




2018-09-28



Oracle 12c cbo优化器改变知多少
引言
北京的天气的就像小孩的脸,一时一个变。小孩还好,一颗糖能哄好,这天气真是日了狗了。言归正传,今天来和大家聊聊oracle 12c版本中,优化access path访问路径的新执行计划指标,希望通过这篇文档能够帮到各位更深入的了解12C在cbo优化器层面一些变化。文章很短,请耐心看完。

1.1 rowid 是什么
rowid是数据存储位置的内部表示。行的rowid指定数据文件和数据块,其中包含行和该块中该行的位置。通过指定rowid来定位一行是检索单个行最快的方法,因为它指定了数据库中该行的确切位置
注意:
Rowids可以在不同版本之间进行更改。个人不建议基于位置访问数据,因为行可以移动
1.2 cbo优化器如何通过rowid访问表
其实在大多数情况下,oracle在扫描一个或多个索引之后通过rowid访问一个表。然而,rowid访问表不需要跟踪每个索引扫描。如果索引包含所有需要的列,那么rowid可能不会进行访问,这里涉及到index fast full scan的知识,索引扫描不在我们讨论的范围内,所以index fast full scan这里我们不做解释。
那么rowid如何访问表的呢?
首先从语句WHERE子句或通过对一个或多个索引的索引扫描获得所选行的rowids,同时对于索引中不存在的语句中的列,可能需要表访问。然后根据表的rowid查找表中所选的每一行。

1.2.1 一个简单的例子
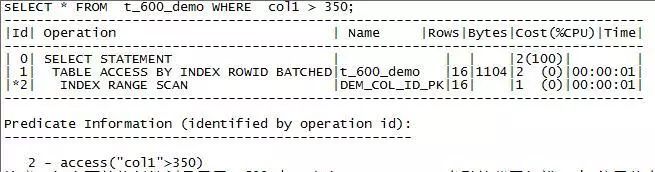
注意:
1.上面的执行计划显示了t_600_demo表上DEM_COL_ID_PK索引的范围扫描。cbo使用从索引中获得的rowid从t_600_demo表中查找相应的行,然后检索它们。
2. 执行计划第1步中显示的批处理访问意味着cbo从索引中检索几个rowid,然后尝试按块访问行,以改进集群并减少数据库必须访问块的次数。这就是今天我们要和大家聊得TABLE ACCESS BY INDEX ROWID BATCHED指标
1.2.2 再来看一个例子
我们直接就用HR用户的EMPLOYEE表
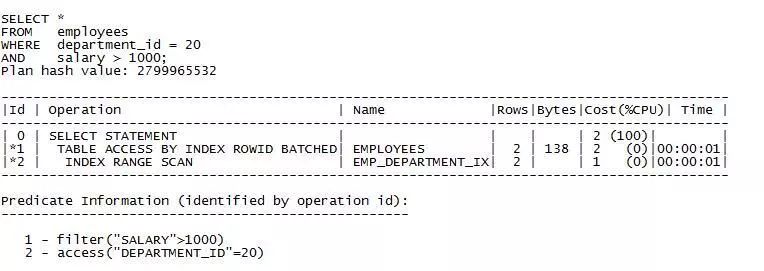
注意:
当前查询cardinality基数很低(返回的行很少),因此查询使用department_id列上的索引。cbo首先扫描索引,从employees表中获取记录,然后对这些获取的记录应用 salary > 1000 filter 过滤器来生成最终的结果

2.1 skip index
索引跳过扫描逻辑上将复合索引分割为更小的子索引。
注意:
索引的前列中不同值的数量决定了逻辑子索引的数量。数量越少,优化器必须创建的逻辑子索引就越少,扫描的效率就越高。扫描将分别读取每个逻辑索引,skip不满足非前导列过滤条件的索引块。
我们假设一种场景,customers表包含一个cust_gender列,其值为M或F.然后我们在列(cust_gender, cust_email)上创建一个复合索引如下:
CREATE INDEX cust_gender_email_ix ON sh.customers (cust_gender, cust_email);
我们执行了这样一笔查询:
SELECT * FROM sh.customers WHERE cust_email = 'Abbey@company.example.com';
执行计划如下:
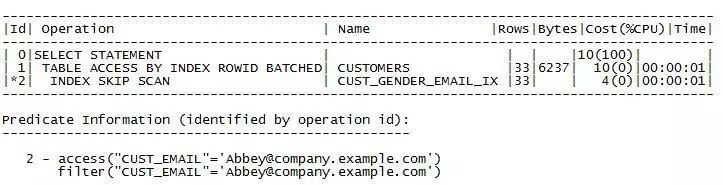
注意:
1.cbo可以使用customers_gender_email索引的跳过扫描,即使在WHERE子句中没有指定cust_gender。在示例索引中,第一列cust_gender有两个可能的值:F和m。 一个子索引的键为F
2.在查找邮件为Abbey@company.com的客户的记录时,数据库首先用前导值F搜索子索引,然后用前导值m搜索子索引
3.注意,其他索引形态不做演示了,大同小异。

