤其oltp系统,老的redo机制已经无法满足 高并发,大写入量的需求,到10g版本以后oracle推出了private redo 和imu,也就是in-memory undo的机制,这样一来,一个 进程就可以以整个事务的方式去工作,生成所有的改变向量,并将它们存入私有重做日志缓冲区,也就是private redo log buffer 中,当事务提交时,进程将存于私有重做日志缓冲区的记录复制到公共的重做日志缓冲区,这时,跟传统的重做日志缓冲区工作原 理保持一致,那么写到重做日志文件的过程,一个进程在一个事务里只需要获得一次公共的redo allocation latch,而不是每次变 更都要获取一次latch。
既然是下马看花,为了方便大家理解,我们至少要搞懂几个事情,才能做到真正意义的赏花望月,imu机制带来的in memory undo latch是否影响数据库负载,是否有威胁,同时分析重做日志文件,搞清楚redo entry都记录了什么,同时我们还要 分析x$kcrfstrand x$ktifp理解各种实例活动信息之间的关联关系,这里涉及的技术知识点比较多,由于篇幅原因,和大家分享两个 相对重要的:
1. 关于redo方面增量的基础结构由两组内存结构组成,一组是x$kcrfstrand私有redo区域,主要处理前滚改变向量, 另一组x$ktifp imu区域,处理undo改变向量,私有redo区域里面也包含传统的公共重做日志缓冲区,因此如果查询这个固化视图 发现有两类不同的信息,不要担心,是正常现象。
2. x$ktifp表示imu区域中的池个数,取决于持有事务的细节v$transaction的数组大小,它由oracle的参数 transactions设定,但是这个参数通常随session 或者processes参数调整自动更新,基本上,池的个数默认为transactions/10,比 如transactions是1000,那么池的个数就是100,每个池是由自己的imu latch受保护的。
3. x$ktifp中的每一条记录在x$kcrfstrand中都有与之对应的一条私有redo记录,不过x$kcrfstrand还会涉及其他信 息,公共的redo记录个数由cpu_count参数决定,算法是ceiling(1 + cpu_count/16)
4. x$kcrfstrand中的每一条私有重做记录都由自身的redo allocation latch来保护,每一条公共的重做记录都由传统 的redo copy latch保护,每个cpu一个redo copy latch
|


根据oracle官方介绍为了减少redo allocation latch等待,在oracle 9i中,引入了log buffer的并行机制。其基本原理就 是,将log buffer划分为多个小的buffer,这些小的buffer被成为strand(为了和之后出现的private strand区别,它们被称之为 shared strand)。
每一个strand受到一个单独redo allocation latch的保护。多个shared strand的出现,使原来序列化的redo buffer分配变成了并行的过程,从而减少了redo allocation latch等待。shared strand的初始数据量是由参数log_parallelism控 制的;
在10g中,该参数成为隐含参数,并新增参数_log_parallelism_max控制shared strand的最大数量; _log_parallelism_dynamic则控制是否允许shared strand数量在_log_parallelism和_log_parallelism_max之间动态变化,这里需
要注意_log_parallelism在12c版本已经弃用
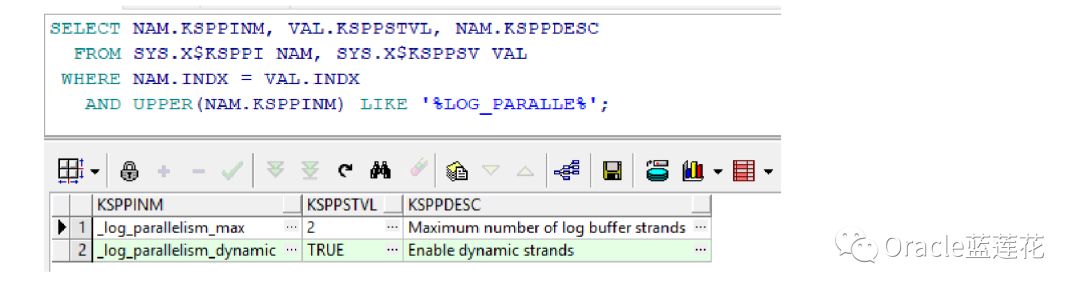
每一个shared strand的大小 = log_buffer/(shared strand数量) 关于shared strand的数量设置,16个cpu之内最大默认为 2,当系统中存在redo allocation latch等待时,每增加16个cpu可以考虑增加1个strand,最大不应该超过8。并且 _log_parallelism_max不允许大于cpu_count

