




ORA-00600欢迎您
长按识别QQ群二维码
加入600团队


引言
我们准备分两篇文章来描述并行执行的工作原理和涉及到并行执行相关调优参数,别着急,今天主要以并行查询执行计划为主,明天以主要性能参数为主,开门见山,文章内容涉及到的技术细节较多,也是我绞尽脑汁尽可能的帮助大家理解并行查询的工作原理的辛苦劳作,可以静下来分段式浏览,挑自己感兴趣的内容看。
Part1.干货速递
这篇文章其实就一个目的,我们主要剖析并行执行的全过程,文章主题分为以下几个部分内容:
1.1 涉及SQL语句的并行执行
1.2 并行执行服务器如何通信
1.3 degree的并行性
1.4 并行语句排队机制
1.5 并行执行的server pool
1.6 Granules的并行性
1.7 如何平衡工作负载
1.8 在Oracle RAC并行执行
注意:文章内容较长,可以选择性阅读,对那部分感兴趣可以加入600群,我们群内讨论。

2.2.1

2.2.2
查询协调器获得所需的并行服务器数量
2.2.3
2.2.4
注意:
并行服务器的协调分工机制
并行执行协调器检查SQL语句执行计划中的每个操作,然后确定在并行执行服务器之间必须以何种方式划分或重新分布操作上的行。作为具有内部和操作间并行性的并行查询的示例,我们就不建立测试表了。
以SH用户的sales, customers作为案例标准:
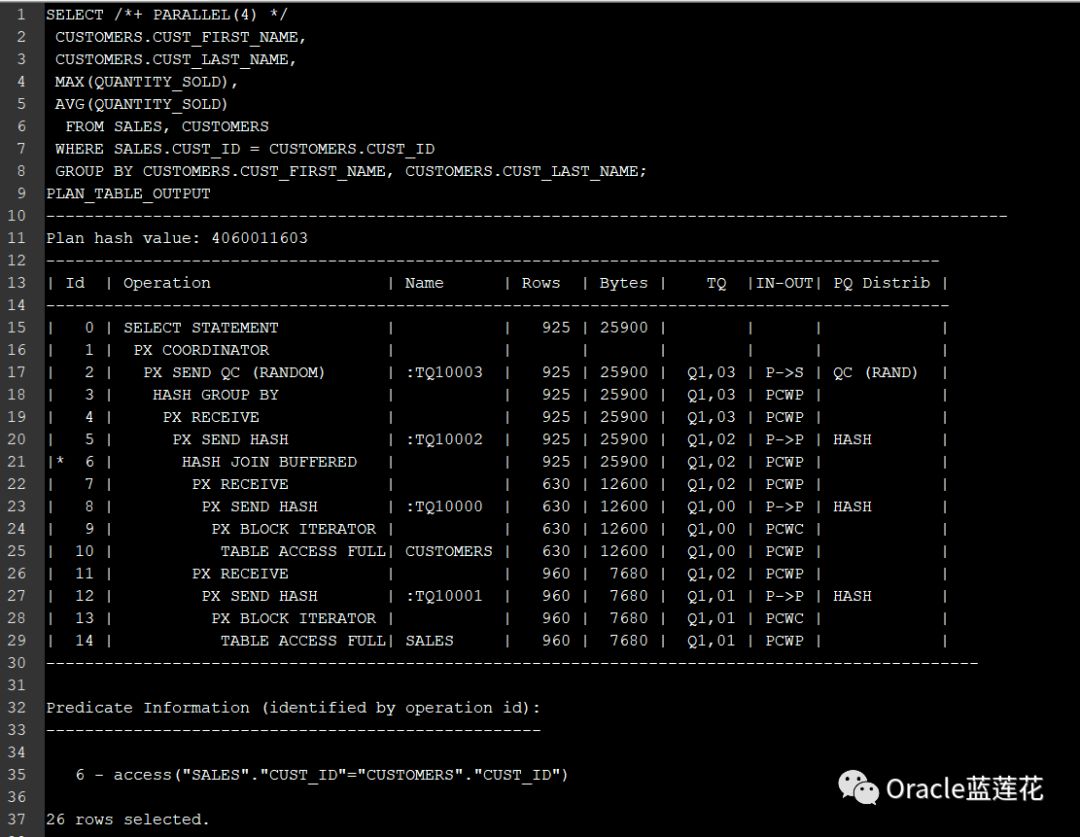
注意:
01
整体执行逻辑为:table access full sales或者table access full customers ->hash join ->group by sort ->parallel execution coordinator
02
给定两组并行执行服务器 SS1 和 SS2,执行过程如下:由于查询中指定DOP的并行提示,每个服务器集(SS1和SS2)有四个执行过程
03
子集SS1首先扫描CUSTOMERS并将行发送给SS2,后者在行上构建一个哈希表。换句话说,SS2中的使用者和SS1中的生产者同时工作:一个是并行地扫描CUSTOMERS,
另一个是使用行并构建哈希表以支持并行地进行哈希连接。我们管这叫操作间并行性。
04
SS1扫描完整个CUSTOMERS后,将并行扫描SALES。将它的行发送到SS2中的服务器,然后服务器执行探测以并行完成哈希连接。在SS1并行扫描SALES并将行发送到SS2之后,
它将切换到并行执行组操作。这是两个服务器集并发运行的方式,以实现查询树中不同操作符之间的操作并行性
05
并行执行的另一个重要方面是,当行从一个服务器集中发送到另一个服务器时,会重新分配行。对于上面示例的执行计划,在SS1中的服务器进程从customers表中扫描
一行之后,应该将它发送到SS2中的哪个服务器进程? 行正在流入的操作符决定重新分配。在本例中,通过连接列上的哈希分区,将从执行customers并行扫描的SS1向上
汇总重新分配到执行并行哈希连接的SS2
06
GROUP BY SORT操作是HASH JOIN操作的使用者,因为GROUP BY SORT需要HASH JOIN输出
3.1
