





文章转载自公众号:励志成为PostgreSQL大神
作者:吟游诗人义宝
前言
今天妹子又在QQ群里喊XXX系统好慢。"DBA小哥在不在啊?程序太慢了,能不能帮我们看看呢?
定位SQL
先看部署的 SQL监控,发现她喊的时间点确实有2个SQL是非常慢的。
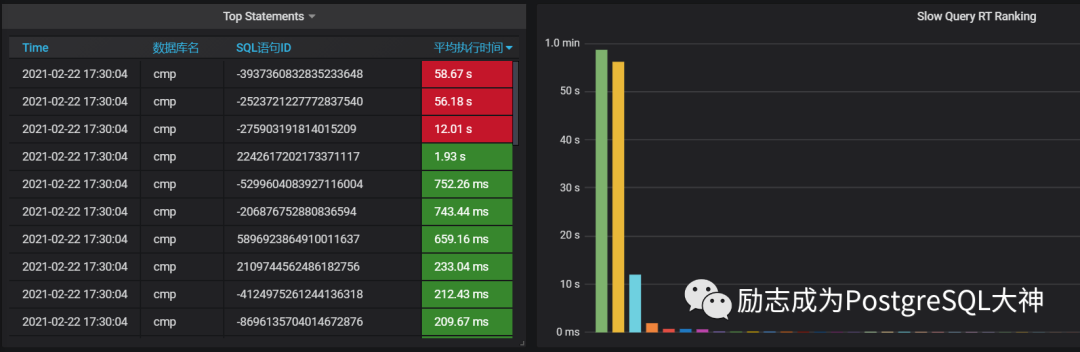
登陆系统查看pg_stat_statements并根据qerryid立即找到了query文本,但因为使用的是绑定变量1,2。因此,我们还需要根据文本到 log中查找SQL详细的SQL。最终发现的 SQL如下:
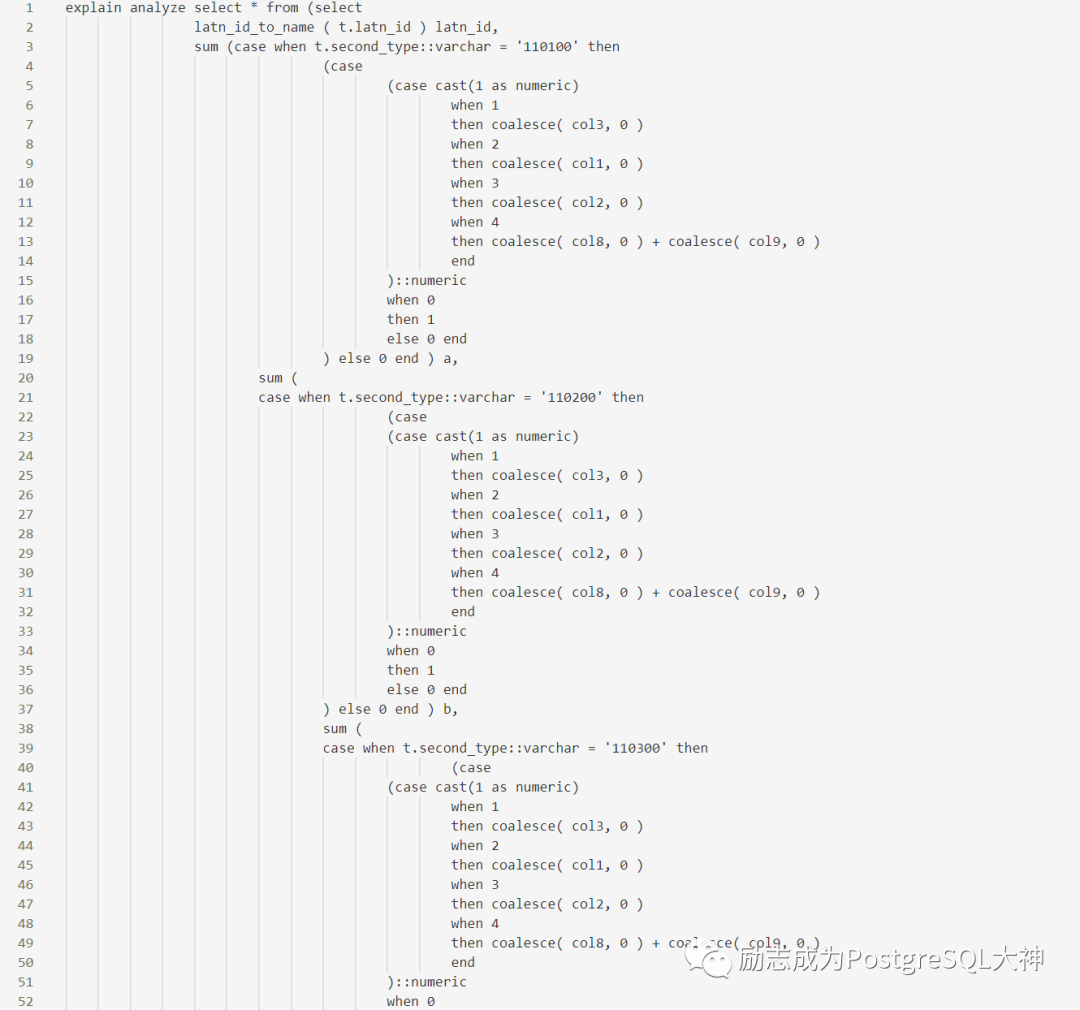
此处无法完全粘贴,整个SQL总共有128行代码,一次手工执行大约需要90秒。
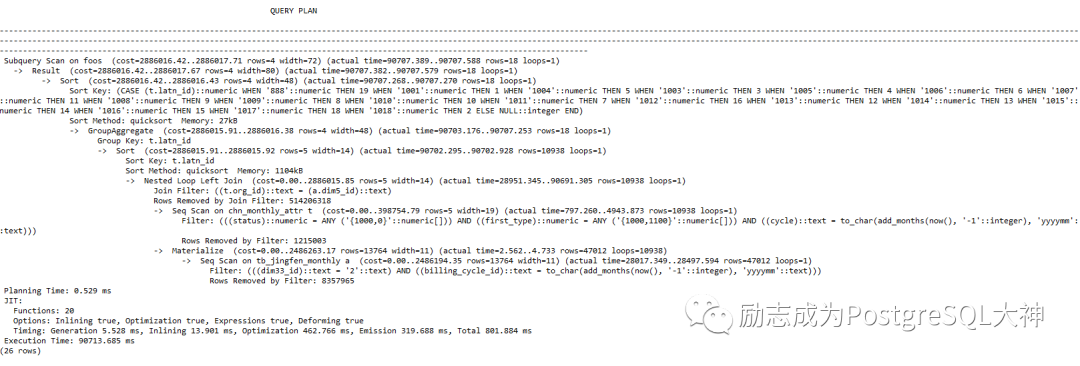
优化SQL,层层剥离
SQL和执行计划都拿出来,然后将执行计划拷贝到我之前发布的执行计划格式工具网站上。(https://explain.depesz.com/)
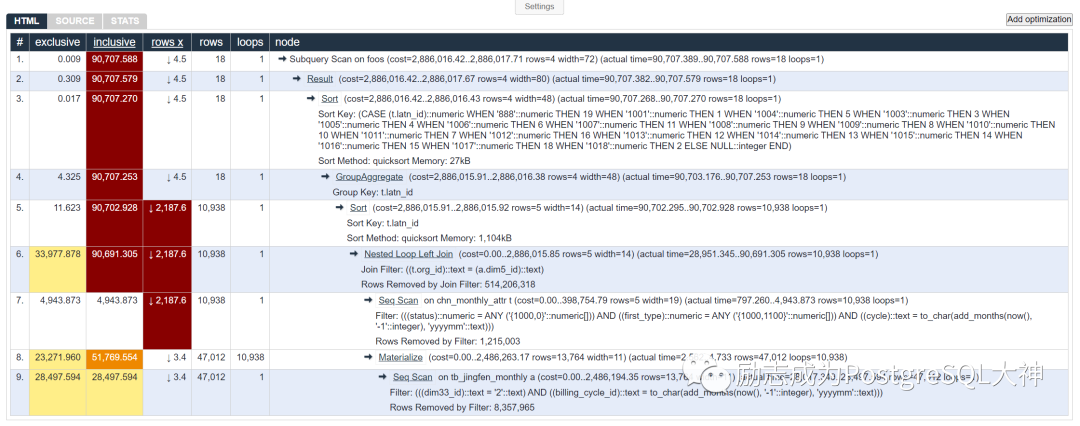