Oracle 日志缓冲区7条原则
计算日志缓冲区需要多少空间。
服务器进程获取重做复制锁存器。这用于通知将一些重做复制到日志缓冲区中。
获取重做分配锁存器。这是实际的锁存器,它将分配日志缓冲区中的空间。
日志缓冲区获取空间后释放重做分配锁存器。
Redo copy latch用于复制日志缓冲区中的Redo更改向量。
释放重做复制锁存器。
在复制完成并在缓冲区缓存中的缓冲区上应用它们之后,根据不同的条件,LGWR可能会开始将内容写入日志文件中。从 V$latch_childeren 可以看到我们的数据库目前有多少个锁存。这是我的12c机器的输出


插播广告,来看一个实验





实验小结:
1、即使我们尝试了insert,也没有标记为dirty的缓冲区。Oracle确实获得了一些buffer来保存我们的更改,但是它们没有被标 记为dirty。但当我们发出commit时,所有缓冲区都被标记为dirty。为什么
2、这就是刚才工作原理,以及概念介绍的IMU/ Private Redo Strands机制
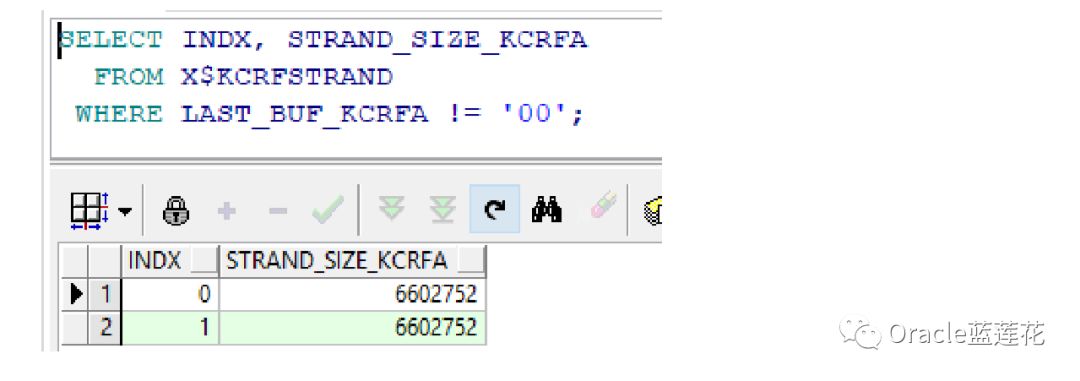
3、与Oracle需要保护重做的原因相同,它还必须保护Undo,以确保块的旧内容也被保存。这将需要访问块,并在稍后更改事 务表以记录更改。交易记录可以从V$transaction中看到。为了直接访问undo段头块,我们还可以检查X$KTUXE,对于 V$transaction的基表,可以使用X$KTCXB。从oracle 10g开始,oracle确实使用了Undo块,但是在专门创建的私有内存区域中可 以使用它们


正如刚才我们介绍的,每个池由一个锁存器维护,这个锁存器称为in memory undo latch。可以从V$latch_children中看到它们

工作原理不变,我们还可以在共享区域看到内存结构形态:

---IMU池分配在共享池中。我们更改的数据从内存撤消锁存器中的锁存器复制到这些池中。我们可以从V$latch中看到

----当我们修改数据时,oracle不会立即将数据应用到数据块上,而是通过这个IMU锁将数据分配到共享池中的IMU池中。这种 机制避免了撤销段头块的固定,也避免了在事务启动时立即使用的撤销数据块的固定。现在它们只在事务提交时使用。数据在池 中,只有从池中复制到缓冲区缓存。由于每个池被分配给一个事务,并由一个单独的锁存器维护,IMU池也在X$ktifp中进行了描 述。池的大小为65kb
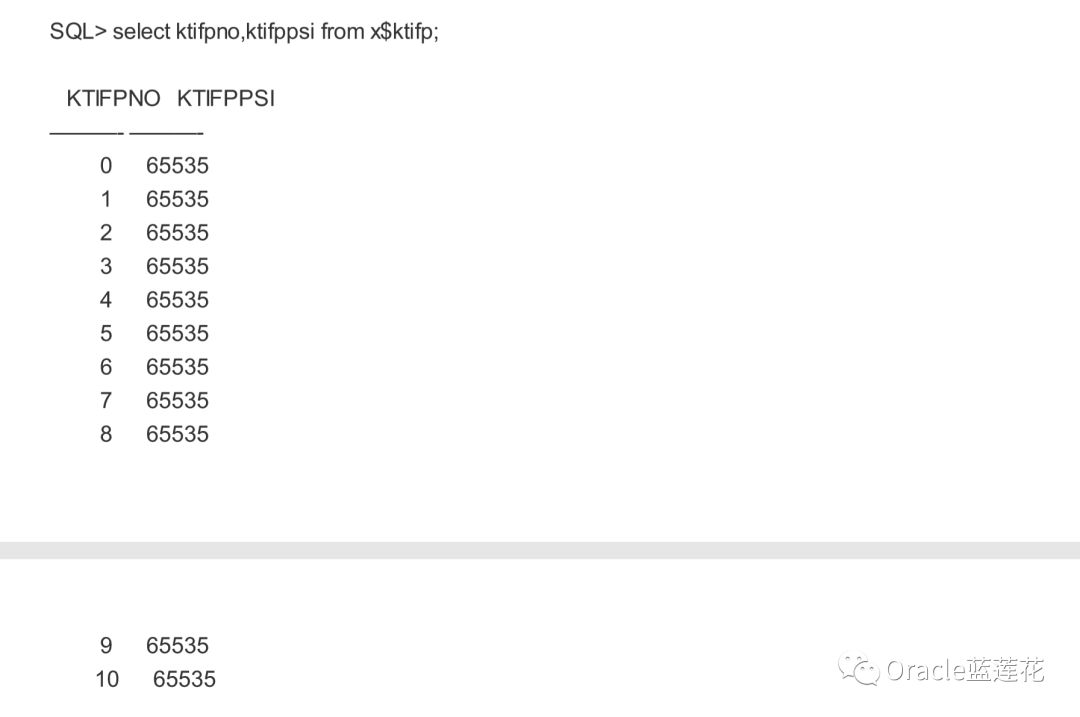
---通过dml操作验证imu的刷新机制