下面我们通过一个综合案例来验证之前的理论
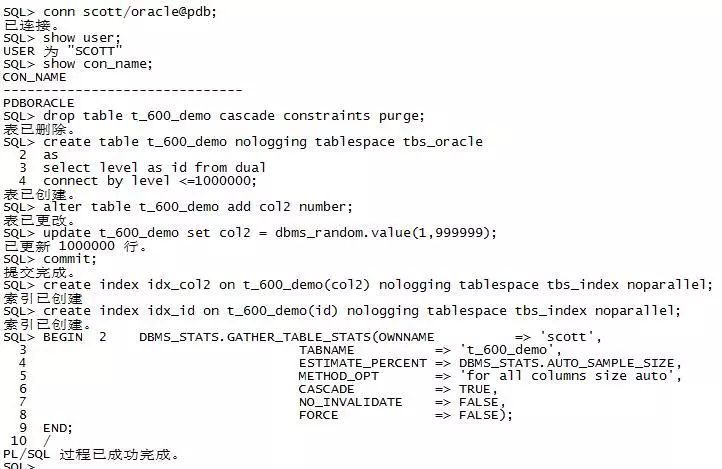
3.1 初始化环境准备
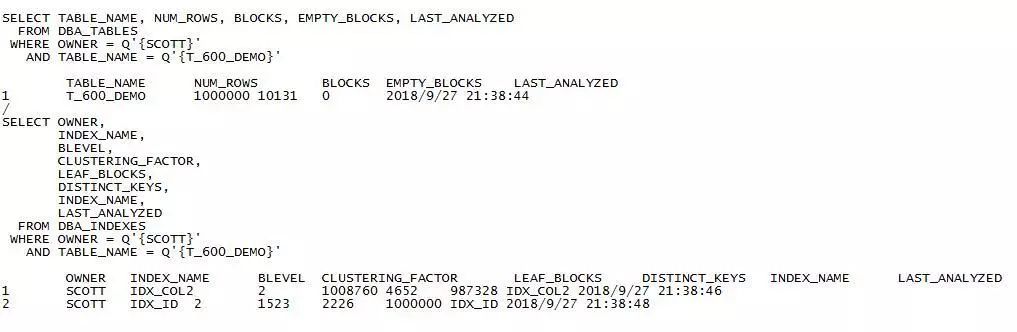
3.2 数据字典验证信息
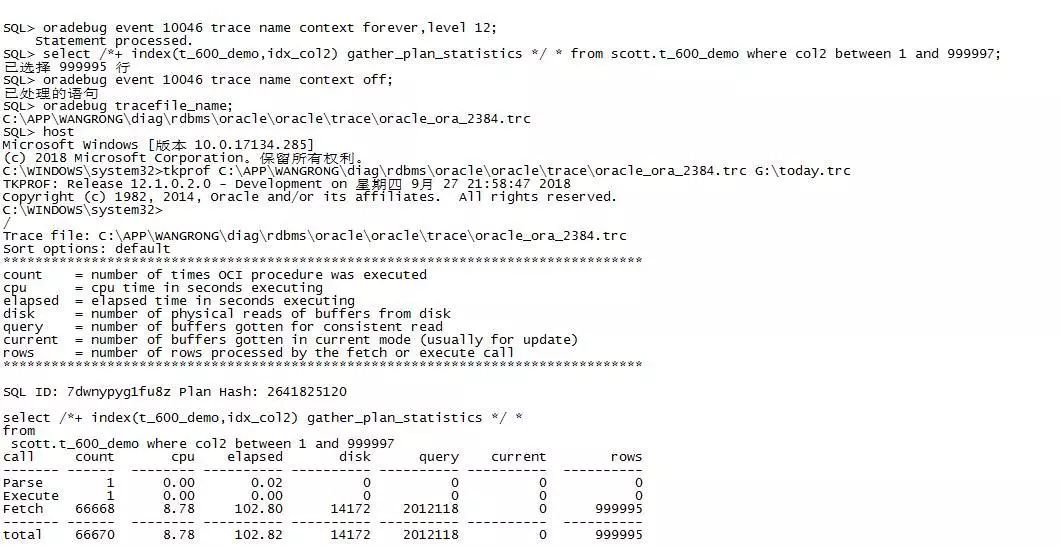
3.3 10046输出
注意:
利用rowid batch方式产生的运行时间(以秒为单位)是102.82秒,磁盘缓冲区产生的物理读是14172,一致性读取的缓冲区数达到了2012118

