




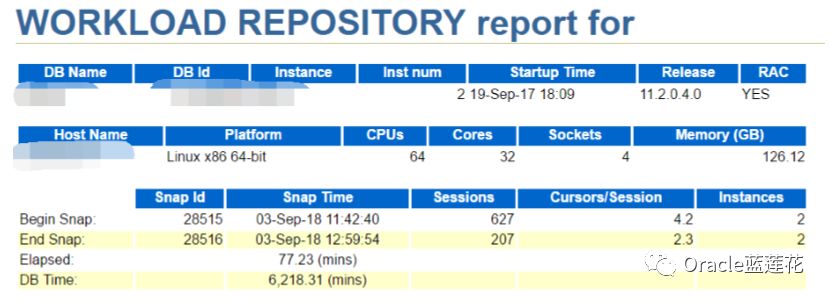
在以往的章节我们了解到dbtime标示着对应foreground session elapsed oracle database的时间,本次AWR案例我们看到了 dbtime是6218.31分钟,这6000分钟里包括了cpu逻辑处理时间,cpu运行队列等待事件,同时包括了I/O负载消耗时间,以及对应 的非空闲等待时间,我们表征一个事实本质,就是对应所有的foreground session花费在oracle数据库上的时间
dbtime elapsed=6218.31 77.23=80分钟,当前数据库服务器逻辑CPU数目为64,对应CPU核数为32核,物理CPU是4,那么 我来做一种假设,用sessions中的627-207=400,对应逻辑CPU是64,在一个小时范围内没有任何非空闲等待,通通都是空闲的等 待事件情况下,一直在CPU上运行,那么实际的CPU就等于400 *60=24000,平均活动session预估的时间就应该是24000 60=400,那么我可以确定的是,这400个session总有一个要在CPU运行队列中等待,这只是一种假设,实际的AWR情况,和实际 的生产环境不同于我们假设的思路。
书归正传
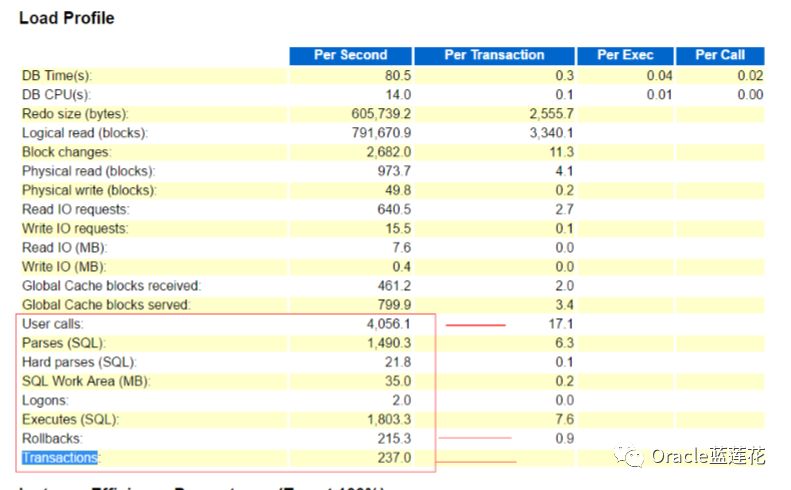

表象层面给了我们若干的启发,比如每秒执行1803次,每秒解析1490次,每秒硬解析高达21.8次,有的DBA会说硬解析很高, 不用看了,Oracle官方要求每秒20次,后台应该是latch :shared pool,是的,首先思路是对的,但不够具体,因为我们不能通过 一个指标就立刻定位数据库瓶颈关键点,请注意Parse CPU to Parse Elapsd指标,它表示两次快照范围之内解析CPU时间和总的解 析时间的比值,目前我们看到的是12%,那说明在整个解析过程中实际在CPU上运算的时间是相对较短的,解析真正的消耗并不在 CPU层面而是其他非空闲等待事件上,LATCH因为自己独立的特性,对于CPU有严重的资源占用,所以,经验告诉我,LATCH并不 是重点。。执行 解析包括硬解析确实存在疑点,但为什么会产生那么多的事务回滚呢?是应用框架spring整合hibernate事务管理 的机制问题,还是人为相关操作导致的?