为了并行执行查询,Oracle通常创建一组生产者并行执行服务器和消费者并行执行服务器。生产者服务器从表中检索行,消费者服务器对这些行执行连接、排序、DML和DDL等操作。
生产者集中的每个服务器都有一个到消费者集中的每个服务器的连接。并行执行服务器之间的虚拟连接数量随着并行度的平方而增加。
3.2
每个通信通道至少有一个,有时Oracle 11gR2最多有四个内存缓冲区,这些缓冲区是从共享池中分配的。多个内存缓冲区促进并行执行服务器之间的异步通信
3.3
单个实例环境最多为每个通信通道使用三个缓冲区。Oracle实际应用程序集群环境最多为每个通道使用4个缓冲区。理解消息缓冲区以及生产者并行执行服务器如何连接到
消费者并行执行服务器的概念对于理解parallel的执行计划其实很重要
3.4
当同一实例上的两个进程之间有连接时,服务器通过在内存(共享池中)来回传递缓冲区来进行通信。当连接在不同实例中的进程之间时,通过互连使用外部高速网络协议发送消息。
DOP实际上等于并行执行服务器的数量
4.1
与单个操作关联的并行执行服务器的数量称为并行度(DOP)。并行执行的设计是为了有效地使用多个cpu。Oracle数据库并行执行框架允许显式选择特定程度的并行性,
或者依赖Oracle数据库自动控制它
4.2
手动指定并行度:
alter table t_600_demo parallel 10;
注意:
在这种情况下,仅访问t_600_demo表的查询使用请求的DOP 10,可能分配10个并行服务器(生产者或消费者);只要指定了不同的DOP, Oracle数据库就会使用更高的DOP。
02
如果指定了PARALLEL子句,但没有列出并行度,对象将获得默认的DOP。默认并行度使用公式根据系统配置确定DOP

03
举个例子:默认情况下,INSTANCE_COUNT是集群中的所有节点。但是,如果使用Oracle RAC服务来限制并行操作可以执行的节点数,那么参与节点数就是属于该服务的节点数。
例如,在一个4节点的Oracle RAC集群中,每个节点都有8个CPU内核而没有Oracle RAC服务,默认DOP是2 x 8 x 4 = 64
04
默认的DOP算法是为了使用最大的资源而设计的,并假设如果可以使用更多的资源,操作完成得更快。默认的并行性目标是单用户工作负载。在多用户环境中,不建议使用默认并行
051
SQL语句的DOP也可以由资源管理器设置或限制。这里对resource manager就不做介绍了,以后我们通过具体的案例来为大家分享
5.1
当将PARALLEL_DEGREE_POLICY设置为AUTO时,Oracle数据库会自动决定一条语句是否并行执行,以及它应该使用什么DOP。Oracle数据库还确定语句是否可以立即执行,或者是否排队等待更多的系统资源可用。最后,Oracle数据库决定语句是否可以利用聚合的集群内存。
注意:
下面是将并行度策略设置为automatic时并行语句处理的总结:
1.发出一条SQL语句。
2.语句被解析,优化器决定执行计划。
3.检查 PARALLEL_MIN_TIME_THRESHOLD初始化参数指定的阈值限制。
如果执行时间小于阈值限制,SQL语句将连续运行。
如果执行时间大于阈值限制,则根据优化器计算的DOP并行运行语句
5.2
如何确定degree并行度?