注意:
1.TABLE ACCESS BY INDEX ROWID BATCHED部分产生逻辑读数据块2012118,物理读数量达到14172,time=95985905,注意这个指标是百分分之一秒,也就是95秒
2.优化器成本是1013937,评估的数据源大小,单位为字节25.7M左右。同时产生了一笔硬解析。
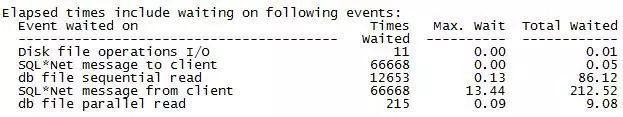
注意:
1.db file parallel read 物理读等待事件涉及到的数据块均是不连续的、同时还可以跨越Extent,这点不像db file scattered read
2.db file parallel read 等待事件是Oracle 可以对多个数据文件实施并行地物理读取并加载到不连续的内存空间中(可能是PGA也可能是Buffer Cache)。
该db file parallel read 往往出现在 recovery操作或者 buffer prefetch以优化多个单块读的操作中。
3.对应属性参数如下:
Parameters:
P1files Number of files being requested
P2blocksTotal number of blocks being requested
P3requestsNumber of actual AIO requests
4.从10046中我们可以看到总共等待了215次
/

再来看关闭rowid batching功能后,Oracle有怎样的表现。这里我们用另外一种方法。
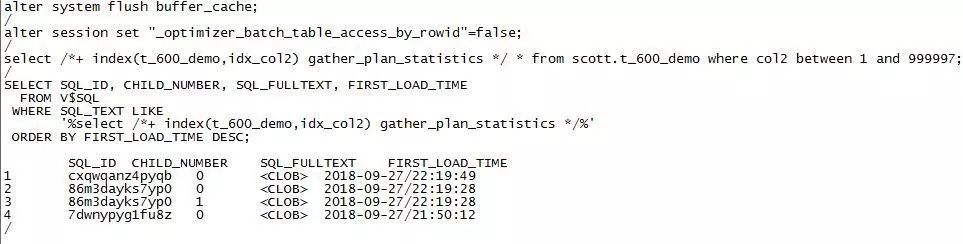
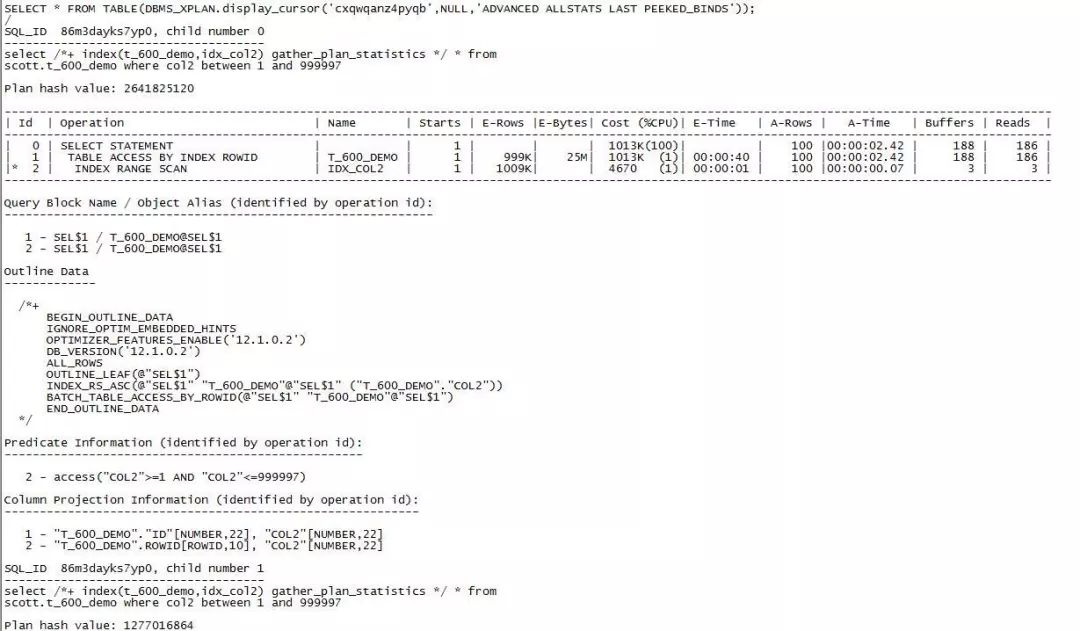

