




今天想和各位600成员聊聊Oracle 12cR2的部分in meory新特性之一,开门见山,以下为in memory database新特性的介绍,我们今天系统的聊一聊
inmemory join group操作:

注意:今天我们只聊INMEMORY JOIN GROUP新特性,其他技术细节后期请关注600群内文档介绍
----------------------------------------------
2.Oracle 12cR2版本推出了INMEMORY JOIN GROUP新特性,该特性具体的用途是什么,日常生产欢迎我们应该如何应用,对于12c cbo优化器如何去管理
该新特性,日常工作中我们如何操作,带着疑问我们来系统学习一下:
2.1Oracle使用CREATE INMEMORY JOIN GROUP来创建 join group,join group本质上是一个对象,它指定来自同一表或不同表的频繁join column。
这些列通常包含兼容数据类型的值,它们属于 similar ranges。在CREATE INMEMORY JOIN GROUP时,Oracle会在全局字典中存储列的特殊元数据,
从而使数据库能够优化列的联接查询。为了实现这种优化,表列必须填充在in memory列式存储中。
2.2为表创建INMEMORY JOIN GROUP会导致这些表current In-Memory中的内容无效。随后的重新填充会导致表的内存中压缩单元(IMCUs)被全局字典重新编码。
因此,Oracle其实并不建议我们先CREATE INMEMORY JOIN GROUP,然后在填充表
注意:有点乱???不好理解?理论性太强?没关系,别着急,干货实例马上分享,但我们必须秉承足够了解内部机制,工作原理的基础上在做操作
2.3具体语法介绍:

注意:1.第一个schema指定包含联接组的模式。如果省略模式,那么oracle将在当前的模式中创建连接组,说白了就是用户名
2.join_group指定要创建的联接组的名称。名称必须满足“数据库对象命名规则”中列出的要求
3.table指定包含要包含在联接组中的列的表的名称
4.column指定要包含在联接组中的列的名称。联接组可以包含同一表或不同表中的列
5.join group必须至少包括两列
6.join group最多可以包含255个列
7.表列最多可以是一个联接组的成员
8.所谓join group其实是一组列,在这些列上经常联接一组表。列集包含一个或多个列;表集包含一个或多个表。join group中的列可以位于相同或