5.2.1
优化器根据语句的资源需求自动确定语句的DOP。优化器在执行计划中使用所有扫描操作(全表扫描、索引快速全扫描等等)的成本来确定语句所需的DOP。
5.2.2
然而,优化器限制了实际的DOP,以确保并行服务器进程不会压倒系统。这个限制是由PARALLEL_DEGREE_LIMIT参数设置的。这个参数的默认值是CPU,这意味着进程的数量受系统上的CPU数量的限制(PARALLEL_THREADS_PER_CPU * CPU_COUNT *可用实例数量),也称为默认DOP。通过调整这个参数设置,可以控制优化器可以为SQL语句选择的最大DOP。
5.2.3
优化器确定的DOP显示在执行计划输出的notes部分(如下面的解释计划输出所示),使用执行计划语句或V$SQL_PLAN都可以看到:
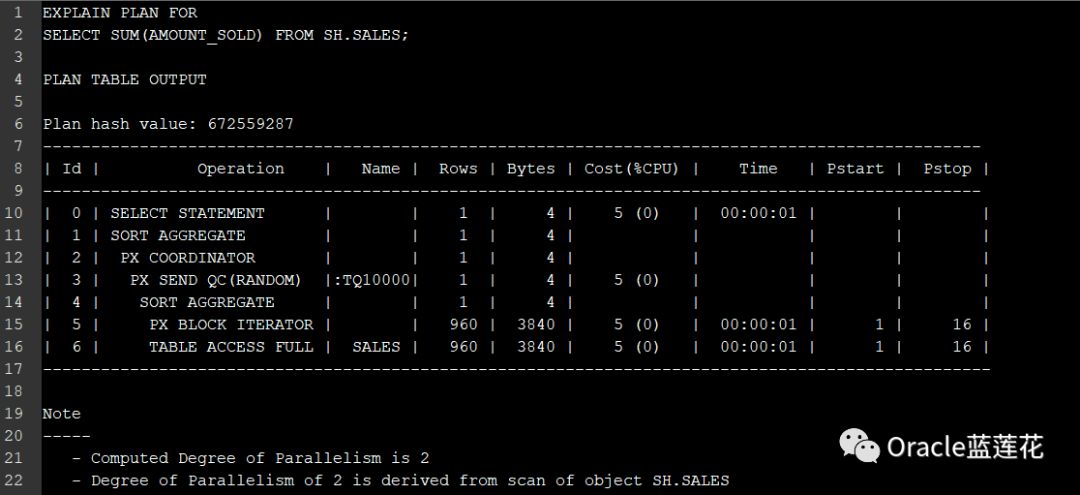
注意:
01
PARALLEL_MIN_TIME_THRESHOLD是控制自动DOP的第二个初始化参数。它指定了一个语句在考虑自动DOP之前应该具有的最小执行时间。默认情况下,这是10秒。
02
优化器首先计算SQL语句的串行执行计划
03
如果估计执行时间超过PARALLEL_MIN_TIME_THRESHOLD(10秒),则该语句将成为自动DOP的候选语句
5.3
怎么去控制自动并行度
我们应该怎么去控制自动并行度呢?