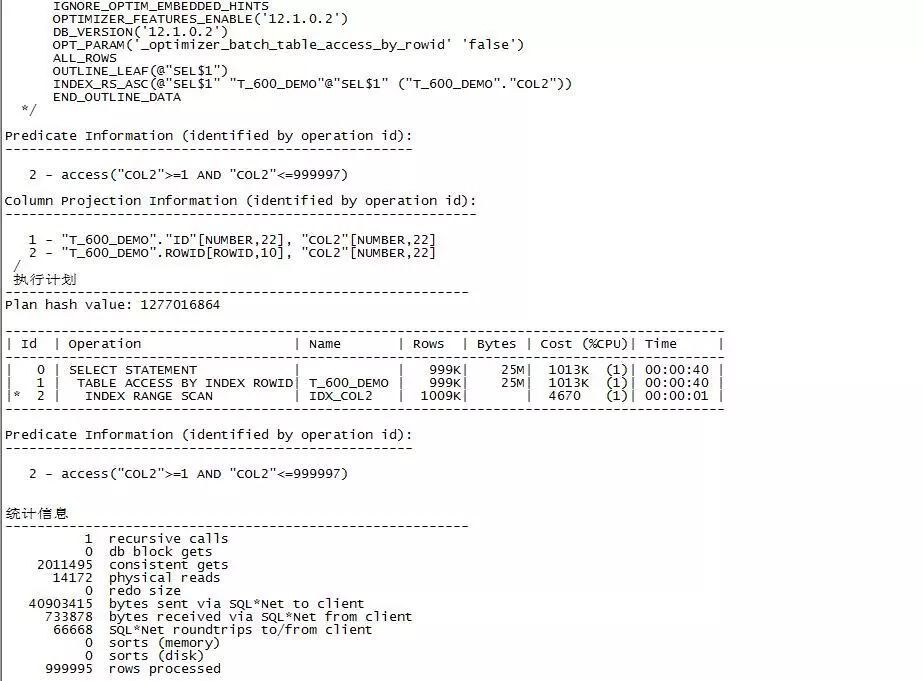
注意:
TABLE ACCESS BY INDEX ROWID方式产生的逻辑读为2011495,物理读为14172,产生了大量sql*net服务端和客户端网络交互行为,从试验上看并没有太多性能提升
可能是笔者本地笔记本的问题。各位可以在服务器级别进行测试演练。