这里我暂且留个疑问,大家可以发挥自身的知识结构和Oracle工作原理的积累,想想为什么?
我们不妨基于oracle 工作原理,对于缓存融合和各个实例间协调完成恢 复操作的:【干货来了】
Oracle干的第一个事,在恢复的初始阶段,将重新配置GES入队列,并冻结全局资源目录。所有GCS资源请求和写入都被暂时停止
GCS资源在幸存的实例中重新配置。幸存的实例之一成为真正干恢复这个活的实例。恢复实例的SMON进程启动失败实例的重做 线程的重做日志读取的第一次遍历 。
标识需要恢复的块资源,并重新构建全局资源目录。挂起的请求或写入被取消或重播 。
假设在集群中的其他缓存中有要恢复的块的过去映像,则从其他实例请求源缓冲区。资源缓冲区是恢复特定块的起点。
后续处理所需的所有资源和队列都已获得,全局资源目录现在已解冻。现在可以访问不处于恢复状态的任何数据块。此时,系统 部分可用。
最后一步才是SMON合并SCN的重做线程顺序,以确保以有序的方式写入。(此过程对于多个并发故障非常重要。如果多个实例 同时死亡,PI缓冲区和数据块的当前缓冲区都无法在任何存活实例的缓存中找到。然后执行失败实例的日志合并操作)。
那么在整个恢复流程中,通常会伴有诸如gc domain validation等待事件,gc domain validation是实例恢复过程中,刚才我们 举例的2,3这两个步骤中开始的,在实例恢复中,gc domain validation是在第二次恢复之后进行的,在gc domain validation过 程中,SMON isses对IDLM(现在是GRD)的恢复锁做最基本的说明,恢复过程才能继续进行。
当我们开始去描述清楚RAC环境对于事物的恢复流程和缓存融合协调各部组件的工作原理后,我们继续往下看:
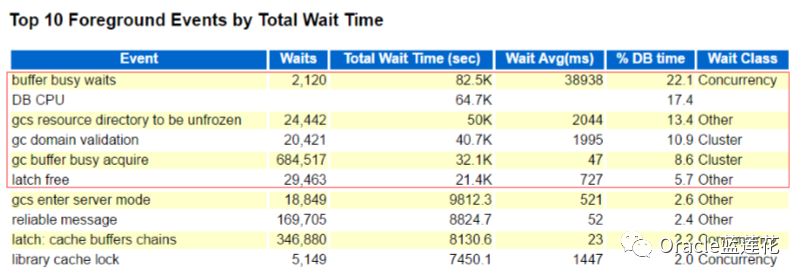
排名靠前的等待事件和类型依次浮出水面,并发类型等待事件buffer busy waits鹤立鸡群,对应占用dbtime比例,我们按照 100%的权重来做个衡量:100-22.1-17.4-13.4-10.9-8.6-5.7=21%,OK,那看来我们分析定位的重点可以放在前台等待事件上,那 么面对如此之多的前台等待事件,我们如何抽丝剥茧,找到资源占用中最致命的那一个呢?
来看如人饮水冷暖自知如何帮助600成 员分析:
首先,我们把表象层面对应的内容梳理出来,buffer busy waits平均等待事件38938毫秒,总共等待2120次,问题现象,可能是 查询和查询之间发生的该等待事件,比如查询进程正在进行new block,从磁盘读取数据到buffer cache,产生buffer lock锁,这 时候查询进程会出现read by other session等待事件,那么另一个是查询操作导致的delay commit更新,这时候会等待buffer busy waits.