不同的表中。例如,如果t_600_demo1和t_600_demo2频繁地加入col列,那么我们就可以通过下面的语句实现
CREATE INMEMORY JOIN GROUP JOIN_GROUP_TABLE
(SCOTT.T_600_DEMO1(col), SCOTT.T_600_DEMO2(col));
9.切记一个列不能是多个联接组的成员
-----------------------------------------------
3.对于inmemory join group工作原理的深入分析:
3.1在某些查询中,join group消除了解压列值和散列值的性能开销。我们假设一个场景如果没有join group,如果cbo使用haSCOTT join但不能使用Bloom filter,
或者Bloom filter不能有效地过滤行,那么oracle必须解压缩IMCUs并使用昂贵的haSCOTT join。有点抽象,别着急
为了说明这个问题,假设星型模式有一个t_600_demo事实表和一个t_600_target维度表。以下查询连接这些表,但不过滤输出,这意味着数据库不能使用Bloom过滤器

3.2我们解释一下工作原理,在不适用join group情况下数据库执行散列连接如下:
3.2.1扫描t_600_demo_target维度表,解压缩满足谓词的行(在上面的语句中,所有行都满足谓词,因为不存在过滤器),并将行发送到哈希连接
3.2.2基于解压缩的行在PGA中构建一个哈希表
3.2.3扫描t_600_demo表并应用任何过滤器(在上面的语句中,查询没有指定过滤器)
3.2.4处理来自IMCUs的匹配行,然后将行发送到连接
4.2.5当哈希连接可以使用来自探测端(在本例中是t_600_demo表)的行集时,由选项卡发送的行集,行源生成器打印结果
注意:如果t.col1 = tt.col2 and t.col2 = tt.col2列上存在一个join group,那么Oracle可以使前面的步骤更加高效,从而消除解压缩和过滤开销
3.3在使用join group执行工作原理如下:
3.3.1oracle首先对压缩数据进行操作。
3.3.2oracle避免对连接键进行哈希和探查哈希表,这需要比较探测行和散列的连接键
3.3.3当join group存在时,Oracle将每个联接列值的代码存储在公共字典中。数据库使用字典代码构建一个join group list。每个数组元素都
指向存储在散列区域(通常是PGA内存)中的构建端行。在探测期间,每个探测行都有一个与连接键相关联的代码。数据库使用这段代码搜索数组,
