




--Key Technology:TRCANLZR (TRCA): SQL_TRACE/Event 10046 Trace File Analyzer - Tool for Interpreting Raw SQL Traces (Doc ID 224270.1)
Database Performance Tuning Guide-Using Application Tracing Tools
--Remark :http://docs.oracle.com/cd/B19306_01/server.102/b14211/sqltrace.htm#g33356
https://support.oracle.com/epmos/faces/DocumentDisplay?_afrLoop=431321971800831&id=224270.1&_afrWindowMode=0&_adf.ctrl-state=5jdhhdbq8_29
--------------------------------------------
--原始脚本
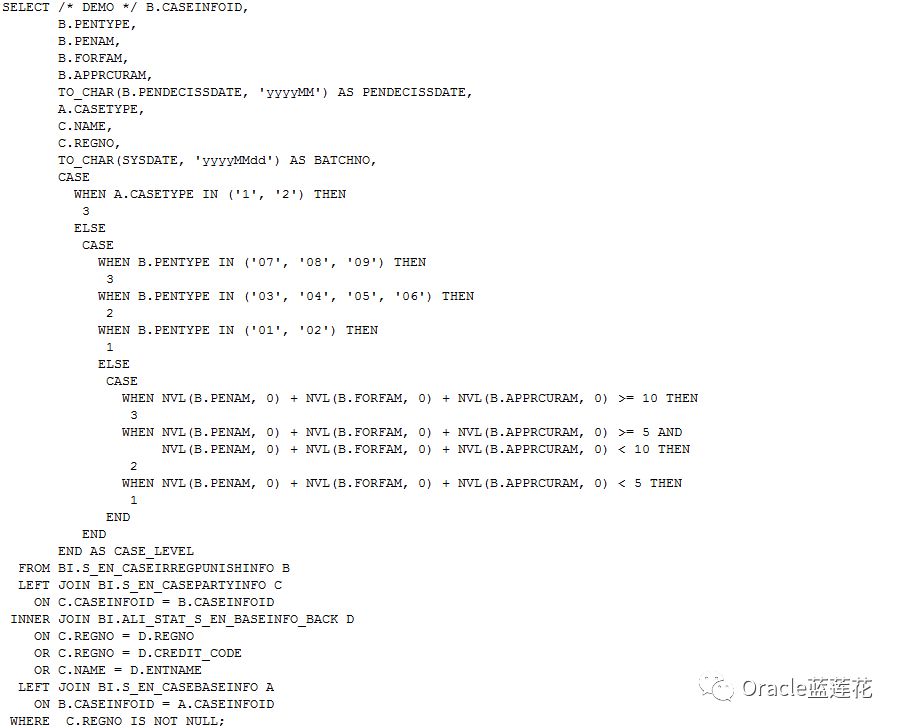
--查询sqlid及其该sql语句对应第一次加载时间、物理读、物理写、共享池占用情况
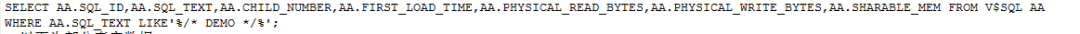
--以下为部分真实数据

--打印游标缓存执行计划
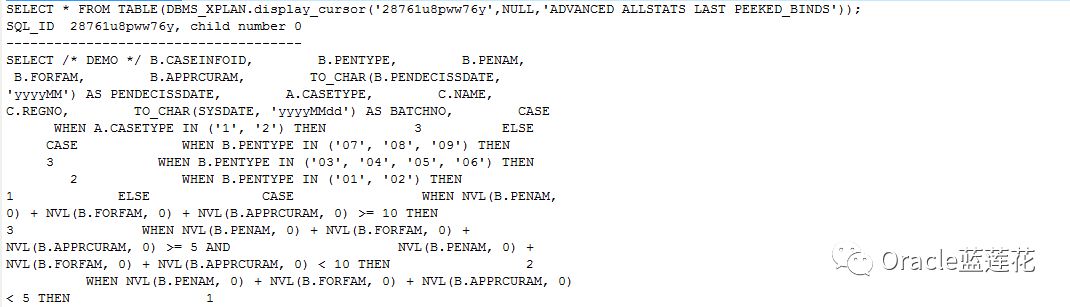
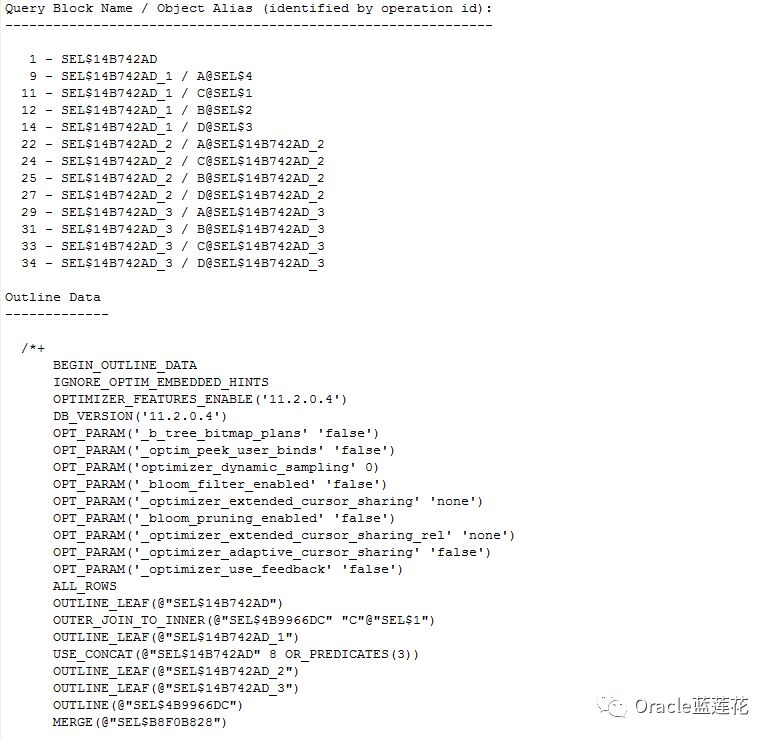
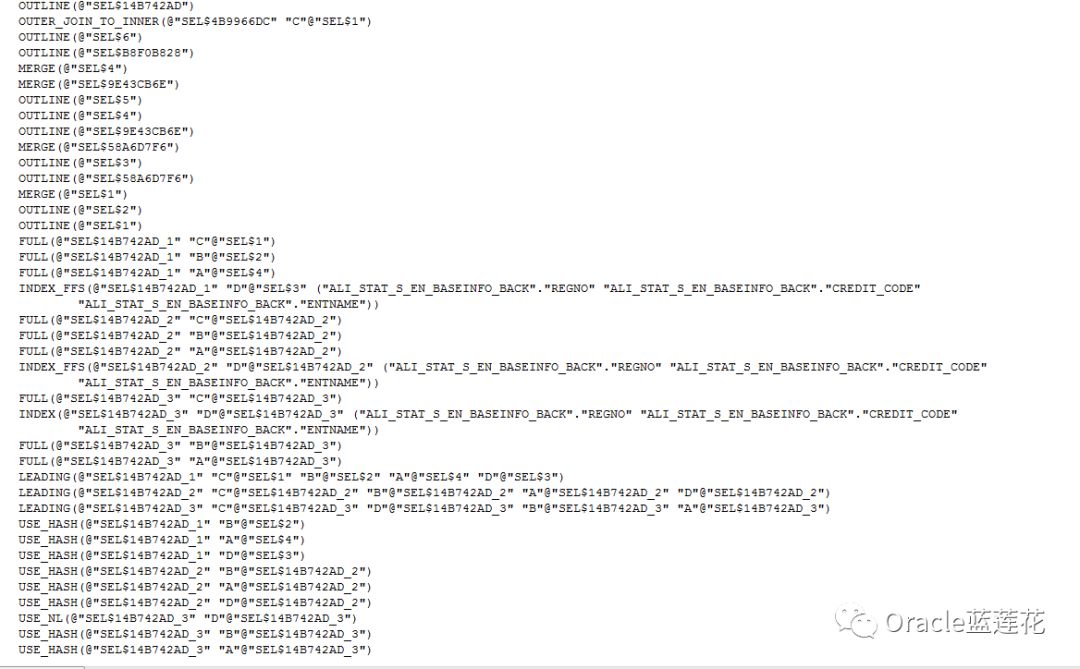