控制自动DOP的初始化参数有两个,PARALLEL_DEGREE_POLICY和PARALLEL_MIN_TIME_THRESHOLD。它们还被描述为自动并行度策略和控制自动DOP、并行语句排队和 内存中并行执行。还有两个提示可以用来控制并行性。
5.4
使用ALTER语句设置自动并行度
如何使用ALTER语句设置自动并行度:
ALTER SESSION SET parallel_degree_policy = limited;
ALTER TABLE emp parallel (degree default);
5.5
使用hint设置自动并行度
SELECT *+parallel */ ename, dname FROM emp e, dept d WHERE e.deptno=d.deptno;
注意:
01
可以使用parallel hints来设置并行度。它接受一个可选的参数,表示为语句运行时的DOP。
02
此外,NO_PARALLEL hint覆盖了DDL中创建或修改表的一个并行参数。下面的例子说明了强制并行执行语句:
5.5.2
SELECT *+ parallel(10) */ ename, dname FROM emp e, dept d
WHERE e.deptno=d.deptno;
5.5.3
SELECT *+ no_parallel */ ename, dname FROM emp e, dept d
WHERE e.deptno=d.deptno;
5.5.4
SELECT *+ parallel(auto) */ ename, dname FROM emp e, dept d
WHERE e.deptno=d.deptno;
5.5.5
SELECT *+ parallel(manual) */ ename, dname FROM emp e, dept d
WHERE e.deptno=d.deptno;
6.1
当将PARALLEL_DEGREE_POLICY设置为AUTO时,Oracle数据库会决定使用并行执行访问的对象是否会从缓存在SGA中获益。缓存对象的决策基于一组定义良好的启发式方法:
包括对象的大小和访问对象的频率。在Oracle RAC环境中,Oracle数据库将对象的各个部分映射到活动实例上的每个缓冲区缓存中。通过创建这个映射,Oracle数据库自动知道要访问哪个缓冲区缓存内容。
6.2
Oracle数据库防止多个实例反复从磁盘读取相同的信息,从而最大化缓存对象的内存数量。如果对象的大小大于缓冲区缓存的大小(单个实例)或缓冲区缓存的大小乘以Oracle RAC集群中的活动实例数,则使用直接路径读取读取对象。
6.3
Adaptive Parallelism,也叫自适应并行