以确定数组元素中是否存在指针。如果存在指针,则存在匹配;否则,就没有匹配
注意:bloom filter什么鬼?不懂,没事,我们会通过单独一篇文档来帮助大家了解布隆过滤器,目前我们只需要知道它是一种数据结构,我们通过下面
的代码来给大家演示布隆过滤器应用场景
3.4我们都知道Oracle 12c提供了使用in-memory处理来加快速度的选项。当您安装12.1.0.2软件时,它被称为in-memory选项。如果您有足够的可用资源(RAM),
那么使用它可以在处理速度上产生相当大的差异。让我们再看一个比较老的例子,在Bloom filters上,看看Oracle是否能更快地在in-memory中处理事务。
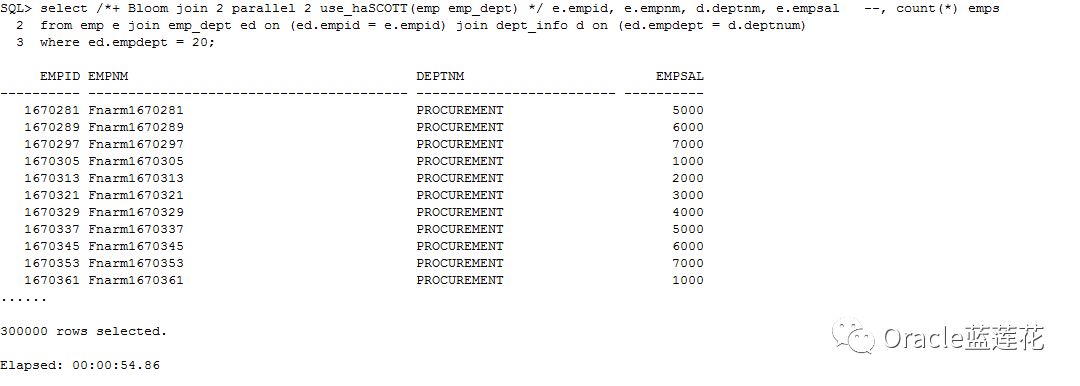
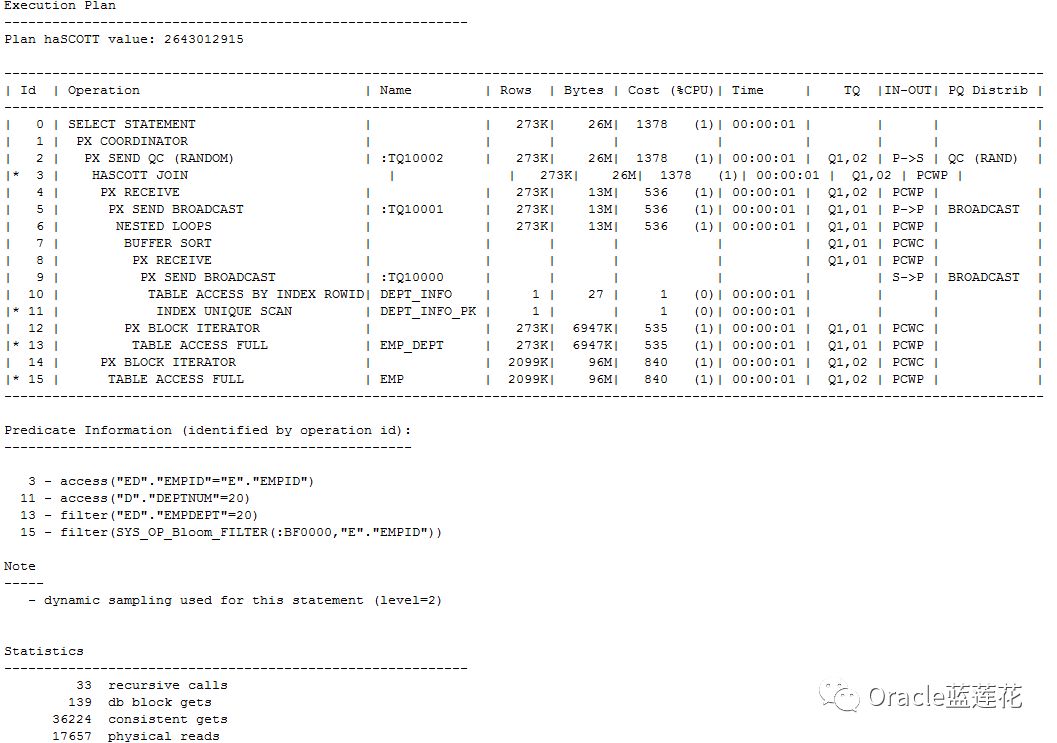
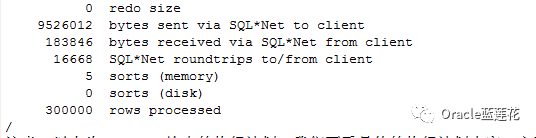
注意:以上为11.2.0.4给出的执行计划,我们不看具体的执行计划内容,主要关注消耗,物理读 17657 逻辑读buffer gets 36224 db_block_gets 139
3.5我们来看看12c怎么做到的

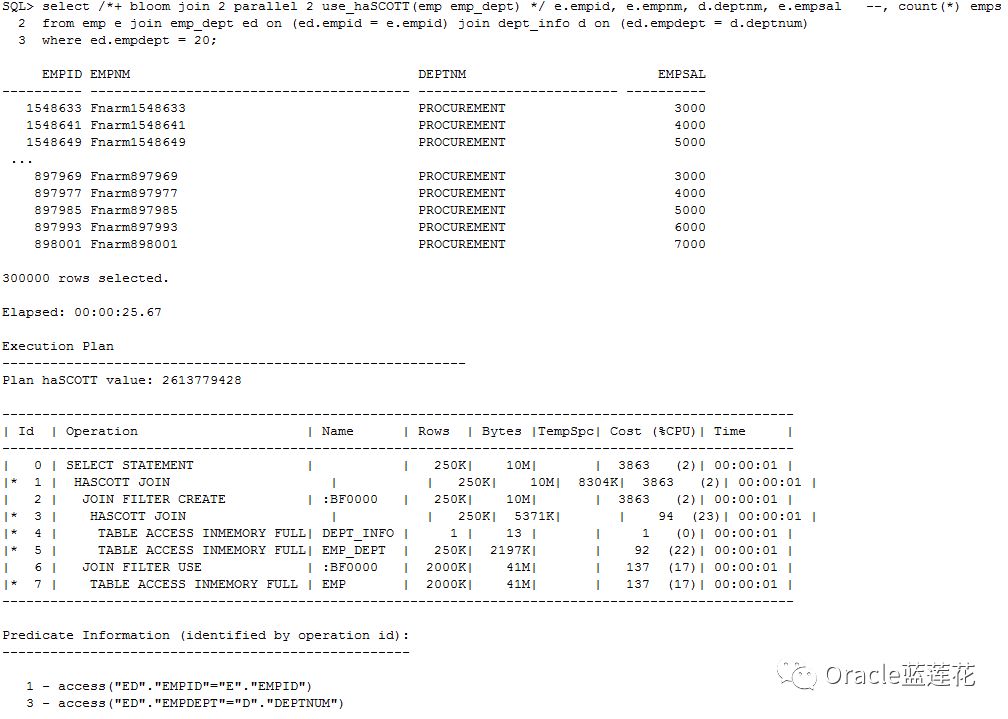
注意:1.Bloom过滤器仍然在使用,并且与in memory中选项一起使用,执行时间比最初的11.2.0.4版本示例要短得多。
2.由于表是in memory,所以内存排序为0(因为所有的处理都是在内存中完成的)。
3.对应物理读 0 逻辑读buffer gets 26 db_block_gets 0
4.测试结果给出的答案Bloom filter加上Oracle 12.1.0.2的in memory是可以提高查询性能的
------------------------------------------------
相同的公共字典压缩join group中的所有列,可能大家对公共数据字典作用不是太了解,别着急,我们
来具体分析:
4.1join group如何使用通用数据字典的?
4.1.1公共字典是表级的、特定于实例的字典代码集。当底层列上定义了一个join group时,oracle会在IM列存储中自动创建一个通用字典。
公共字典允许join group共享相同的字典代码。
4.1.2使用通用字典中的代码对本地字典中的值进行编码,从而提供压缩并提高IMCU的缓存效率
4.1.3允许联接使用字典代码来构造和探测数据结构
4.2join group如何优化扫描的?