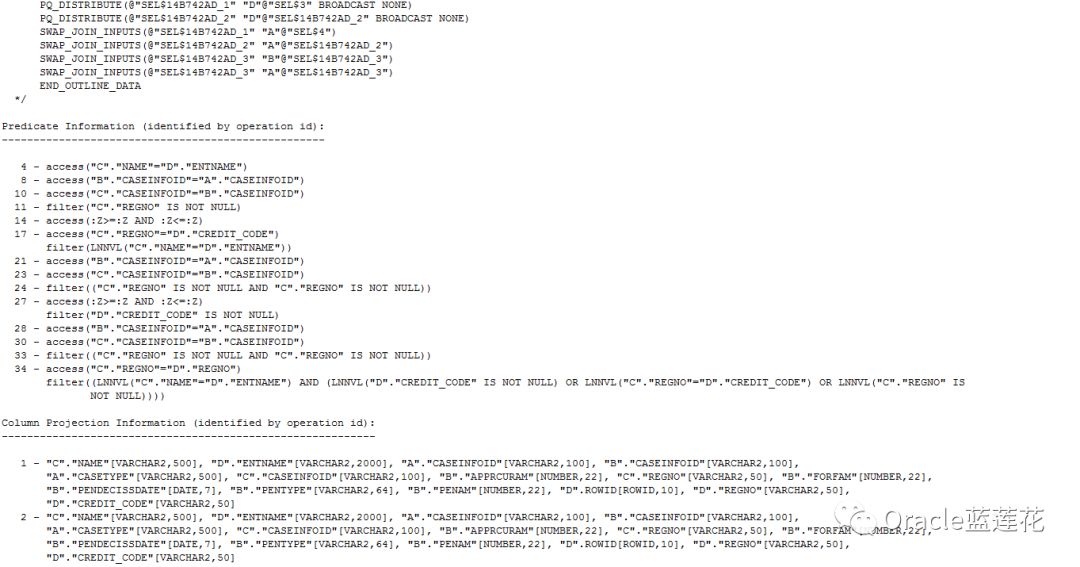



--执行计划分析报告
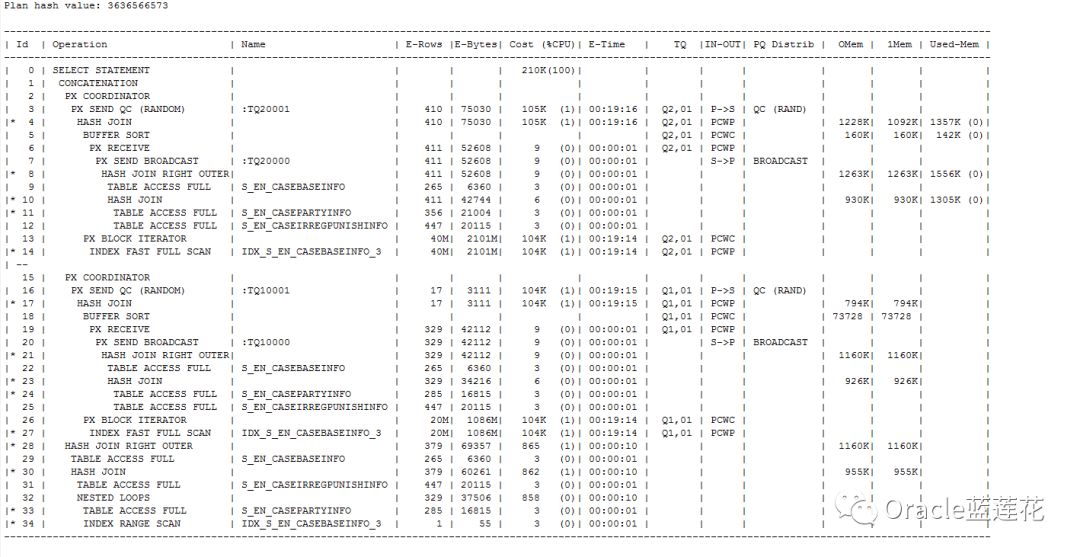
1.执行计划顺序为9-11-12-10-8-7-6-5-14-13-4-3-2-22-24-25-23-21-20-19-18-27-26-17-16-15-29-31-33-34-32-30-28-1-0
2.id 2 、id 15、id 28分别为id 1的子节点,PX COORDINATOR为并行协调session,如果在查询过程中使用并行操作,那么PX COORDINATOR是执行并行操作的第一个步骤。
3.PX SEND QC (RANDOM)为并行服务器进程基于enqueue send检索后的数据到COORDINATOR,enqueue本身为COORDINATOR于并行服务器交互的通道,如遇到TQ SQ RQ 都表示enqueue信息
4.id 9 S_EN_CASEBASEINFO做全表扫描,预估基数行源为265行,实际也是265行数据,它作为主节点与进行了散列连接的S_EN_CASEPARTYINFO S_EN_CASEIRREGPUNISHINFO做哈希右连接,
5.id 11有谓词条件,过滤了"C"."REGNO" IS NOT NULL,sql语句最后一段代码,该表实际数据量为444条,预估行源为356条,以上操作均未用到多线程。
6.id 8有谓词条件,对应sql语句中B.CASEINFOID = A.CASEINFOID,注意id 7,cbo工作原理为Producer与Consumer基于enqueue交互,S代表Serial,P代表Parallel,所以S->P表示
