




我最近在Rust NYC 聚会小组上谈到了 Pinecone 工程团队将我们的矢量数据库从 Python 和 C++ 重写为 Rust 的经验。该活动的参加人数非常多(超过 178 人注册),这表明人们对 Rust 及其在实际产品中的应用越来越感兴趣。以下是我所讨论内容的回顾,但如果有兴趣了解更多信息,请务必查看完整录音。
Pinecone简介 - 我们为什么在这里?
数据湖、ML Ops、特征存储——这些都是试图解决类似问题的常见流行语。例如,假设您有大量非结构化数据,为了获得洞察力,您将其存储在 blob 存储中。从历史上看,您会为此使用 ML Ops 平台,例如托管的 Spark 管道。然而,在许多方面,我们看到业界开始过渡到向量数据库的概念,特别是近似最近邻 (ANN) 搜索以支持类似的用例。
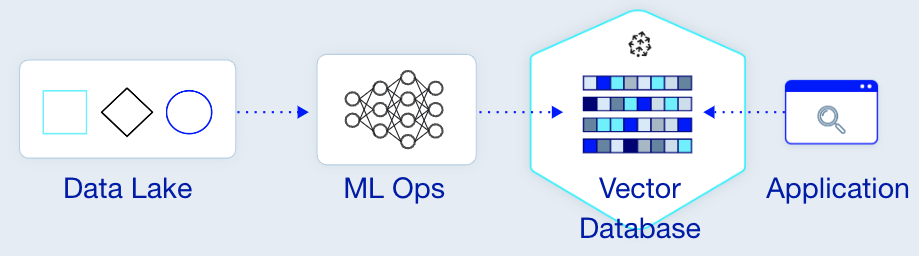
Pinecone 是一个完全托管的 SaaS 解决方案,用于解决 矢量数据库这一难题 。虽然矢量数据库的概念已被许多大型科技公司使用多年,但这类公司已经建立了自己专有的深度学习 ANN 索引算法来服务新闻提要、广告和推荐,这些基础设施和算法需要大多数公司无法支持的大量资源和开销。 Pinecone凭借其严格的内存管理、高效的多线程以及快速、可靠的性能,为解决方案提供了用武之地。
加速使用 Rust
Pinecone 最初是用 C++ 编写的,并带有一个用 Python 编写的连接包装器。虽然这在一段时间内运作良好,但我们开始遇到问题。
首先,Python 是一种垃圾收集语言,这意味着它在大规模编写任何高性能的东西时可能会非常慢。此外,要找到同时具有 Python 和 C++ 经验的开发人员是一项挑战。因此,对数据库进行迭代的想法诞生了——我们希望找到某种方法来统一我们的代码库,同时实现我们需要的性能可预测性。
我们查看并比较了几种语言——Go、Java、C++ 和 Rust。我们知道,当你建立一个开发团队时,C++ 更难扩展和保持高质量;Java 没有提供我们需要的灵活性和系统编程语言;Go 也是一种垃圾收集语言。这给我们留下了 Rust。使用 Rust,在性能、内存管理和易用性方面的优点超过了它尚未成为一种非常成熟的语言的缺点。
识别瓶颈
持续基准测试
当我们开始使用 Rust 时,我们遇到了一些瓶颈。在发布新重写的数据库之前,我们希望确保它继续轻松扩展并具有可预测的性能。我们是如何测试的?通过持续的基准测试。
持续的基准测试使我们能够看到每个提交都被特定基准测试的性能分解。通过 HTML 报告,我们能够在任何时候合并代码更改时看到导致债务回归的确切提交。
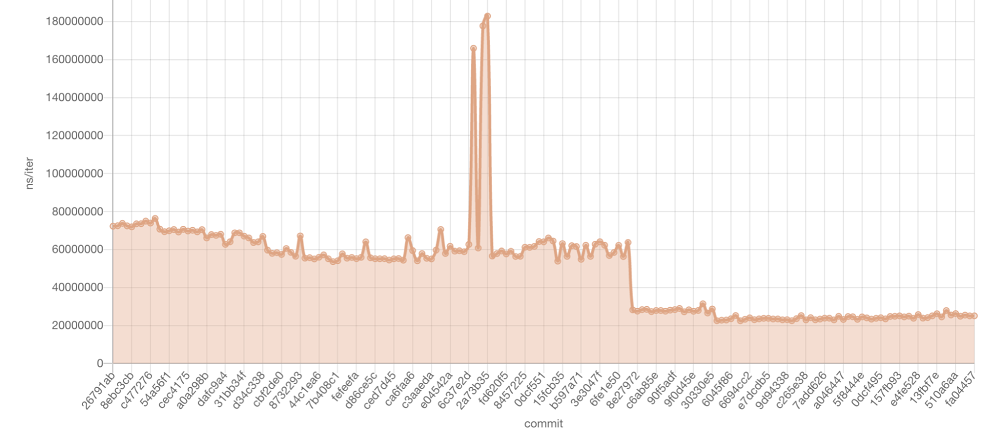
正如你在上图中看到的,一个提交被合并,导致了一个巨大的峰值。但是,借助开源基准测试工具 Criterion,我们能够轻松识别、缓解并推动修复。随着时间的推移,我们降低了延迟并进行了改进。
构建可观察性层
在这一点上,我们已经确认新数据库是高性能的,并且有运行它的基准。但是当你开始生产时会发生什么,事情比他们应该的要慢?这是您需要可观察性解决方案的时候。