默认情况下启用的自适应多用户算法在系统负载增加时降低了并行度。在使用Oracle数据库自适应并行能力时,数据库在SQL执行时使用一种算法来确定并行操作是否应该接收请求的DOP,还是应该降低DOP以确保系统没有过载,这个算法我不确定,因为ORACLE没公开,目前知道了解到这里。
6.4
在一个通过使用高DOP并行执行的系统中,当只有少数操作并行运行时,自适应算法将DOP调降。虽然该算法保证了最优的资源利用率,但用户可能会遇到不一致的响应时间。
不建议在需要确定响应时间的环境中单独使用自适应并行能力。通过数据库初始化参数PARALLEL_ADAPTIVE_MULTI_USER控制自适应并行性。
6.5
控制自动DOP、并行语句排队和内存中并行执行
MAUAL-禁用自动DOP、语句排队和内存中并行执行。它将并行执行的行为恢复到Oracle数据库11g之前的行为,版本2(11.2)是默认的。
LIMITED-允许一些语句的自动DOP,但并行语句队列和内存中的并行执行是禁用的。自动DOP仅适用于访问用PARALLEL子句显式声明的表或索引的语句。具有DOP指定的表和索引使用显式DOP设置
AUTO -支持自动DOP、并行语句排队和内存中并行执行。
7.1
当将PARALLEL_DEGREE_POLICY设置为AUTO时,Oracle数据库会在队列排队SQL语句,如果没有必要的并行服务器进程,这些语句需要并行执行。在必要的资源可用之后,SQL语句将退出队列并允许执行。默认的退出队列顺序是一个简单的先入先出队列,它基于语句发出的时间。
7.2
如果运行这些语句会增加PARALLEL_SERVERS_TARGET初始化参数值以上的活动并行服务器数量,则并行语句将排队。例如,如果将PARALLEL_SERVERS_TARGET设置为64,当前活动服务器的数量为60,而一个新的并行语句需要16个并行服务器,则会排队,因为16加到60后大于PARALLEL_SERVERS_TARGET的值64。
7.3
默认值在“PARALLEL_SERVERS_TARGET”中描述。这个值不是系统上允许的并行服务器进程的最大数量,而是在使用并行语句队列之前运行并行语句的可用数量。
它被设置为低于系统上允许的并行服务器进程的最大数量(PARALLEL_MAX_SERVERS),以确保每个并行语句获得所需的所有并行服务器资源,并防止用并行服务器进程重载系统。
注意,所有串行(非并行)语句即使是并行语句也会立即执行
7.4
与资源管理器管理并行语句排队
7.4.1
默认情况下,并行语句队列操作为一个先入先出队列。通过配置和设置资源计划,可以控制并行语句退出队列的顺序以及每个工作负载或使用者组使用的并行服务器的数量
7.4.2