单个进程执行的串行操作向多个进程同时执行的并行操作发送数据,开始发送并行操作。PQ Distrib表示数据分发,分发方式为BROADCAST广播。
7.id 6为id 7的父节点,PCWP表示id6对于id 7的父操作,父子操作都是并行操作,但必须由同一进程完成。
8.其中执行计划id 5中的PCWC表示与子操作捆绑进行的并行操作
9.与id 5同一个行源的id 13有个子节点为id 14,做了索引快速全扫描,有人可能会问,整个sql都没有排序操作,为什么会出现BUFFER SORT,因为快速全扫描是无序的,IDX_S_EN_CASEBASEINFO_3
索引预估大小40M,占据了整个全节点流程从id 3到id 14的全部cost消耗,基于第一个节点分析,索引使用了并行,且占用了一号节点大部分cost
10.从id 16到id 27节点,几乎和以上id 3到id 14执行计划内容完全一致,重点关注的是,id 14和id 27索引预估大不同,一个20M,一个40M,但返回cost成本消耗却是相同的。我们来关注一下
id 14和id 27的谓词条件access(:Z>=:Z AND :Z<=:Z),注意,这种谓词条件是basic+parallel+predicate参数的输出结果,显示了并行查询执行计划的详细信息,显然,通过两个节点
的对比,不难看出,该执行计划的重点在索引执行了并行操作后,预估成本大小出现了蹊跷。下面我们来验证当前索引并行度,解决索引,便可解决该执行计划。
11.执行计划中需要解决
ON C.REGNO = D.REGNO
OR C.REGNO = D.CREDIT_CODE
OR C.NAME = D.ENTNAME这三个条件的join关系