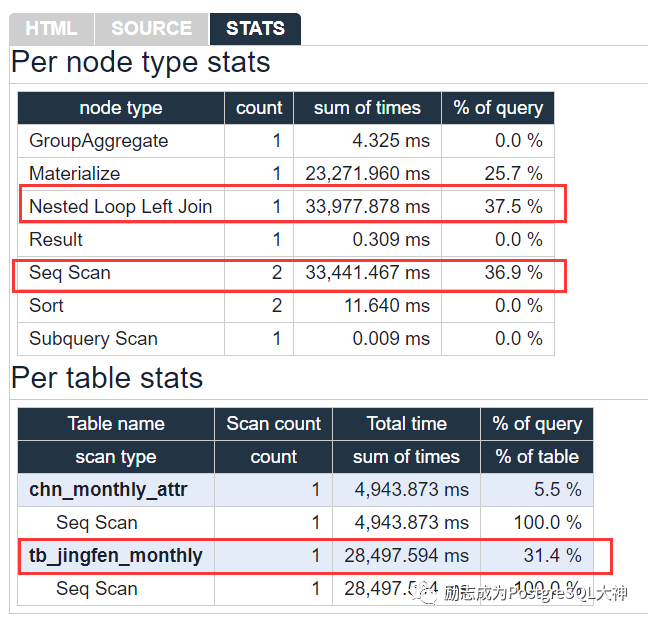
请注意,在Seq Scan和 Nested Loop Left Join上的消耗是最大的,分别占36.9%和37.5%。另外, Seq Scan主要有两张表,对「tb_jingfen_monthly」表的全表扫描占31.4%。因此优化首先要从这个全表扫描开始。该全表扫描的过滤条件是步骤9。

您可以看到总共有800万数据,两个过滤条件在筛选数据之后只有47012行,因此在这种情况下,应该可以使用索引。
cmp=> select count(1) from cmp.tb_jingfen_monthly; count --------- 8404977(1 row)cmp=> select count(1) from cmp.tb_jingfen_monthly a where a.dim33_id::varchar = '2'; count --------- 2789589(1 row)cmp=> select count(1) from cmp.tb_jingfen_monthly a