4.2.1关键的优化是连接到公共字典代码而不是列值,从而避免了对连接使用哈希表。在上面第三小节我们有介绍过haSCOTT join的工作原理和
使用join group的工作原理,大家可以回顾一下
4.3join group在共用数据字典的作用?
4.3.1首先在创建join group时oracle干的第一个事是缓存连接键值的字典值,以及对应haSCOTT value
4.3.2然后使用相同的通用字典对列进行编码
4.3.3join group的列上使用两种优化方式提高性能,例如如果cbo选择haSCOTT join那么查询使用缓存的haSCOTT value来探测bloom filter,如果cbo使用haSCOTT
查询使用in memory聚合连接方式,那么查询使用缓存的二进制驱动索引关键向量方式
4.3.4对于haSCOTT join来讲,使不使用字典编码其实无关紧要的
4.4综合代码演示:

5.怎么监控这个join group功能呢?
5.1要确定查询是否使用join group,可以使用图形SQL监视器报告或使用DBMS_SQLTUNE的SQL查询。REPORT_SQL_MONITOR_XML函数都可以
5.2SQL Monitor的监控代码如下:
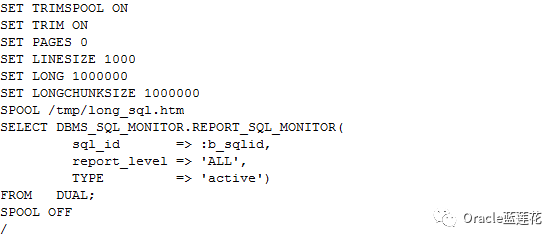
注意:在浏览器中访问报表,然后单击散列连接上的binoculars图标以查看join group统计信息
5.3使用DBMS_SQLTUNE。查询中的REPORT_SQL_MONITOR_XML函数

5.4两种方式的整体的代码流程如下:
5.4.1第一种方式
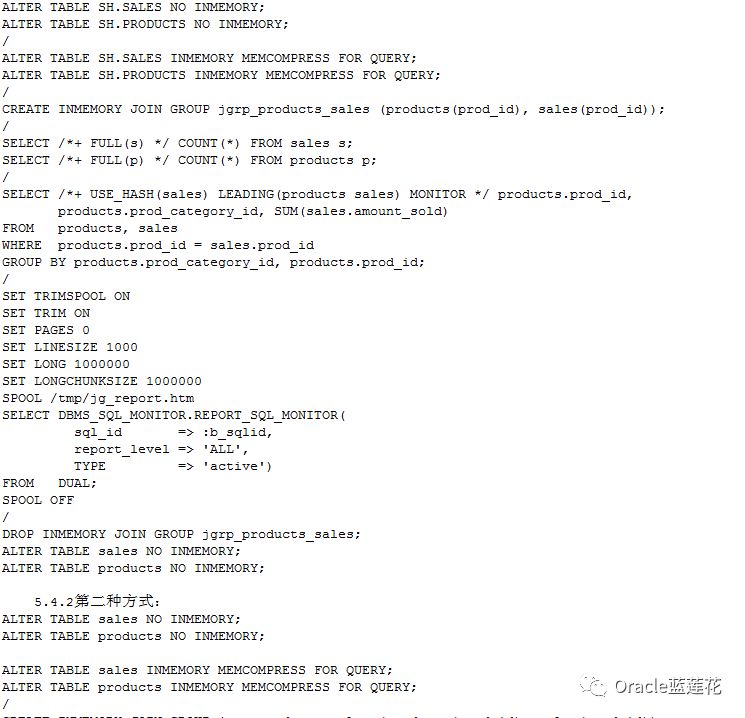
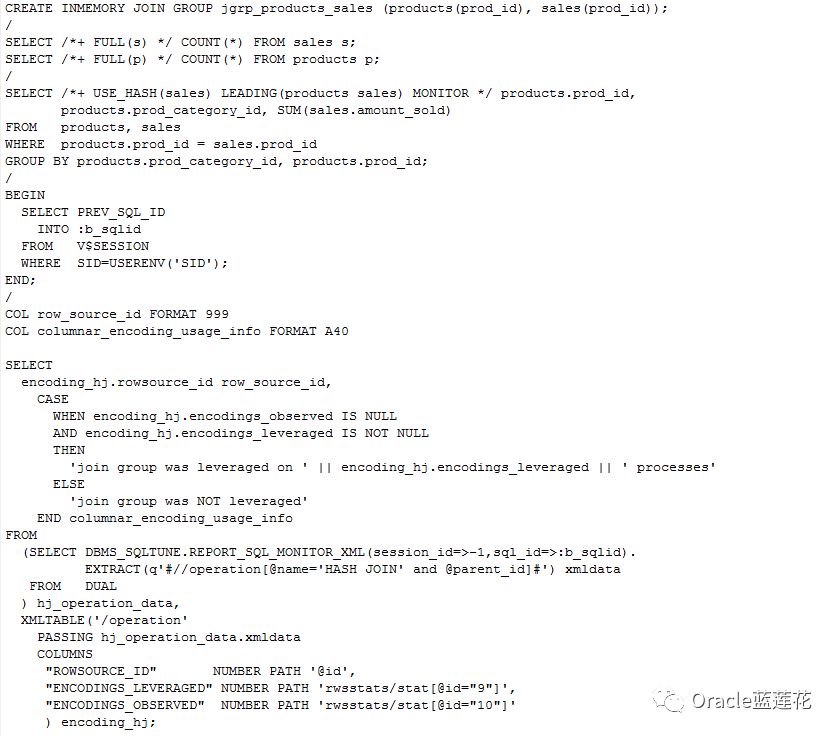
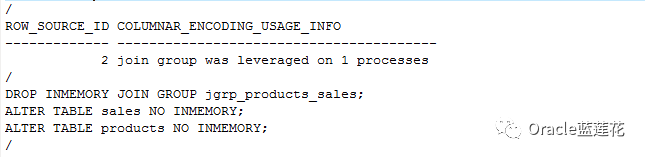
注意:1.join group was leveraged on 1 processes表示我们真正用到了join group操作:
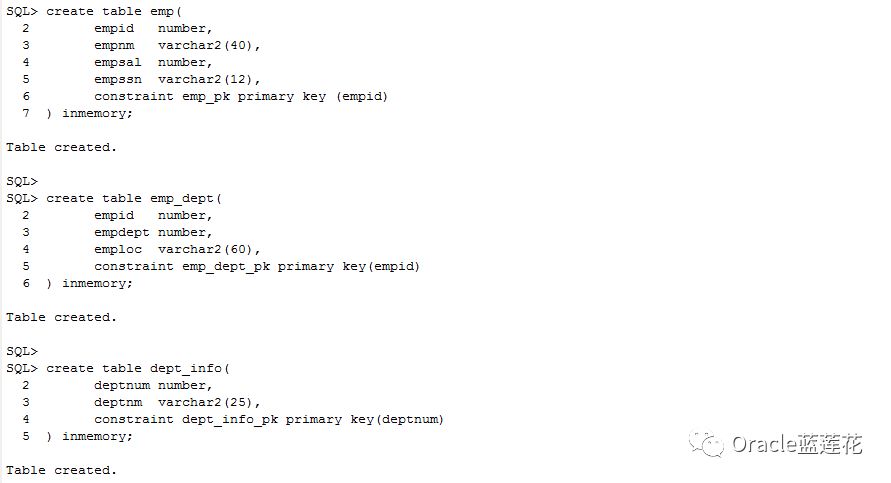
2.代码演示脚本中的t_600_demo1 t_600_demo2等可以通过scott用户的emp dept表,以及sh用户的sales和products 即可
-------------------------------------------------
6.定位问题的一些数据字典:
6.1检查join group是否存在:
select joingroup_name, table_name table_Column
2 from user_joingroups;
JOINGROUP_NAME TABLE_COLUMN
-----------------------------------------------
JGROUP_CUST SALES
6.2检查join group是否可见
SELECT o.object_name Table_Name, c.column_name Column_Name, g
d.head_address AS "GD Address"
2 FROM user_objects o, user_tab_columns c, v$im_segdict gd
3 WHERE gd.objn = o.object_id
4 AND o.object_name = c.table_name
5 AND gd.column_number = c.column_id;
no rows selected
6.3join group相关视图:
select view_name from dba_views where view_name like '%JOINGROUPS%';
VIEW_NAME
-----------------------------------------
USER_JOINGROUPS
DBA_JOINGROUPS
CDB_JOINGROUPS
------------------------------------------
《点亮梦想.拒绝平庸》
600团队(QQ群:851604218)