并行执行计划中相关名词解释:
数据分发(Distribution):在并行查询中,每一个生产者进程都只会获取相互之间不重叠的一部分数据,而消费者在执行某些操作(如关联)时,需要从多个生产者获取数据,生产者就需要按照一定方式将数据分发给需要其数据的消费者。执行计划中,PQ Distrib字段表示分发方式。
在并行查询中,同一个操作可能会有多个进程同时进行,因此,在执行计划中需要描述父子操作之间关系,字段IN-OUT就是显示该信息。并行操作之间关系包括:
并行至串行(Parallel to Serial,P->S):多个进程同时执行的并行操作向单个进程执行的串行操作发送数据,其数据的发送、接收需要通过表队列(Table Queue)完成。如并行服务进程向协调者发送数据。
并行至并行(Parallel to Parallel,P->P):多个进程同时执行的并行操作向多个进程同时执行的并行操作发送数据,其数据的发送、接收需要通过表队列(Table Queue)完成。如多个生产者进程向多个消费者进程分发数据。
串行至并行(Serial to Parallel,S->P):单个进程执行的串行操作向多个进程同时执行的并行操作发送数据,其数据的发送、接收需要通过表队列(Table Queue)完成。如某些情况下,并行进程的并发操作的子操作无法并行执行,或者子操作的对象太小,并行化代价大于串行代价。
与父操作捆绑进行的并行操作(Parallel Combined With Parent,PCWP):父子操作都是并行操作,但必须由同一进程完成。
与子操作捆绑进行的并行操作(Parallel Combined With Child,PCWC):父子操作都是并行操作,但必须由同一进程完成。
