




每个函数都有一个易失性级别VOLATILE,STABLE或者 IMMUTABLE。如果创建函数命令没有明确声明范畴的话, 那么VOLATILE就是缺省的。
函数的易失性级别可在视图查知
postgres=# select distinct provolatile from pg_proc;
provolatile
-------------
i
s
v复制
VOLATILE可以做任何事情,包括修改数据库。它可以在使用同样参数调用时返回不同的结果。优化器对这样的函数不做任何假设。一个使用易失函数的查询在需要数据值的时候每次都重新计算函数的值。
STABLE函数不会修改数据库, 并且保证在同一个查询的环境里给出相同参数的情况下,会给出相同的结果。这个范畴允许优化器在一个查询里把多个函数调用优化成一个。特别是在索引扫描的条件表达式里面包含这样的函数是安全的。因为索引扫描只计算一次比较值,而不是每行一次。在索引扫描条件里使用一个VOLATILE函数是非法的。
IMMUTABLE函数不会修改数据库, 并且保证在任何情况下同样的参数永远返回同样的结果。这个范畴允许优化器在查询调用函数的时候预先把函数计算成一个常量参数。比如,类似SELECT … WHERE x = 2 + 2的查询可以简化成 SELECT … WHERE x = 4,因为在加法操作符下层的函数是标记为 IMMUTABLE的。
下面进行实例测试
创建表并插入数据
create table tmp (id int);
insert into tmp select generate_series(1,5) id;复制
创建volatile级别函数
create or replace function test(i int) returns int as $$
declare
begin
raise notice '%',i;
return i;
end;
$$ language plpgsql volatile;复制
1、volatite级别函数在同一个查询中, 同样参数的情况下可能被多次执行
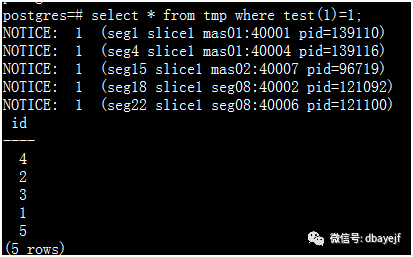
查询的结果有5行,test函数共执行了5次
2、优化器可根据实际场景优化stable级别函数的调用次数, 同样的参数多次调用可能减少成单次调用
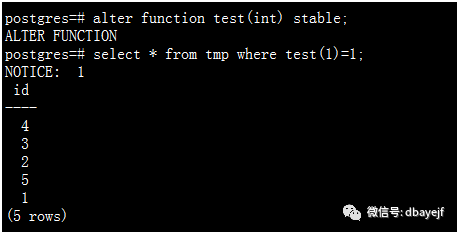
查询的结果有5行,test函数只调用一次,immutable级别也是一样。
3、immutable与stable的区别
优化器在处理immutable函数时, 先评估函数结果, 将结果替换为常量
函数级别为stable时
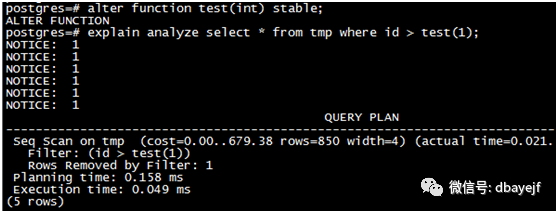
顺序扫描表时,test函数执行了5次
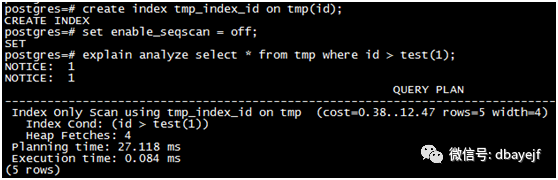
索引扫描表时,索引扫描仅评估被比较的表达式一次, 后多次与索引值进行比较,所以test函数调用了再次
函数级别为immutable时
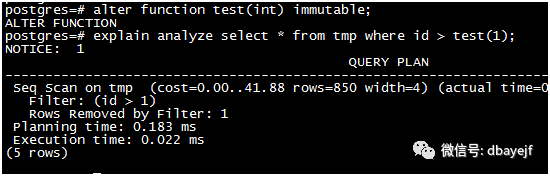
优化器先评估函数结果, 将结果替换为常量
4、volatile级别函数没有限制, 可以修改数据, stable和immutable不允许
create or replace function test2() returns int as $$
declare
begin
update tmp set id = id;
return 0;
end;
$$ language plpgsql volatile;复制
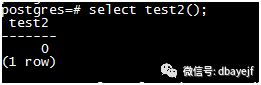
函数级别为volatile修改成功
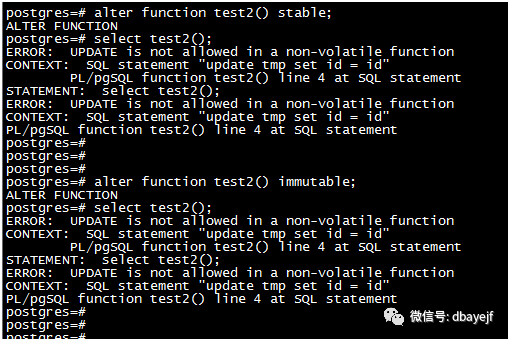
stable或immutable级别时均报错
5、stable和immutable级别函数执行时,始终保持当前snapshot
create or replace function test3() returns int as $$
declare
cnt int;
begin
for i in 1..5 loop
PERFORM pg_sleep(3);
select count(*) into cnt from tmp;
raise notice 'cnt:%',cnt;
end loop;
return 0;
end;
$$ language plpgsql stable;复制
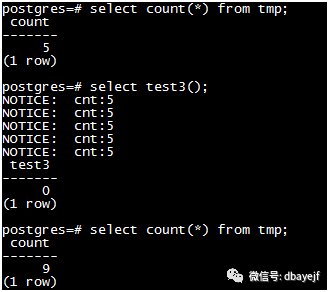
函数级别为stable或immutable时,对外部已提交的数据不可见
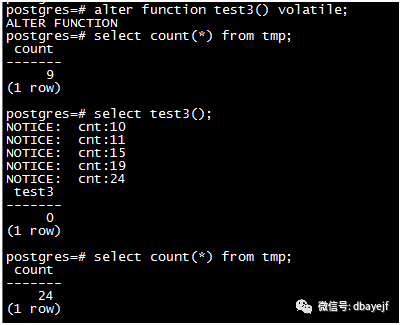
函数级别为volatile时,对外部已提交的数据可见
所以,理解函数的immutable、stable和volatile,有助于我们选择正确的方式进行功能函数的开发,例如当GP4升级到GP5或者GP6版本时,由于底层pg8.2版本的升级,原来类型的隐式转换变成了显式转换,之前函数的代码编写时有可能没注意这一块,导致升级后字段对比时会报错,我们得修改函数内容代码或者编写类型的转换函数来打补丁,这时就需要注意使用哪个级别的函数了,不然有可能会使函数性能变慢的情况。