|
No1
查看imu资源信息
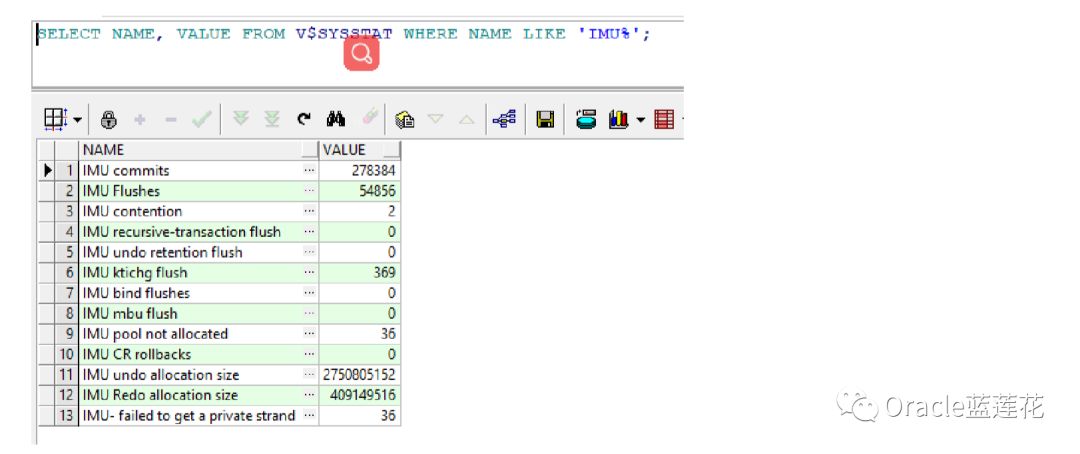
No2
显示已经使用的imu buffer
No3
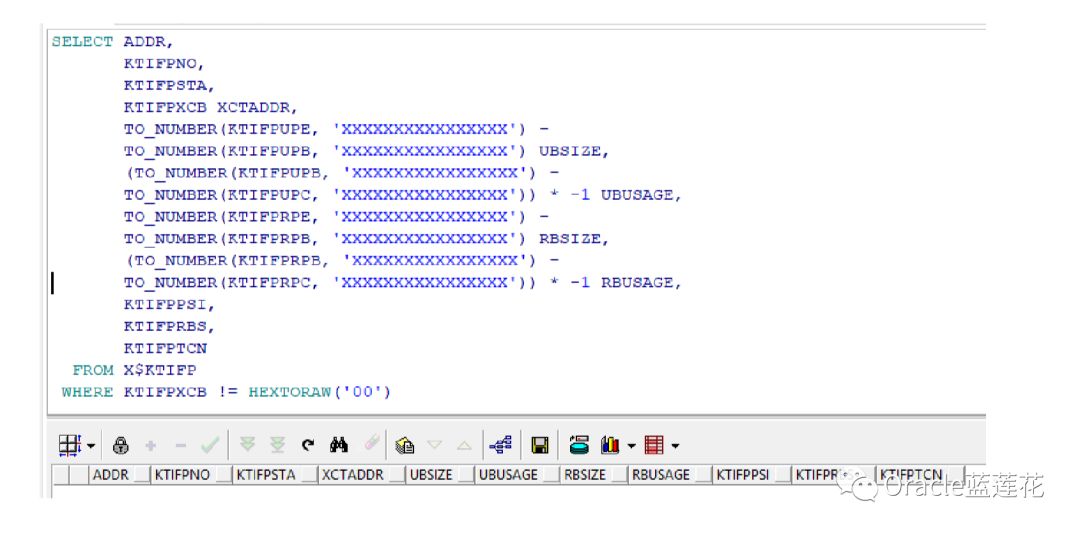
参数_log_private_mul
参数_log_private_mul指定了使用多少logfile空间预分配给Private strand。我们可以根据当前logfile的大小(要除去预分 配给log buffer的空间)计算出这一约束条件下能够预分配多少个Private strand
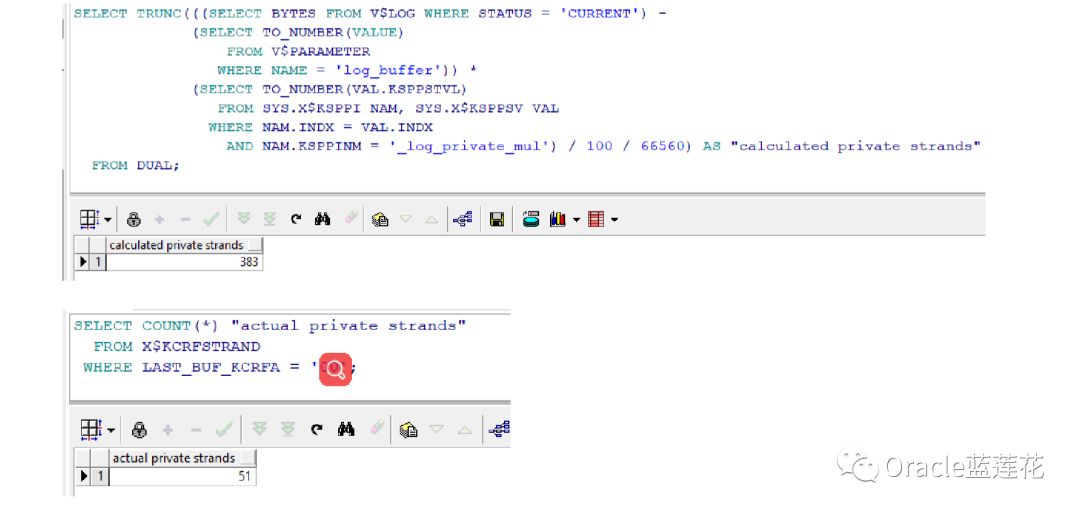
当logfile切换后(和checkpoint一样,切换之前必须要将所有Private strand的内容flush到logfile中,因此我们在alert log中可能会发现日志切换信息之前会有这样的信息:"Private strand flush not complete",这是可以被忽略的),会重新根据切 换后的logfile的大小计算对Private strand的限制
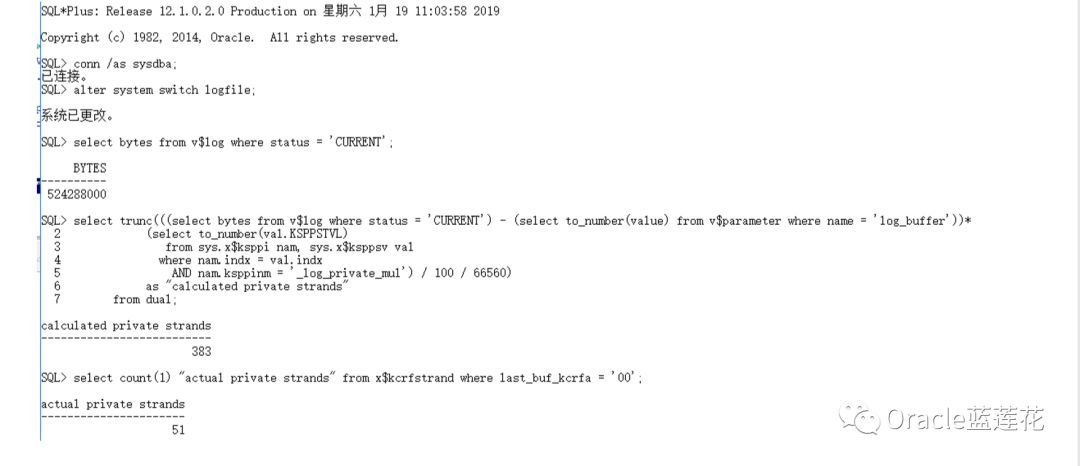
No5
参数_log_private_parallelism_mul用于推算活跃事务数量在最大事务数量中的百分比,默认为10。Private strand的数量不 能大于活跃事务的数量,我们刚才设置最高到383