还有一种是查询和更新之间的资源冲突,在查询的进程和更新进程并发执行期间,查询进程会等待在更新进程的buffer lock资源 释放,那么将等待在buffer busy waits上,这里需要主要,更新进程是不需要等待查询进程的。
还有一种可能是更新进程之间的相互等待,两个更新进程产生的buffer busy waits.,所以第一件事我们初步判定有热对象的争用 情况发生。
好吧,我们真的看到了gc domain validation等待事件,去做验证处理,是的,刚才和大家提到的,看来有事务回滚情况可以说 明了。
别着急,我们来看AWR给出的具体RAC资源情况:

0.06%的的逻辑读意味着由其他节点上的缓存满足Global Cache Receive/server的原因一般是节点间缓存争用或本地无此缓存。
(received+served)*db_block_size=1261.07 * 8 1024=9.85M S ,一般我们建议专用网络选用10Gb带宽,一条GCS/GES Message基本可以维持在200 bytes左右。
我做个简单的流量评估,Estd interconnect traffic计算公式为:
Estd Interconnect traffic (KB) = (('gc cr blocks received'+ 'gc current blocks received' + 'gc cr blocksserved'+ 'gc current blocks served') * Block size)+ (('gcs messages sent' + 'ges messages sent' + 'gcs msgs received'+ 'gcs msgs received')*200)/1024/Elapsed Time。
那么我们通过预估的标准得出,当前私网通信基本可以满足低网络延迟和可用带宽的限制范围,当然具体的例如我们可以通过iperf工具去 测试路由器 交换机及其服务器的实际网络流量,这里只是给出一个预估结果。
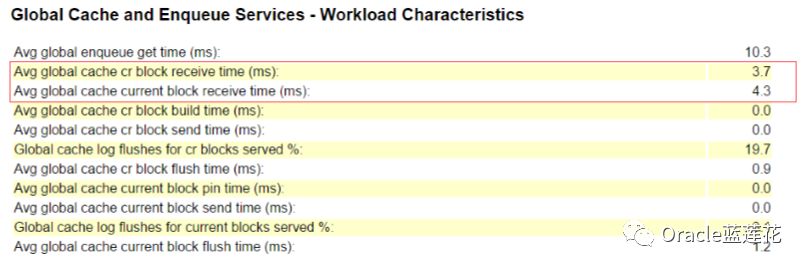
我们说,从请求的数据库实例发送消息到master实例(2-way get)和一些到holding instance (3-way get)花费的时间在3.7毫 秒,当然啦这个时间也包括在阻塞实例生成block做一致性镜像的时间。CR数据块获取耗费的时间不应该大于15ms,当前3.7毫秒