资源计划和使用者组使用DBMS_RESOURCE_MANAGER PL/SQL包创建。资源计划由每个使用者组的一组指令组成,这些指令指定各种数据库资源(如并行服务器)的控制和分配。
通过将RESOURCE_MANAGER_PLAN参数设置为资源计划的名称来启用资源计划
7.4.3
使用使用者组设置并行语句队列中的优先级
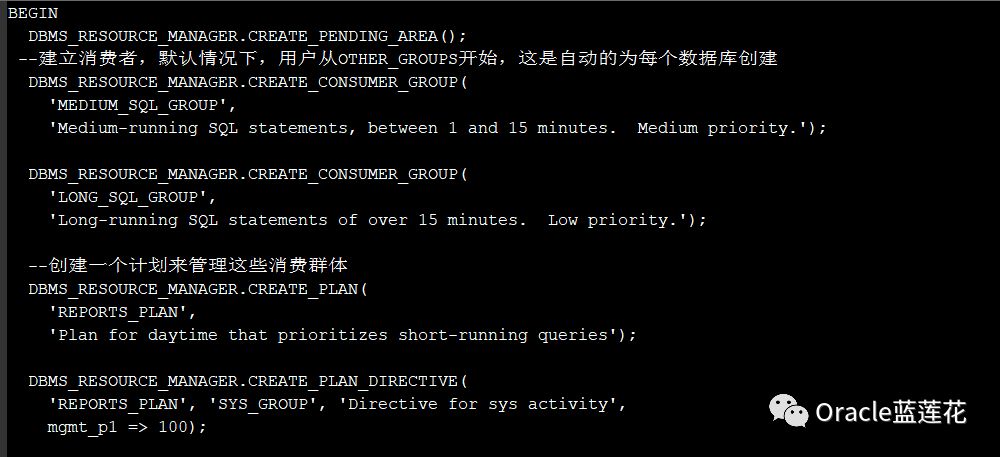
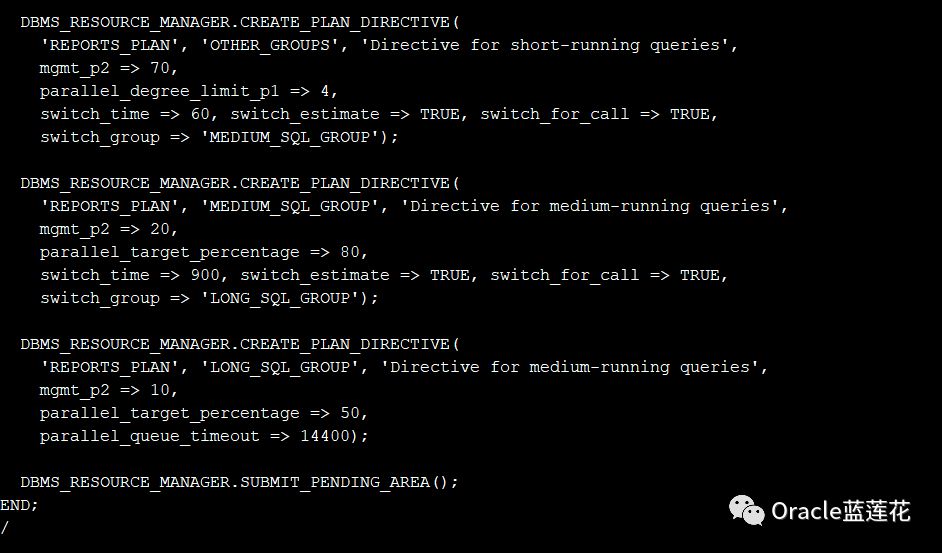
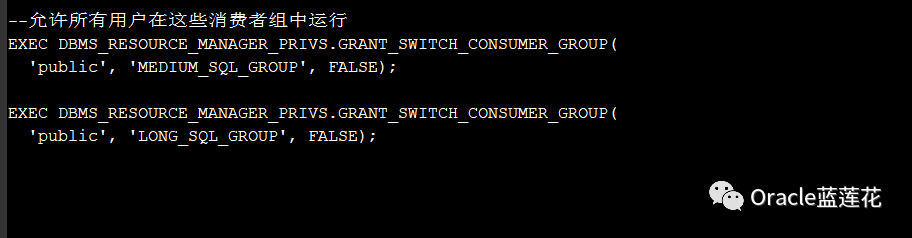
7.5
使用hint管理并行度队列
7.5.1
当PARALLEL_DEGREE_POLICY设置为AUTO时,该hint允许语句绕过并行语句队列

7.5.2
当PARALLEL_DEGREE_POLICY未设置为AUTO时,该提示允许语句延迟,并且仅在并行进程可以在请求的DOP上运行时才运行

关于granules的理解:
8.1
并行工作的基本单位是一种叫做颗粒的东西。Oracle数据库将并行执行的操作(例如,表扫描、表更新或索引创建)划分为颗粒。并行执行过程一次执行一个颗粒。颗粒的数量及其大小与并行度(DOP)有关。颗粒的数量也会影响查询服务器进程之间工作平衡的好坏
8.2
当使用分区粒度时,并行服务器进程在表或索引的整个分区或子分区上工作。因为在创建表或索引时,分区颗粒是由表或索引的结构静态决定的,所以分区颗粒不能像块颗粒
那样灵活地并行执行操作。允许的最大DOP是分区数量。这可能会限制系统的利用率和并行执行服务器之间的负载平衡
8.3
分区粒度是并行索引范围扫描、两个分区表之间的连接(查询优化器选择使用分区连接)和修改分区对象的多个分区的并行操作的基本单元。这些操作包括并行创建分区索引和并行创建分区表
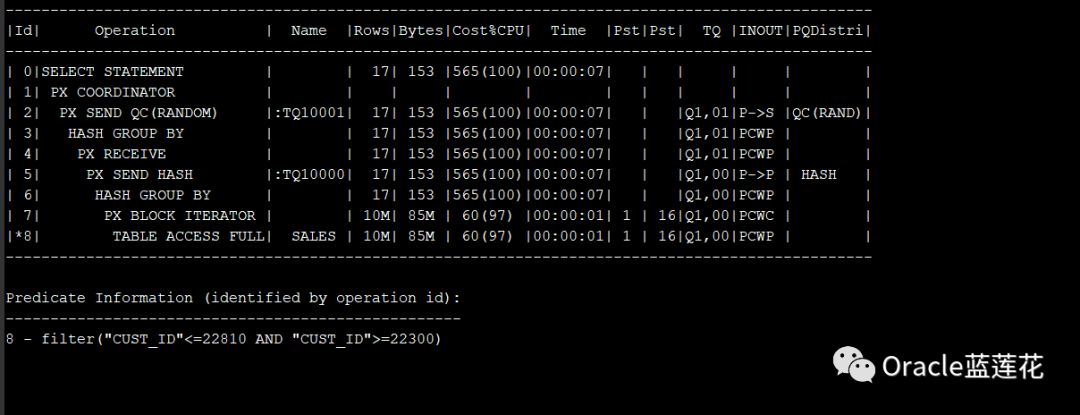
8.4
通过查看语句的执行计划,可以知道使用了哪些类型的颗粒。表上方的行PX块迭代器或索引访问表明使用了块范围颗粒。在下面的示例中,可以在explain plan输出的第7行看到这一点,
就在SALES表上的FULL ACCESS上面
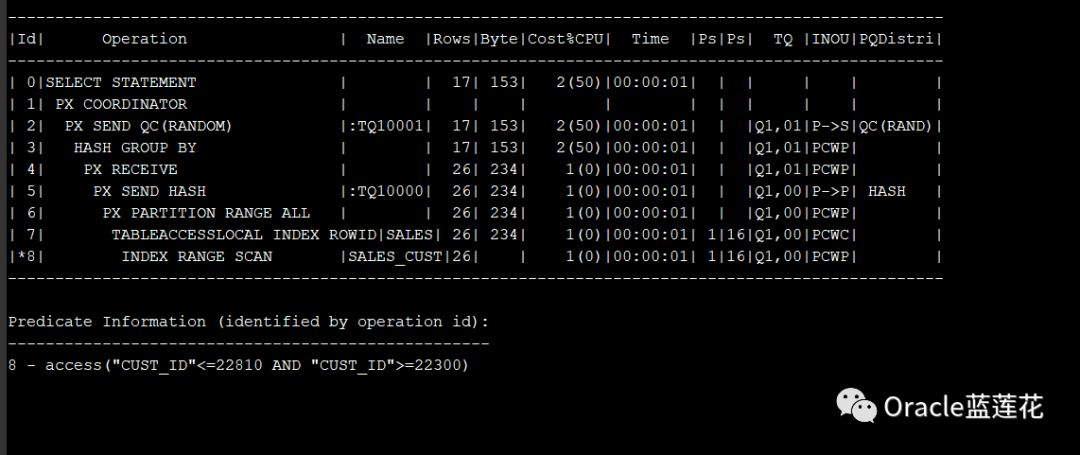
8.5
当使用分区粒度时,可以在explain plan输出中看到表上方的行PX分区范围或索引访问。在下面示例的第6行中,计划有PX分区范围ALL,因为该语句访问表中的所有16个分区。
如果不访问所有分区,则只显示PX分区范围。
9.1