|
1、
通过工作原理分析我们明确了redo切换日志的时候所有的private strand 都必须刷新到当前日志,然后才能做下一组redo日志切换
2、
当我们看到alert中有诸如Private strand flush not complete提示的时候,其实本质问题就是还没有把所有的redo信息写到 redo日志文件的问题,strand其实就是处理redo的latch,允许进程利用多个 allocation latch 更高效地将 redo 写入 redo 缓冲区 的机制
3、
同时我们通过数据字典验证了解到初始分配的 strand 数量取决于 CPU 的数量,最少两个 strand,其中一个 strand 用于活 动的 redo 生成
4、
那么什么情况下我们需要关注这个问题呢,正常情况都是无需关注的,除非cannot allocate new log信息和advanced to log sequence信息之间有明显的时间差
5、
通过和现场DBA了解,当前redo设置为200m,分3组,这套库偏olap类型,有大事物串行写入操作,DBA介入调整了redo 日志组大小,后期继续关注。
6、
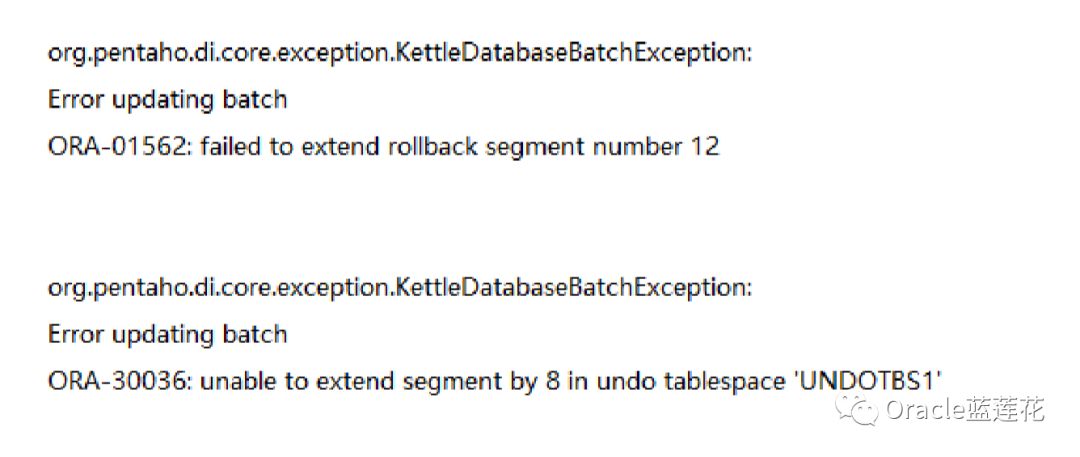
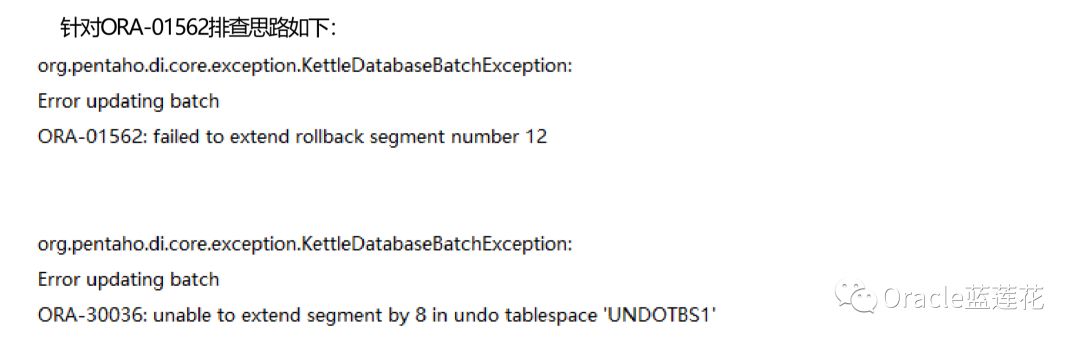
oracle mos提供了一个诊断助手的工具,帮助我们定位ORA-01555, ORA-30036, ORA-01628, ORA-01552报错信息,详 细的可以参考document :1575667.2