并行颗粒(Granule):并行处理中的最小工作单位。Oracle将可并行操作(如表扫描)划分为若干个颗粒,并行服务进程每次执行一个颗粒的操作。包含数据块范围(Block Range)颗粒和分区(Partition)颗粒:
数据块范围(Block Range)颗粒:数据块范围颗粒是并行操作中的最基本颗粒。并行服务进程每次读取或操作一段连续的数据块。
分区(Partition)颗粒: 每个并行服务进程操作一个分区或子分区。因此,这种颗粒划分情况下,分区数量决定了最大并行度。通常在对本地分区索引进行范围扫描或者分区表之间进行关联时可能会以分区为粒度
轮询(Round Robin):轮询是一种最简单的资源选取方式。每一次从一组资源队列中选取一个,且为上一次所选取资源的下一个资源,如果选取到了队列的末尾,则从第一个继续轮询
----------------------------------------
--trca分析报告:

执行阶段一致性读为7,fetch阶段为1030,实际返回行数为170行
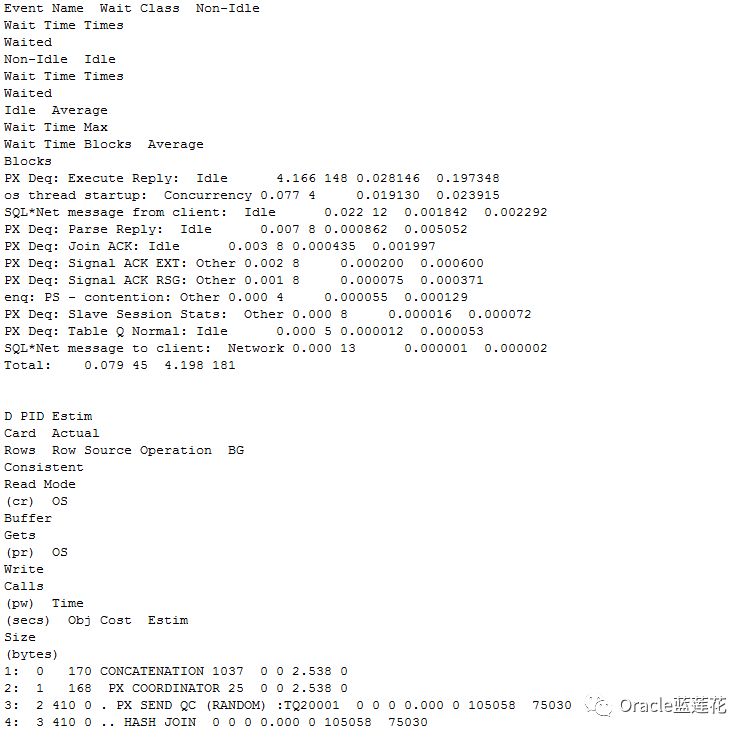

重点关注执行计划中cost成本消耗较高的内容
1.执行计划中id 4做HASH JOIN,预估行数为410行,对应谓词条件是C.NAME=D.ENTNAME,实际返回0行记录,无一致性读,无物理读,物理写消耗
2.id 13是id14父节点用户返回索引快速全扫描的并行处理,该步骤对应绑定变量谓词条件分别为REGNO CREDIT_CODE ENTNAME三个字段
该笔操作预估行源为40063599 ,时机返回的记录数为0,同样没有物理读,物理写和一致性读,但该笔没有任何记录数返回的执行计划步骤缺
消耗了104831 cost.