where a.billing_cycle_id::text = to_char( add_months ( now(),- 1 ), 'yyyymm' ); count -------- 141036(1 row)
经过进一步测试,我们发现billing_cycle_id上这个过滤条件,过滤后只有14万条数据。对表结构的进一步检查发现在表的billing_cycle_id字段中已经有索引。
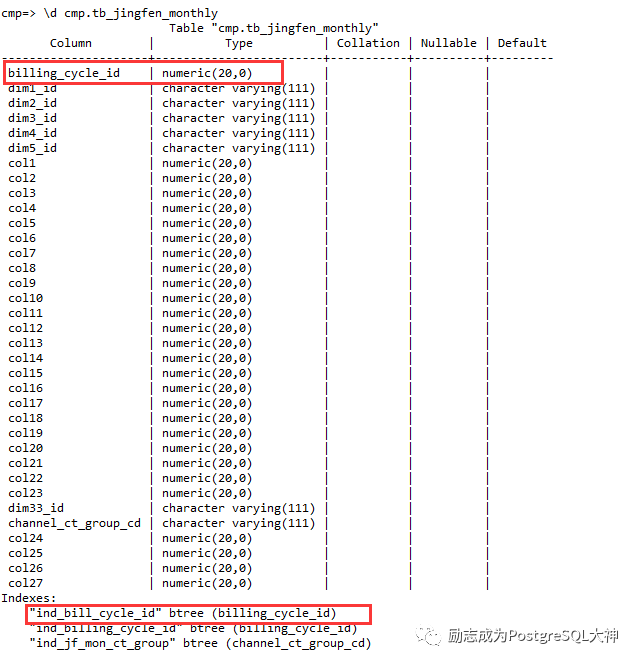
目前得出的结论是,开发强制转换数据类型,这将导致索引不可用。我们把这个SQL的谓词条件转换为普通的数值类型就能走上索引,然后再次生成执行计划。还要花68秒

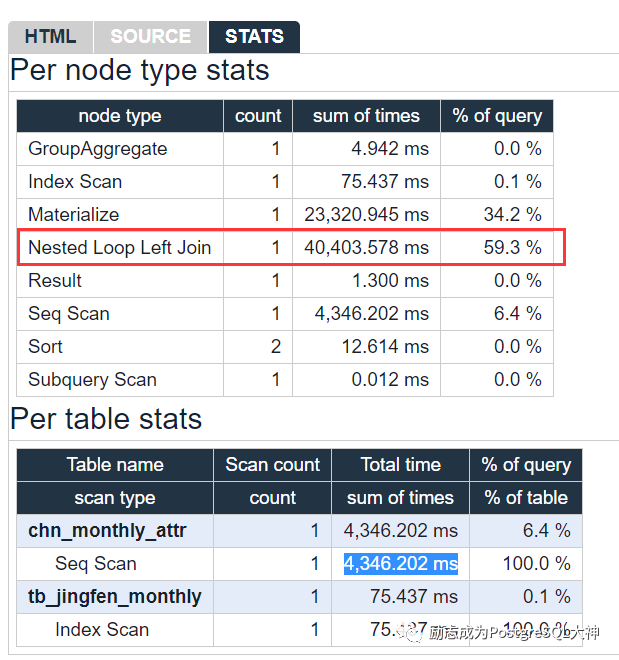
这回主要是Nested Loop Left Join,大约占59.3%。nested Loop Left Join主要是步骤6。

该位置的过滤条件为t.org_ id::text= a.dim5_id::text,我们看一下表,表由左向右连接,这里被连接的表还是cmp.tb_jingfen_monthly。而字段dim5_id是 character varying类型。