ORA-01562官方解释如下:

7、
表空间没有足够的连续空间来允许回滚/撤消段的扩展。当下一个区段大小大于最大的连续空间时,将引发扩展失败错误。 只有当对象试图扩展时,没有足够的可用连续空间时,才会生成此错误
ORA-01562排错思路
1、首先查询出可用的最大连续空间 select max(bytes) from dba_free_space where tablespace_name = 'UNDOTBS1';
2、默认情况下pct_increase为0,我们基于select next_extent, pct_increase from dba_rollback_segs where segment_name = segment number 12的名称;查询
3、尝试手动的合并相邻的空闲区段Alter tablespace XX coalesce;
4、尝试添加新的数据文件Alter tablespace XX add datafile .... size ...
5、尝试resize操作Alter database datafile XX resize XX;
6、在手动模式下,可以尝试设置事务用户回滚段,强制大型事务使用大型回滚段,以克服ORA-1562。用户事务记录在回滚段 中。在用户提交更改之前,事务在回滚段中保持打开状态。SET TRANSACTION USER ROLLBACK SEGMENT
7、SET TRANSACTION USE ROLLBACK SEGMENT不会强制DDL使用特定的回滚段。它只对DML有效
|


总结
汇报人:ORA-00600



1、我们所做的任何一个改变都会产生一次对imu latch的访问,这并不意味大的latch争用,因为oracle只是用一个imu latch代 替了redo allocation latch和redo copy latch,所以理论上,至少将latch竞争减少了一半。imu latch有很多子latch,每个latch负责一个imu的内存区域池,这里我没做过更细致的研究。
2、同时我们也了解到新机制两种redo allocation latch机制,一类为保护私有redo线程也就是private redo thread,另一类保 护公共的redo线程,也就是public redo thread,每个线程都有自己的latch。
3、对于Private strand flush not complete提示更多无需关注,此信息表示我们在尝试切换时,尚未完全将所有 redo 信息写 入到日志中。它本质上类似于checkpoint not complete,不同的是,它仅涉及到正在被写入日志的redo。在写入所有 redo 前, 无法切换日志。
——如人饮水冷暖自知
雁过留影,爱过留心
LOVE

一起感受600的温暖,一起感受数据库的魅力
扫描如下QQ群二维码,加入600团队
分享创造价值,分享创造快乐

