大数据 / 人工智能 / 区块链 / 数据库 / 分布式存储
 分布式存储,简而言之就是将数据分散存储在多个独立的节点上。由于其具备高可扩展性、高可靠性、高安全性等特点,在大规模数据应用场景下有着广泛的应用。但是,由于相对传统的集中式存储,分布式存储的系统架构更加复杂,因此在实际应用中也容易遭遇更多的“坑”。本期为您介绍硬盘损坏后的数据恢复处理。
分布式存储,简而言之就是将数据分散存储在多个独立的节点上。由于其具备高可扩展性、高可靠性、高安全性等特点,在大规模数据应用场景下有着广泛的应用。但是,由于相对传统的集中式存储,分布式存储的系统架构更加复杂,因此在实际应用中也容易遭遇更多的“坑”。本期为您介绍硬盘损坏后的数据恢复处理。
许军宁 | 文
© 中兴数据智能(ZTE-DI)出品
硬盘引起的麻烦
“
小Q:上次说到硬盘坏了,有各种修复机制和策略来保证数据安全,可硬盘损坏时不仅有已经保存数据的问题,正在读写操作的数据也应该受影响吧?
小A:硬盘损坏时,正在进行的读操作会失败,相应的请求会被重新定向到冗余数据;正在进行的写操作也会失败,相应的请求同样会被重定向到正常的硬盘。所以正在进行读写操作的数据是不会有问题的。小Q:读写要做重定向,那么系统的响应速度不是会变慢么?小A:是的,目前还做不到完全无影响。但另一方面,相对于系统的硬盘总量,单块硬盘的占比是很小的,其损坏时,正在其上进行操作的文件或数据块数量相对有限。而且重定向读写的过程,与再读写一次同样大小的数据相当,从代价上评估,大致相当于耗时2倍或再略多一些。整体上看,影响范围和程度都很小。小Q:又想到一个问题啊,前段时间,几位新同事领了一批PC机,这两天听说有一位的硬盘特别慢,好像也不报错,除了读写慢,也没啥其他问题。分布式存储系统中的硬盘是否会有类似的情况呢?