而且发起左链接的表org_id字段也是character varying类型。
对cmp.tb_jingfen_monthly表进行手工统计,看看是否适合在dim5_id上创建索引。
cmp=> select dim5_id,count(1) from cmp.tb_jingfen_monthly group by dim5_id having count(1)>500; dim5_id | count ---------+------- -1 | 389
可见,这张800万的表,dim5_id字段是没有倾斜值的,非常适合创建索引。
create index concurrently ind_dim5_id on cmp.tb_jingfen_monthly(dim5_id);
建立索引后,再次测试 sql的速度。
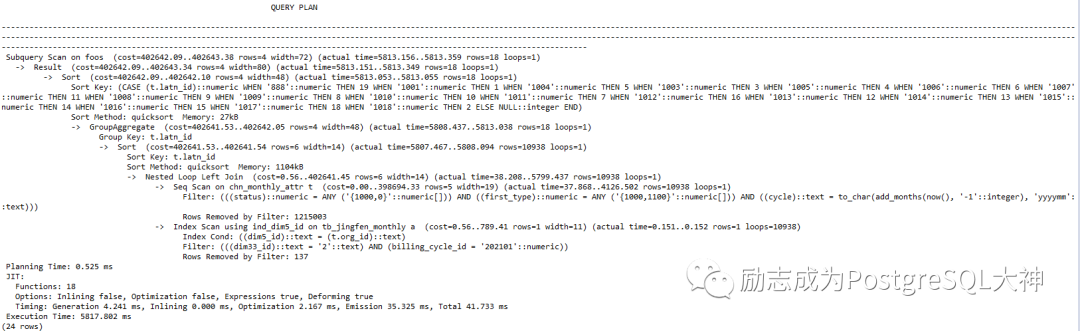
这次足够快了,只用「5」秒就出结果了。
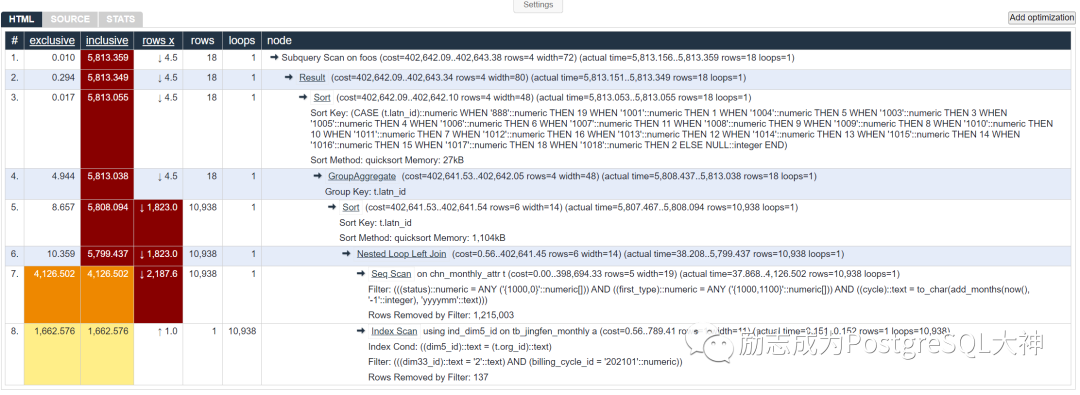