3.id 16是id 17的父节点,执行计划内容HASH JOIN,对应谓词条件,cbo做了隐式转换,ACCESS为C.REGNO=D.CREDIT_CODE,FILTER为LNNVL(C.NAME=D.ENTNAME),
该笔操作预估行源17行,实际返回0行,缺也消耗了104997cost
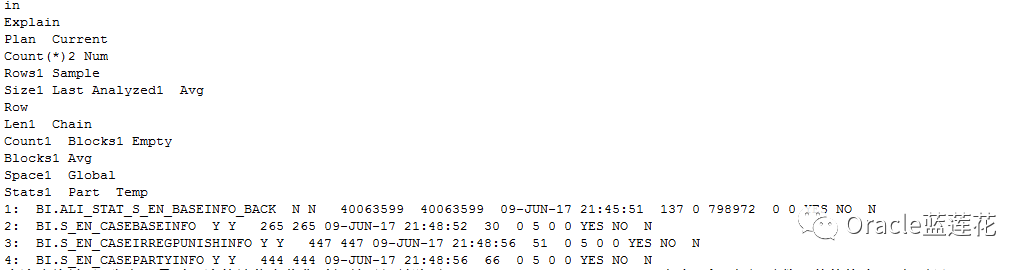
本次查询涉及4张表,最后一次统计信息收集时间是6月9号除了ALI_STAT_S_EN_BASEINFO_BACK表为4千万行记录数,其他均为500行以里
更多关于表,索引属性详细信息详见trace附件内容
--------------------------------------------------
--SQL改写方式

-------------------------------------------------
--SQL改写后的执行计划

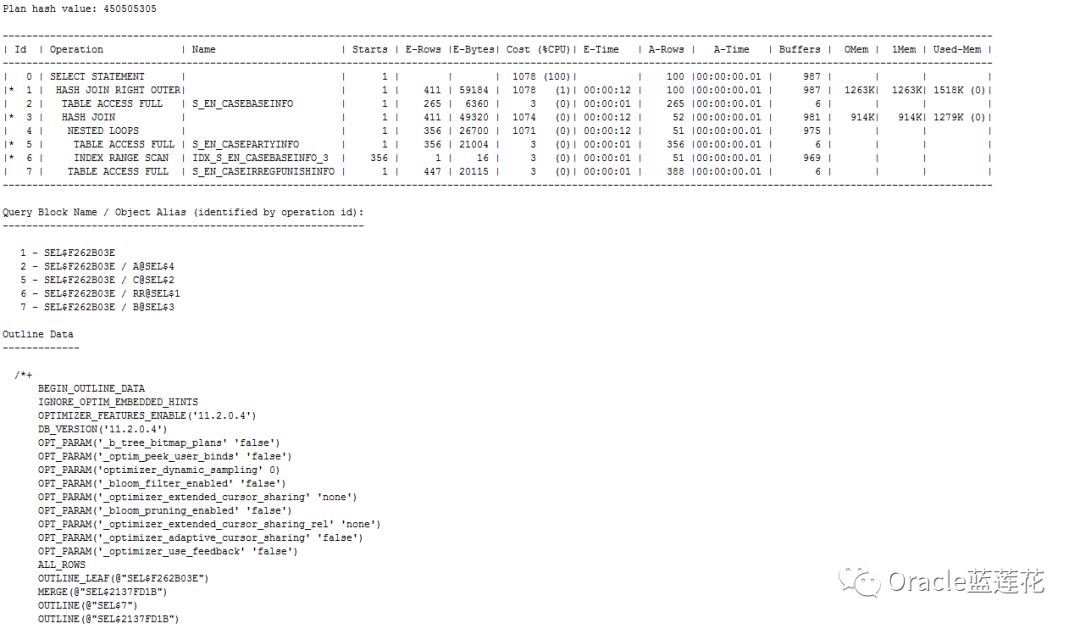

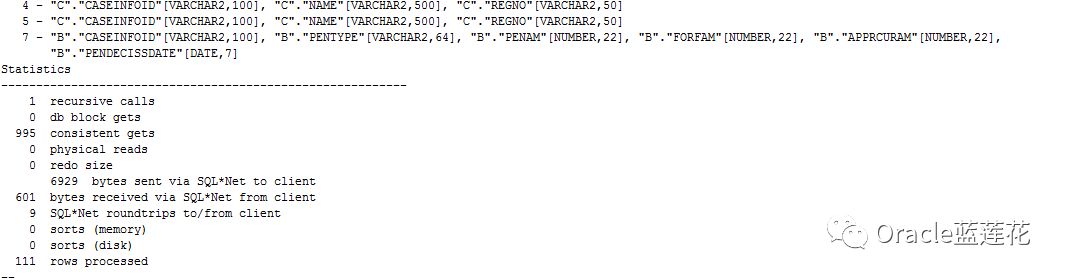
1.改写后整体 consistent gets下降,sql递归循环调用下降,由于我们通过trace ANALYZE 分析出来对应三组or的关键条件返回记录数有两个条件为0条
和业务部门沟通后,基于REGNO主键关键后面无结果集关联方式可以忽略。
2.新的执行计划顺序为2-5-6-4-7-3-1-0
3.其他不用说了,很简单
---------------------------------------------------------
《点亮梦想,拒绝平庸》
600团队 (QQ群:851604218)