小A:这类情况也会有的,而且不罕见。硬盘不报错,但特别慢的原因有很多,磁盘设备异常或者老化是重要的因素之一。对于这种情况引起的读写能力下降,需要专项的慢盘监控检测机制分析识别。小Q:又要安排专门的机制啊,这样的话,系统又要复杂一些了。小A:这是保证系统服务稳定性的必要代价。事实上,针对硬盘的监控检测,远超前面说的慢盘识别范围。硬盘引起的麻烦类型很多,例如,偶尔读写卡一会的;说不清啥时候突然下线又迅速恢复的;甚至突然卡住,拖垮本机操作系统的。相应的检测机制需要尽可能覆盖各种硬盘引起的麻烦,及时识别并处理应对。进一步地,对于可能会出问题的硬盘,还需要引入预测机制,评估损坏风险,及早采取措施应对。
”
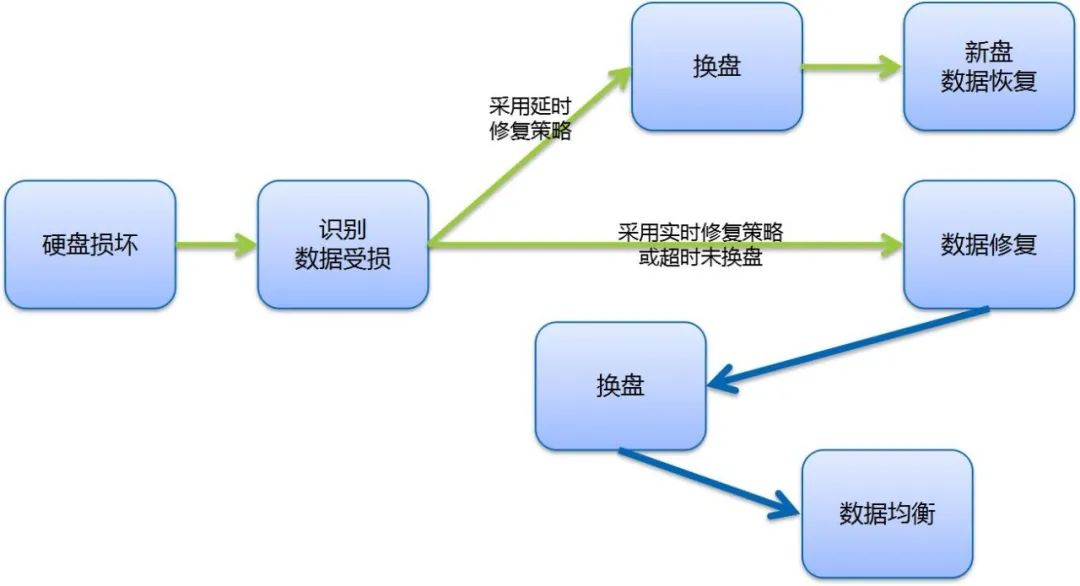
大型分布式存储系统中,由于硬盘数量众多,硬盘损坏已经成为常态,相关数据恢复处理手段丰富,机制已经非常成熟。
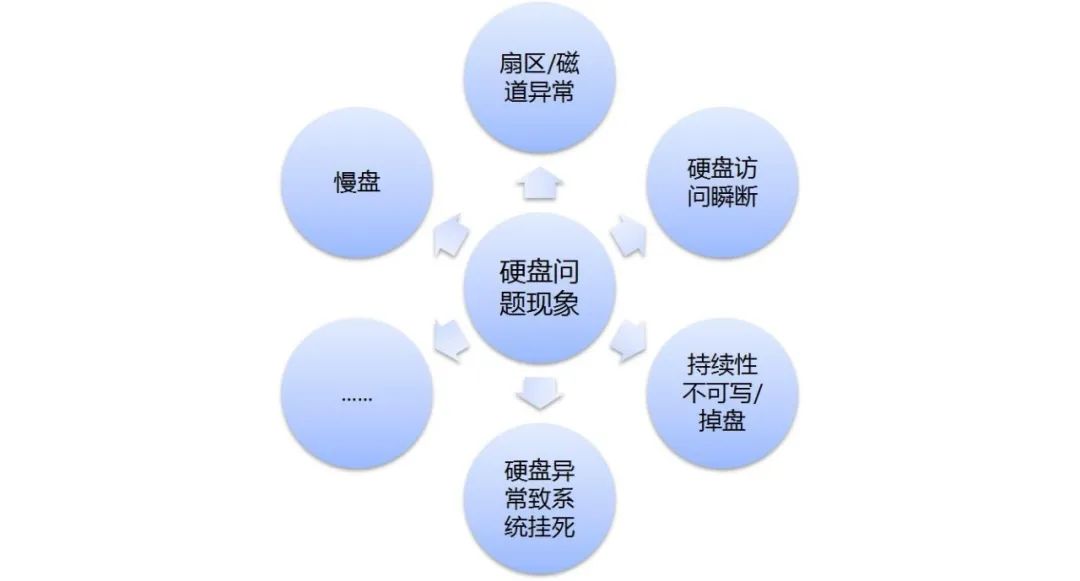
另一方面,硬盘问题除了对存储数据可靠性有影响外,对于系统持续提供稳定的服务也构成一定的影响,特别是服务质量要求较高的场合。常见的影响服务质量的硬盘问题包括:
慢盘:常见于传统机械硬盘,通常除了读写操作速度慢以外,没有其他明显异常。
扇区/磁道异常:常见于传统机械硬盘,其表现为写入数据失败或者已保存的数据损坏,前一种情况对数据写入/变更类操作延时有影响,后一种情况对数据读取延时有影响。
硬盘访问瞬断:见于各类硬盘,对于数据读写操作响应速度均有影响。
持续性不可访问/掉盘:见于各类硬盘,对于数据读写操作响应速度均有影响。
硬盘异常致操作系统层挂死:见于各类硬盘,对于所有数据操作响应速度均有影响。
针对上述问题,可以对潜在问题硬盘采取主动监控识别与处置措施,典型的环节包括:
1)参数采集
采集与硬盘运行健康状态相关的各类参数,主要有:smart信息,IO指标信息,系统资源参数信息等。smart信息与硬盘密切相关,是一种自动的硬盘状态检测输出。不同厂商、不同类型接口(SAS、SATA、NVME等)以及不同介质(磁盘、SSD等)的硬盘smart信息存在较为明显差异,应根据具体硬盘型号或类型建立相应的smart信息清单,以便采集和后续数据分析比对。IO指标信息,以操作系统层监控到的磁盘吞吐指标为代表,参考意义较高的指标项包括:每秒传输次数、每秒读取数据量、每秒写入数据量、硬盘时间利用率、平均请求队列长度、每IO请求平均处理时间、每IO操作服务时间等。系统资源参数信息,主要指与硬盘处理相关的存储系统相关资源占用指标、流程处理耗时指标等,这是从存储系统层面获得的度量值。综合运用参数采集结果,以多种方式分析硬盘风险状态,主要有:慢盘分析、实时风险识别、生命周期预测等。慢盘分析:重点考察响应时延类指标,结合队列长度、负载情况等指标,识别标记出显著慢于其他硬盘的疑似慢盘。实时风险识别:重点监控硬盘运行状态类特征指标和特征信息,识别标记出已经发生损坏的或者疑似即将发生损坏的硬盘。生命周期预测:以基于历史异常盘数据训练的AI模型为基础,识别标记出短期内可能发生损坏的高风险硬盘。对于已经识别出的坏盘、慢盘或其他高风险硬盘,可以视具体的状态现状类型采用不同的处理策略,例如:风险盘限流,进行只读访问,也可以同时增扩涉及数据的副本或纠删码分片,后续视状态劣化程度转入隔离或踢除操作;风险盘隔离,涉及数据复制/修复至其他硬盘;风险盘踢除,视同出现坏盘,直接修复相关数据。 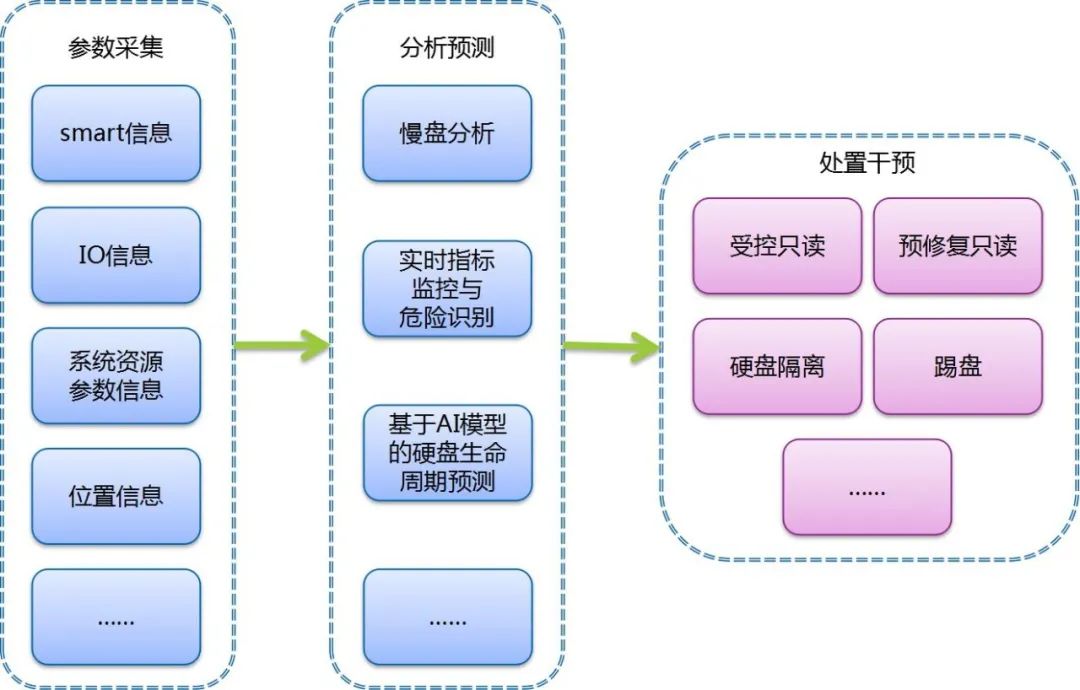
* 本文为中兴数据智能原创文章,转载请留言或评论获取授权。