如果没有更成熟的开发人员社区的支持,使用 Rust 添加可观察性层可能会很复杂。因此,我们需要一种使用最少仪器、易于集成且与云无关的解决方案。我们的最终目标是提供与 Datadog、Prometheus 或任何其他指标提供程序兼容的层。
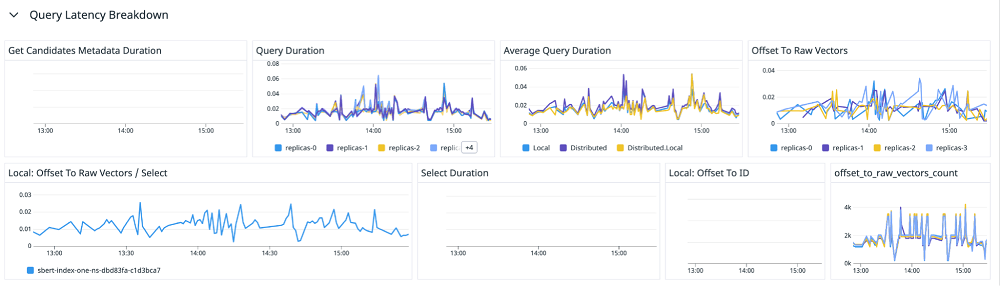
我们的可观察性层有两个主要组件 - 跟踪和聚合指标。通过这些信号中的每一个,您可以看到代码的每个部分随着时间的推移是如何执行的。
我们是如何做到这一点的?对于指标,我们为直方图和计数器指标使用了一些宏。我们还使用了一个与 OpenMetrics 挂钩的自定义 Rust 宏,我们可以从那里将指标推送到 Prometheus 或 Datadog。对于追踪,我们采用了类似的方法。我们实现了一个 OpenTelemetry 协议,允许我们向任何可观察性解决方案发送跟踪。通过这种方式,我们能够在单个仪表板中以图表的形式查看所有指标和跟踪请求(参见下面的示例)。
使用 Rust 优化性能
在识别并解决了上述瓶颈之后,我们能够专注于优化性能。使用 Rust,实现我们喜欢的高性能有几个方面 - 低级优化指令集、内存布局和运行异步任务。
优化指令集
我们在选择 Rust 时考虑的一件事是它对低级优化指令集的访问,这对于优化 Pinecone 使用的基于向量的工作负载类型至关重要。例如,AVX-512 允许我们利用并行点积来计算任何事物的高吞吐量点积查询。Rust 让我们可以直接访问这些编译器优化。
内存布局
如果您使用更高级别的语言,您将无法访问内存的布局方式。一个简单的更改,例如在我们的列表中删除间接性,是我们的延迟提高了一个数量级,因为编译器中有内存预取,并且 CPU 可以预测接下来将加载哪些向量以改善内存占用。
运行异步任务
Rust 是异步的,而Tokio是最流行的异步提供程序之一。它具有高性能、符合人体工程学,并且具有在单个事件循环上运行的选项。但是,它不适用于运行 CPU 密集型工作负载,例如 Pinecone。
在运行这些任务时,有很多选择。例如,由于 Tokio 有不同的运行时模式,您可以在这种多线程异步模式下自行运行它。在这种情况下,您可以就地阻塞单个线程,这称为“block_in_place”。你也可以使用'spawn_blocking'。
还有一些“智能”工作、并行处理库,如Rayon,它们维护线程池并实现工作窃取等功能。最后,您可以选择自己的解决方案。如果你想要更多的控制,你可以使用 MPSC 频道。虽然您必须编写一些自定义代码,但它们为您提供了安排工作和确保数据局部性的细粒度能力。
Pinecone的下一步计划是什么?
我们将继续优化我们的代码库,以确保我们维护一个高性能、稳定和快速的数据库。本次回顾重点介绍了会议期间讨论的要点,但请务必观看完整录音以了解更多详细信息。
如果您有兴趣了解有关 Pinecone 和矢量数据库的更多信息,请查看我们学习页面上的资源。此外,如果您目前正在使用 Rust 或有兴趣使用 Rust,我们正在招聘.
原文标题:Rewriting a high performance vector database in Rust
原文作者:Jack Pertschuk(工程经理)
原文地址:https://www.pinecone.io/learn/rust-rewrite/
评论

 0 点赞
0 点赞