以下对部分工作原理进行总结
1.从本质上讲TABLE ACCESS BY ROWID操作是从index索引中获取ROWID, 以便在表上定位到对应的行fetch对应数据。 若该行不在Buffer Cache中, 则该 Table Access by ROWID需要等待必要的IO完成才能处理下一个ROWID。 在实际的生产环境中IO延迟会成为重要的性能瓶颈,尤其这种索引rowid回表行为,由于不管是RANGE SCAN、FULL SCAN还是Access By Rowid默认均使用DB FILE SEQUENTIAL READ所以如果访问的数据恰巧不在内存里,它要Fetch大量的数据行则 往往其整体相应速度和逻辑读要多于全表扫描
2.oracle使用prefetch预读取数据源来提升性能,通过遍历ROWID以找出那些需要完成的IO操作并prefetch其数据源,将那些数据块预先读入。这里的实现上应当是通过buffer 驱动数据源哪里获得的ROWID,之后通过遍历这些 ROWID对应的的找到需要做物理读的数据块,并使用向量Io操作也就是db file parallel read来prefetch这些数据块到
buffer cache中,这样TABLE ACCESS By ROWID的访问就可以保证必要的块(主要是表块)均在buffer cache中。
3.oracle宣称使用此rowid batching特性可以有效减少IO延迟造成的性能损耗,但并不是任何场景都有效。由于实际能buffer的ROWID是有限的,而且是在不知道哪些 ROWID对应需要IO哪些不需要的情况下全部都复制到buffer中,所以如果buffer的所有ROWID对应只需要少量的IO,则该IO Batching特性带来的性能改善将最小化。
或者遇到的ROWID对应的数据块全部在内存在 一点Io都不需要,则这种prefetch数据的行为就可能成为鸡肋。
4.我们通过一种比较变态的方法为大家演示,几乎返回全部行员的索引利用程度,在这种情况下,其实全表扫描相对更高效。
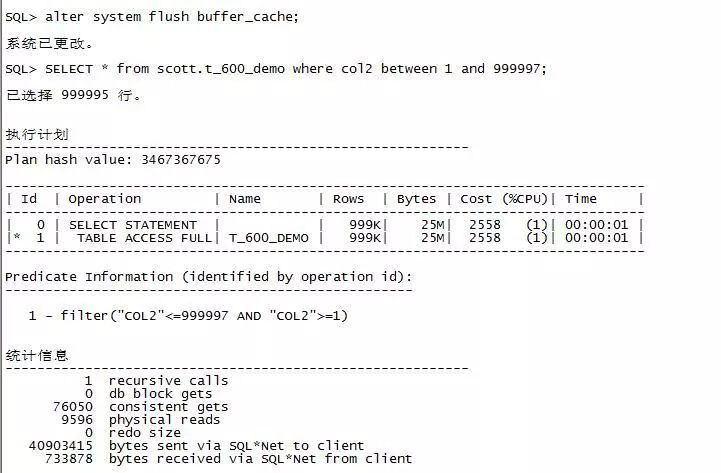
所以,还是那句老话,sql优化需要见招拆招。

6.1 错误的结果说明
6.1.1 执行计划可以包括TABLE ACCESS BY INDEX ROWID BATCHED
6.1.2 执行计划可能包括连接
6.2 描述
6.2.1查询可能产生不正确顺序的行
6.2.2在查询编译期间执行或展开时。
6.3 解决方案
关闭以下两个特性
6.3.1 _optimizer_batch_table_access_by_rowid"=FALSE
6.3.2 _no_or_expansion"=false
注意:
这个bug详细内容大家可以参考Bug 22157363 - wrong sort order with OR-expansion (文档 ID 22157363.8)内容,这里就不做详细介绍了。
.

下面对我们今天的分析做一个总结
1.表访问索引ROWID批处理是12c的一个新的执行计划操作,有助于提高性能。它通常用于范围(>或<)查询。对于这个新操作,Oracle从索引中选择几个rowid,然后尝试访问 块中的行。这大大减少了Oracle访问块的次数,从而提高了性能。
2.例如下面的简化索引示例:
+-------------+------------------+
| index value | block nbr-rowid |
+-------------+------------------+
| 1 | 015-000123 |
| 2 | 034-000527 |
| 3 | 088-000285 |
| 4 | 015-000889 |
| 5 | 088-000632 |
........
........
........
注意:
传统非batching批量处理方式的索引,Oracle按照索引确定的顺序检索行,我们做个推演就明白了:
检索 block 15, 然后从这个块中检索第015-000123行
检索 block 34, 然后从该块检索第034-000527行
检索 block 88, 然后从这个块中检索行088-000285
检索 block 15 :(再次),然后从该块中检索第015-000889行
检索 block 88 :(再次),然后从该块检索行088-000632
以此类推
3. 在批处理方法中,oracle从索引中检索一些条目,然后按照块的数量对它们进行排序,然后按照块的数量的顺序处理条目,例如下面的推演:
检索 block 15, 然后从这个块中检索行015-000123和015-000889
检索 block 34, 然后从该块检索第034-000527行
检索 block 88, 然后从这个块中检索行088-000285和088-000632
4.这样一来数据块只被读取了3次,而不是5次,因此从磁盘读取的块数减少了一些,基本的工作原理就是这样的。

长按识别左侧二维码,加入我们
点亮梦想,拒绝平庸
ORA-600 QQ群 851604218