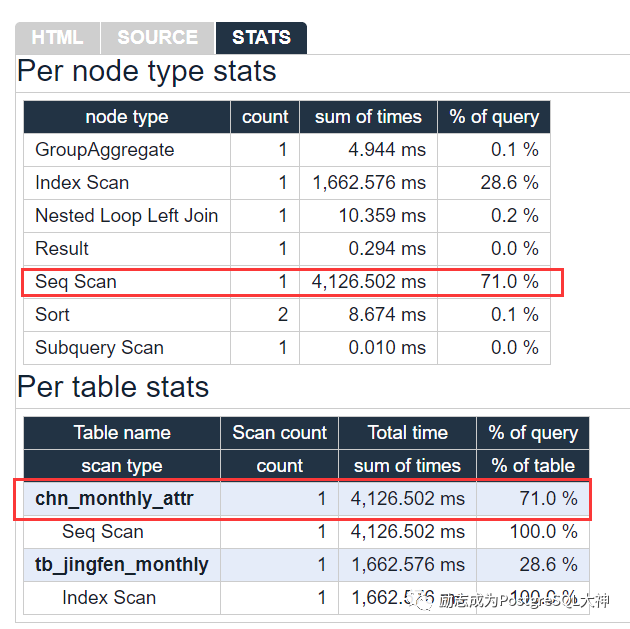
这次又慢在Seq Scan上了,71%的时间消耗来自于对chn_monthly_attr表全表扫描。
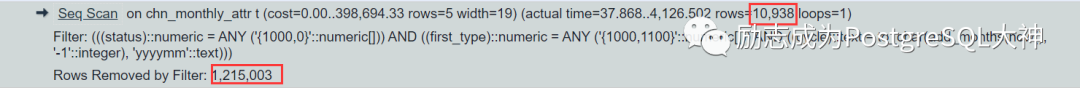
这里看上去,过滤条件也可以。查看chn_monthly_attr表字段cycle的类型。
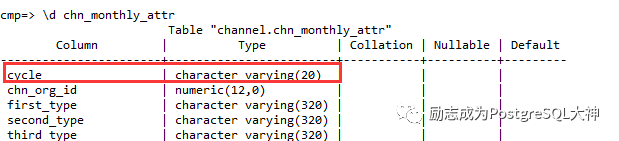
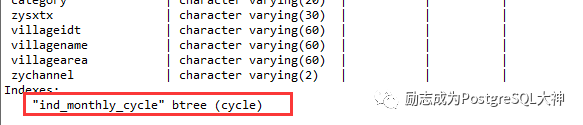
为字符串类型,上面带有索引。在这里我们直接用常量再次测试。
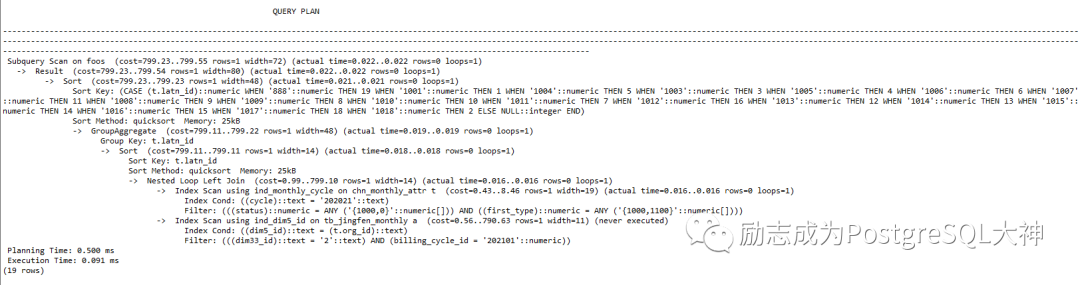
直接优化到「0.091ms」。
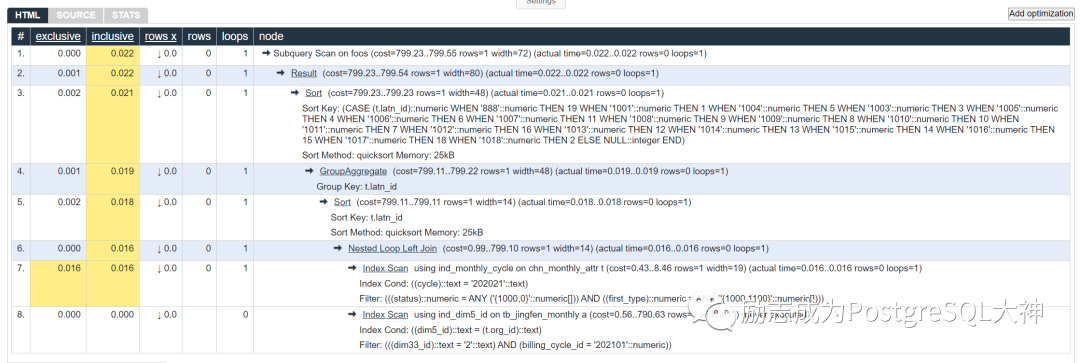
简直是好的不能再好了。
后记
"妹子,你的 SQL语句可以从90秒优化为0.09 ms,但你需要修改一下。"
"DBA小哥,真的很感谢,哪里需要改造?"
"主要是两点,你们得改改"
1.改造a.billing_cycle_id这个条件,这里是numeric类型,最好通过程序计算出来,然后直接在这里代入整型值就行。
a.billing_cycle_id::text = to_char( add_months ( now(),- 1 ), 'yyyymm' )
2.改造t.cycle这个条件,这里的类型是字符串类型,最好通过程序计算出来,然后直接在这里代入字符串类型就行。
t.cycle = to_char(add_months( now(),- 1 ), 'yyyymm' )
3.在cmp.tb_jingfen_monthly表的dim5_id字段上创建索引,这个我已经帮你们建了。
妹子连忙说感谢我......





新闻|Babelfish使PostgreSQL直接兼容SQL Server应用程序

更多新闻资讯,行业动态,技术热点,请关注中国PostgreSQL分会官方网站
https://www.postgresqlchina.com
中国PostgreSQL分会生态产品
https://www.pgfans.cn
中国PostgreSQL分会资源下载站
https://www.postgreshub.cn


点击此处阅读原文
↓↓↓