为了优化性能,所有并行执行服务器的工作负载应该相同。对于根据块范围或并行执行服务器并行运行的SQL语句,工作负载在并行执行服务器之间动态划分。这可以最小化工作负载倾斜, 当一些并行执行服务器执行的工作明显多于其他进程时,就会出现这种情况。
9.2
相对较少的并行执行的SQL语句的分区,如果工作负载分区中均匀分布,可以通过匹配优化性能并行执行服务器的数量的分区或通过选择分区的数量的计划过程的数量的倍数。
这适用于Oracle9i之前创建的表上的分区连接和并行DML。过多的信息说实话没深入了解过,这块可以看看国外DBA大牛的书,问问tom和thoms
9.3
例如,假设一个表有16个分区,一个并行操作在它们之间平均分配工作。可以使用16个并行执行服务器(DOP等于16)在大约十分之一的时间内完成一个进程所需的工作。
还可以使用五个流程在五分之一的时间内完成工作,或者使用两个流程在一半的时间内完成工作。
9.4
但是,如果使用15个进程处理16个分区,第一个进程在一个分区上完成它的工作,然后开始在第16个分区上工作;当其他进程完成它们的工作时,它们就变得空闲了。
当工作在分区之间平均分配时,此配置不能提供良好的性能。当工作分配不均匀时,性能会根据最后剩下的分区是否比其他分区有更多或更少的工作而化。
Part10.The End 总结
10.1
其实大家都心有感触,很多使用parallel的数据库性能问题可能是因为同时启动的并行进程过多造成的,特别常见于RAC节点重启,很多时候是因为瞬间启动了很多个并行进程,导致OS各项指标都很高。
10.2
刚才我们提到过,在单实例:
auto DOP = PARALLEL_THREADS_PER_CPU x CPU_COUNT
在RAC环境中:
auto DOP = PARALLEL_THREADS_PER_CPU x CPU_COUNT x INSTANCE_COUNT
10.3
Oracle官方给出的优先级为:
hint>degree>auto DOP
10.3.1
如果hint指定了并行度,会忽略表的degree。
10.3.2
如果hint只指定parallel,不写具体的数字,或者表上DEGREE显示为DEFAULT,没有具体数值(alter table t_600_demo parallel不指定具体degree数值),则会使用auto DOP
10.3.3
如果表中有group by或者其他排序操作,以上并行度×2。
10.3.4
RAC中,并行度会自动平均分配到各个节点上,比如并行度128,2个节点,则每个节点上各起64个并行进程。
10.4
后期我们单独写一篇关于parallel参数调优的文章,今天的文章理论知识很多,但就是因为这些理论知识和工作原理,才能支撑一个专业DBA去更好的处理问题。
关注ORA-00600微信公众号,给你不一样的技术体验
携手同行

分享成长