没有太大参考价值,还需要结合另一个节点去分析。
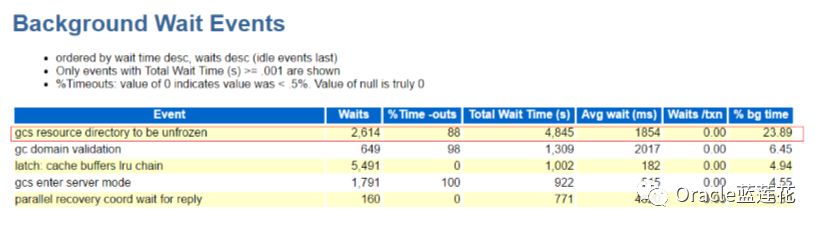
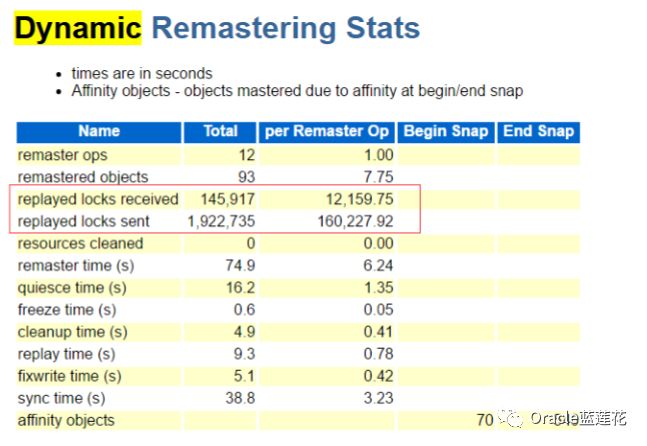
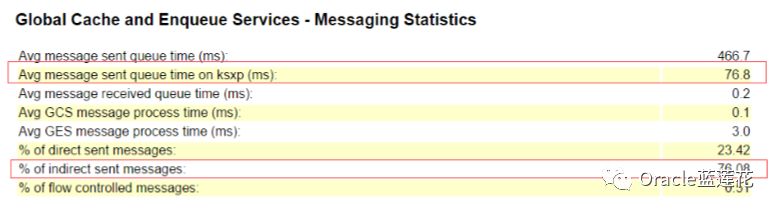
看来gcs resource directory to be unfrozen与DRM 有直接关系,我们梳理一下具体情况:在RAC中,每个数据块都由一个实例 控制。掌握一个块仅仅意味着主实例一直跟踪块的状态,直到下一次重新配置事件发生。当一个实例离开集群时,该实例的GRD部 分需要重新分配给幸存的节点。类似地,当新实例进入集群时,必须重新分配现有实例的GRD部分,以创建新实例的GRD部分。这称为动态资源重新配置。
除了动态资源重新配置外,还有一种类似DRM动态重新控制。我理解的基本思想是在实例上控制一个缓冲区缓存资源,在这个实 例上缓存资源通常是被访问的。为了确定是否需要动态重新控制,GCS本质上是在每个实例和每个对象的基础上跟踪GCS请求的数 量。这意味着,如果一个实例与另一个实例相比,大量地访问来自同一对象的块,GCS可以决定动态地将该对象的所有资源迁移到 访问该对象最多的实例。LMON LMD和和LMS进程负责动态重新控制诸如此类的操作
我们举例一种场景:

注意:我们尝试使用oradebug lkdebug -m pkey data_object_id手动做个跟踪,跟踪什么? 跟踪数据库实例关闭和重启的资源状态,和该对象的变化情况。


检查块的当前主节点是否已更改为node2(编号从0开始)

GCS在实例上控制一个缓冲区缓存资源,在这个实例上它通常被访问为了确定是否需要动态重新控制,GCS本质上是在每个实例和每个对
象的基础上跟踪GCS请求的数量。 这意味着,如果一个实例与另一个实例相比,大量地访问来自同一对象的块,GCS可以决定动态地将该对象的所有资源迁移到访问该对象 最多的实例。
-X$object_policy_statistics维护关于对象的统计信息通过数据字典可以显示这些对象。LCK0进程维护这些对象关联统计信息
以下参数会因资源亲和性而影响动态重设:
_gc_policy_limit :如果一个实例在一个对象上再打开50个,那么另一个实例(由_gc_policy_limit参数控制)就会打开,那么这个对
象就是重新控制的候选对象。该对象排队,LMD0读取队列并启动GRD冻结。LMON执行与LMS进程一起工作的缓冲区缓存锁的重新配置。所有这些都可以在LMD0/LMON跟踪文件中 看到。_gc_policy_time:它控制检查队列的频率,以查看是否必须触发重新控制,默认值为10分钟。
_gc_policy_minimum:该参数被定义为“每分钟 dynamic affinity activity的最小数量,以作为重新控制的候选。默认值是2500, 我想,在繁忙的环境下会更低。
要完全禁用DRM,可以将_gc_policy_limit和_gc_policy_minimum设置为更高的值,比如1000万。将参数_gc_policy_time设置为 0将完全禁用DRM,
但这也意味着我们不能手动重新控制对象。此外,如果禁用DRM,则不维护$object_policy_statistics。
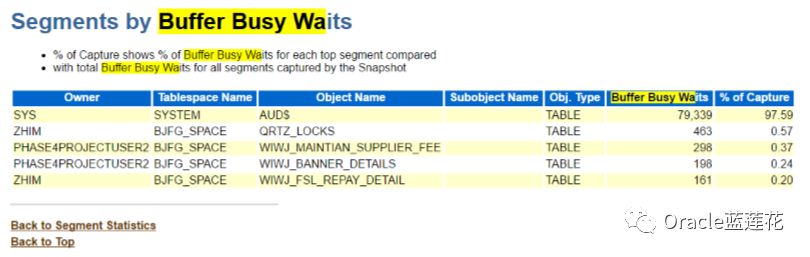
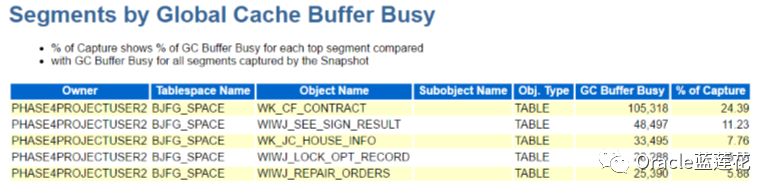
buffer busy waits的资源争用在审计表aud$上,rac整个集群的争用在一个物理表上,那么我们回顾刚才阐述的知识点:GCS在 实例上控制一个缓冲区缓存资源,在这个实例上它通常被访问为了确定是否需要动态重新控制,GCS本质上是在每个实例和每个对 象的基础上跟踪GCS请求的数量。这意味着,如果一个实例与另一个实例相比,大量地访问来自同一对象的块,GCS可以决定动态地将该对象的所有资源迁移到访问该对象最多的实例。
和DBA沟通了解具体情况后,我们得知如下情况信息:

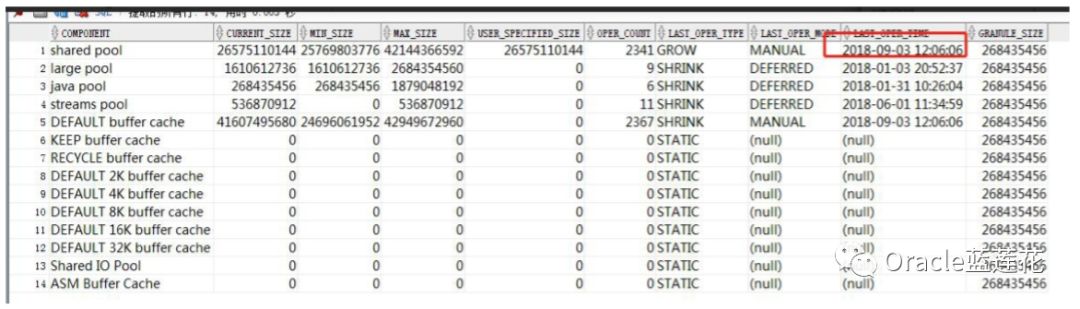
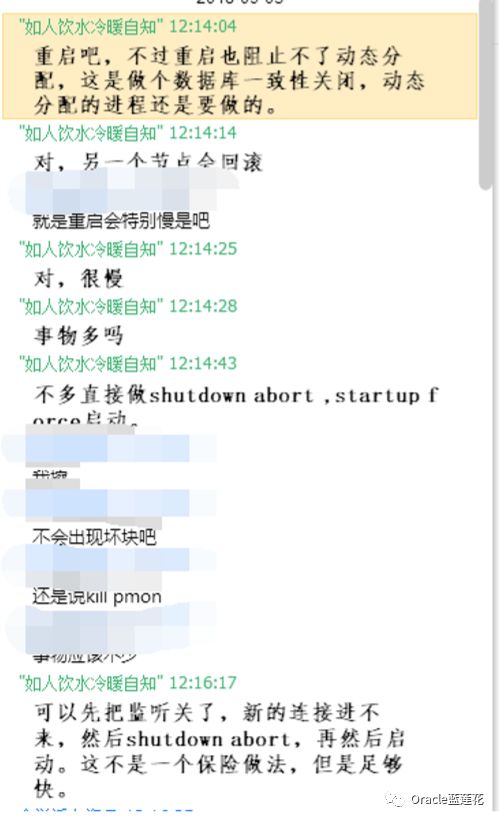
具体的操作如下
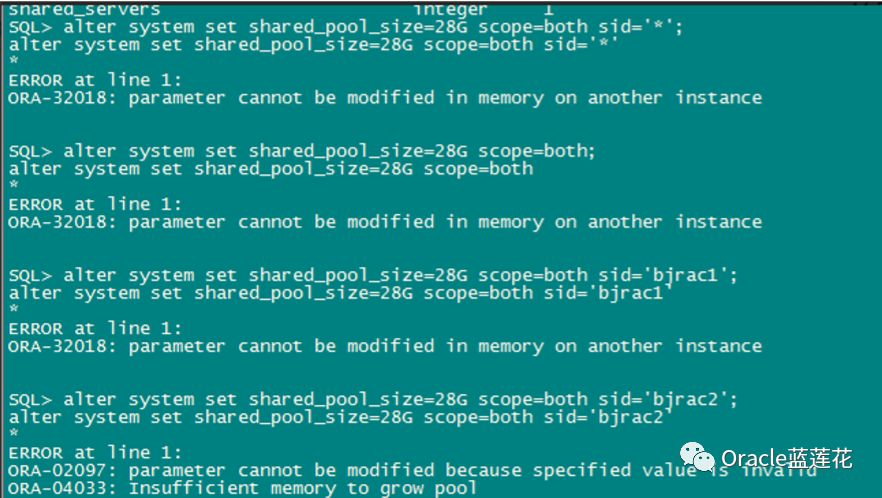

阶段性总结:
第一,首先问题的原因是由于SGA不能超过SGA_MAX_SIZE的设置。在init中未设置SGA_MAX_SIZE时。然后我们动态 地将SGA_MAX_SIZE参数的值设置为SGA,那么如果没有在init.ora设置参数,在实例启动时,SGA的当前大小是SGA_MAX_SIZE 的初始值呗。这是第一个问题。
然后,后台报错00445,说cjqb的子进程j000没办法启动后台的进程,然后抛了一个trace文件出来,这个时候系统资源 已经是不足了,简单说,共享内存段没办法根据现有的sga分配更多空间给到shared pool了,再然后系统hang住,oracle hang 住。
DRM动态重新控制期间在实例上控制一个缓冲区缓存资源,在这个实例上缓存资源通常是被访问的。为了确定是否需要 动态重新控制,GCS本质上是在每个实例和每个对象的基础上跟踪GCS请求的数量。这意味着,如果一个实例与另一个实例相比, 大量地访问来自同一对象的块,GCS可以决定动态地将该对象的所有资源迁移到访问该对象最多的实例。LMON LMD和和LMS进程负责动态重新控制诸如此类的操作。
那么看来j节点重启hang住和刚才我们分析的情况基本吻合,我可以判断是DRM引起的gcs resource directory to be unfrozen行为。
以下为MOS给出的解释口径和处理思路:

总结:
1. 现场DBA尝试动态为shared pool增加内存,但无法增加,主要原因是sga_max_size没有足够的资源,导致oracle在做 共享内存动态分配期间HANG住,同时由于此笔操作导致的操作系统资源紧张,直接报错ORA-00609 ORA-00445.
2. DBA在没有重启数据库之前,手动生成了AWR快照信息,然后关闭监听,采用shutdown abort方式停止数据库,在启 动过程中数据库仍然呈现HANG的现象。
3. 通过对DRM和数据库整体现象评估分析,基本符合以上BUG行为。
4. 我们透过AWR了解了数据库负载的现象,但具体的问题定位还需要通过alert.log日志,trace日志以及rac相关lmon lms 日志分析,这里通过一个案例为大家敲响警钟,做任何操作之前先考虑对oracle的资源占用情况以及影响。充分评估后再做操作。
5.DRM涉及的BUG较多,生产环境可以考虑关闭。
For 600 Team:
没有什么能够阻挡,我们对O的向往!
所有被人嘲笑的梦想,都有被实现的价值!
To be what you want to be.
